Git inside and out
The ability to work inside a version control system is a skill that every programmer needs. Often it may seem that digging into Git and understanding its internals is an extra waste of time and basic tasks can be solved through a basic set of commands.
The AppsCast team, of course, wanted to learn more, and for advice on the practical application of all the features of Git, the guys turned to Yegor Andreyevich from Square.
Daniil Popov : Hello everyone. Today, Yegor Andreyevich from Square joined us.
Egor Andreyevich : Hello everyone. I live in Canada and work for Square, a software and hardware company for the financial industry. We started with terminals for accepting payments by credit cards, now we do services for business owners. I am working on a Cash App product. This is a mobile bank that allows you to exchange money with friends, order a debit card for payment in stores. The company has many offices around the world, and the Canadian office has about 60 programmers.
Daniil Popov : In the environment of android developers, Square is known for its open-source projects that have become industry standards: OkHttp, Picasso, Retrofit. It’s logical that developing such tools open to everyone, you work a lot with Git. We would like to talk about this.
Egor Andreevich : I have been using Git for a long time as a tool, and at some point it became interesting for me to learn more about it.
Git allows you to save files in a specific format. Each time you write a file, Git returns the key to your object - hash .
Daniil Popov : Many people noticed that the repository has a magic hidden directory .git . Why is it needed? Can I delete or rename it?
Egor Andreevich : Creating a repository is possible through the git init command. It creates the .git directory that Git uses to control files. .Git stores everything you do in your project, only in a compressed format. Therefore, you can restore the repository from this directory.
Alexei Kudryavtsev : It turns out that your project folder is one of the versions of the expanded Git folder?
Egor Andreevich : Depending on which branch you are on, git restores a project that you can work with.
Alexei Kudryavtsev : What is inside the folder?
Egor Andreevich : Git creates specific folders and files. The most important folder is .git / objects, where all the objects are stored. The simplest object is blob, essentially the same as a file, but in a format that git understands. When you want to save a text file in the repository, Git compresses it, archives it, adds data and creates a blob.
There are directories - these are folders with subfolders, i.e. Git has a tree object type that contains references to blob, to other trees.
When creating a commit, a link to the working directory is fixed - tree.
A commit is a link to a tree with information about who created it: email, name, creation time, link to parent (parent branch) and message. Git also compresses and writes commits to the object directory.
In order to see how all this works, you need to display a list of subdirectories from the command line.
Daniil Popov : How does Git work? Why is the action algorithm so complicated?
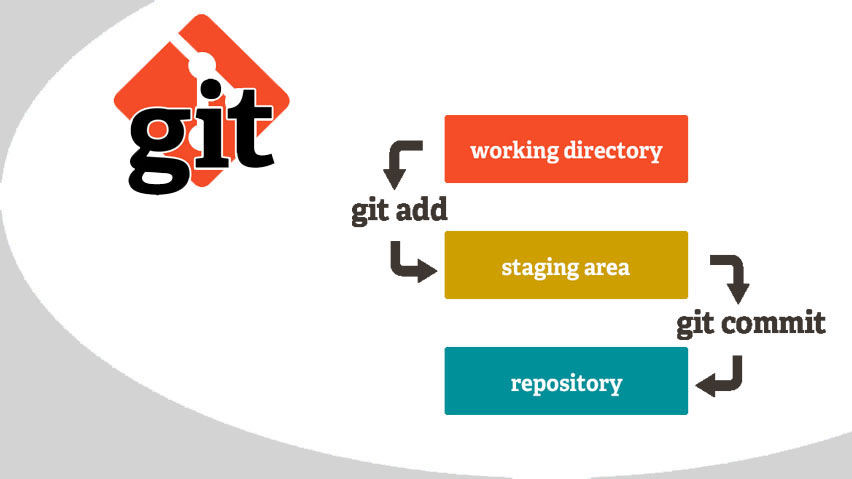
Egor Andreevich : If you compare Git with Subversion (SVN), then in the first system there are a number of functions that you need to understand. I'll start with the staging area , which should not be considered a limitation of Git, but rather features.
It is well known that when working with code, not everything goes right away: somewhere you need to change the layout, somewhere to fix bugs. As a result, after a work session, a number of affected files appear that are not interconnected. If you make all the changes in one commit, then it will be inconvenient, since the changes are different in nature. Then a series of commits comes to the output, which can be created just thanks to the staging area. For example, all changes to the layout file are sent to one series, for example, the fix of unit tests to another. We take several files, move them to the staging area and create a commit only with their participation. Other files from the working directory do not fall into it. Thus, you break down all the work carried out in the working directory into several commits, each of which represents a specific work.
Alexei Kudryavtsev : How is Git different from other version control systems?
Egor Andreevich : Personally, I started with SVN and then immediately switched to Git. Importantly, Git is a decentralized version control system. All copies of the Git repository are exactly the same. Each company has a server where the main version is located, but it is no different from the one that the developer has on the computer.
SVN has a central repository and local copies. This means that any developer can break the central repository alone.
In Git, this will not happen. If the central server loses the repository data, it can be restored from any local copy. Git is designed differently, and it offers the benefits of speed.
Daniil Popov : Git is famous for its branching, which runs noticeably faster than SVN. How does he do it?
Egor Andreevich : In SVN, a branch is a complete copy of the previous branch. There is no branch physical representation in Git. This is a link to the last commit in a specific development line. When Git saves objects, when creating a commit, it creates a file with certain information about the commit. Git creates a symbolic file - symlink with a link to another file. When you have many branches, then you refer to different commits in the repository. To track the history of a branch, you need to go from each commit using the link back to the parent commit.
Daniil Popov : There are two ways to merge two branches into one - this is merge and rebase. How do you use them?
Egor Andreevich : Each method has its own advantages and disadvantages. Merge is the easiest option. For example, there are two branches: master and the feature selected from it.
For merge, you can use fast forward. This is possible if from the moment work was started in the feature branch, no new commits were made in master. That is, the first commit in feature is the last commit in master.
In this case, the pointer is fixed on the master branch and moves to the most recent commit in the feature branch. In this way, branching is eliminated by connecting the feature branch to the main master thread and removing the unnecessary branch. The result is a linear history where all commits follow each other. In practice, this option happens infrequently, because constantly someone merges commits into master.
It can be otherwise. Git creates a new commit - merge commit, which has two references to parent commits: one in master, the other in feature. With the new commit, two branches are connected and feature can be deleted again.
After the merge commit, you can look at the story and see that it is bifurcated. If you use a tool that graphically renders commits, then visually it will look like a Christmas tree. This does not break Git, but it’s difficult for a developer to watch such a story.
Another tool is rebase . Conceptually, you take all the changes from the feature branch and flip them over the master branch. The first feature commit becomes the new commit on top of the latest master commit.
There is a catch - Git cannot change commits. There was a commit in feature and we can’t just wrap it over master, as each commit has a time stamp.
In the case of rebase, Git reads all the commits in feature, temporarily saves it, and then re-creates it in the same order in master. After rebase, the initial commits disappear, and new commits with the same content appear on top of master. There are problems. When you try to rebase a branch that other people work with, you can break the repository. For example, if someone started their branch from a commit that was in feature, and you destroyed and recreated that commit. Rebase is more suitable for local branches.
Daniil Popov : If you introduce restrictions that strictly one person works on one feature branch, agree that you cannot buddy one feature branch from another, then this problem does not arise. But what approach do you practice?
Egor Andreevich : We do not use feature branches in the direct sense of this term. Each time we make a change, create a new branch, work in it and immediately pour it into master. There are no long-playing branches.
This solves a large number of problems with merge and rebase, especially conflicts. Branches exist for one hour and there is a high probability of using fast forward, since no one added anything to master. When we do merge in pull request, then only merge with creation of merge commit
Daniil Popov : How are you not afraid to merge a master idle feature, because decomposing a task into hourly intervals is often unrealistic?
Egor Andreevich : We use the feature flags approach. These are dynamic flags, a specific feature with different states. For example, the function of sending payments to each other is either turned on or off. We have a service that dynamically delivers this state to customers. You from the server get the value off feature or not. You can use this value in the code - turn off the button that goes to the screen. The code itself is in the application, and it can be released, but there is no access to this functionality, because it is behind the feature flag.
Daniil Popov : Often, newcomers to Git are told that after rebase you need to push with force. Where is it from?
Egor Andreevich : When you just push, another repository may throw an error: you are trying to start a branch, but you have completely different commits on this branch. Git checks all the information so that you don't accidentally break the repository. When you say git push force , then turn off this check, believing that you know better than him, and demand to rewrite the branch.
Why is this needed after rebase? Rebase re-creates commits. It turns out that the branch is also called, but commits in it with other hashes, and Git swears at you. In this situation, it is absolutely normal to do a force push, since you are in control of the situation.
Daniil Popov : There is still the concept of interactive rebase , and many are afraid of it.
Egor Andreevich : There is nothing terrible. Due to the fact that Git recreates the story during rebase, it temporarily stores it before throwing it. When it has temporary storage, it can do anything with commits.
Rebase in interactive mode assumes that Git before rebase pops up a text editor window in which you can specify what needs to be done with each individual commit. It looks like several lines of text, where each line is one of the commits that are in the branch. Before each commit, there is an indication of the operation that is worth performing. The simplest default operation is pick , i.e. to take and include in rebase. The most common is squash , then Git will take the changes from this commit and merge it with the changes from the previous one.
Often there is such a scenario. You worked locally in your branch and created commits for the save. The result is a long history of commits, which is interesting for you, but in the same way it should not be poured into the main history. Then you give squash to rename to the general commit.
The list of teams is long. You can throw the commit - drop and it disappears, you can change the commit message, etc.
Alexei Kudryavtsev : When you have conflicts in interactive rebase, you go through all the circles of hell.
Egor Andreevich : I am very far from comprehending all the wisdom of interactive rebase, but it is a powerful tool and complex.
Daniil Popov : Let's move on to practice. At the interview, I often ask: “You have a thousand commits. On the first all is well, on the thousandth test broke. How can you find the change that led to this with the help of a gita? ”
Egor Andreevich : In this situation, you need to use bisect , although it is easier to take blame.
Let's start with the interesting one. Git bisect is applicable to a situation where you have regression - it was functional, worked, but suddenly stopped. To find when the functionality has broken, you can theoretically randomly roll back to the previous version of the application, look at the code, but there is a tool that will allow you to structured approach the problem.
Git bisect is an interactive tool. There is a git bisect bad command through which you report on the presence of a broken commit and git bisect good - for a working commit. Each time the application is released, we remember the hash of the commit from which the release was made. This hash can also be used to indicate bad and good commits. Bisect receives information about the interval where one of the commits broke the functionality, and starts the binary search session, where it gradually issues commits to check whether they work or not.
You started the session, Git switches to one of the commits in the interval, reports this. In the case of a thousand commits, there will not be many iterations.
The verification will have to be done manually: through unit tests or run the application and click manually. Git bisect is conveniently scriptable. Each time he issues a commit, you give him a script for verifying that the code is working.
Blame is a simpler tool that, based on its name, allows you to find the "culprit" of a functional failure. Due to this negative definition, many in the blame community don't like it.
What is he doing? If you give git blame a specific file, then it linearly in this file will show which commit changed this or that line. I have never used git blame from the command line. As a rule, this is done in IDEA or Android Studio - click and see who changed which line of the file and in which commit.
Daniil Popov : By the way, in Android Studio it was called Annotate. Removed the negative connotation of blame.
Alexei Kudryavtsev : Exactly, in xCode they renamed it Authors.
Egor Andreevich : I also read that there is a utility git praise - to find the one who wrote this excellent code.
Daniil Popov : It should be noted that on blame suggestions of reviewers on pull request work. He looks at who touched a particular file most of all, and suggests that this person will be able to well review your code.
In the case of the example about a thousand commits, blame in 99% of cases will show what went wrong. Bisect is already the last resort.
Egor Andreevich : Yes, I resort to bisect extremely rarely, but I use annotate regularly. Although sometimes it’s not possible to understand from the line of code why there is null checked, it is clear throughout the commit what the author wanted to do.
Daniil Popov : I heard that Square uses Stacked pull requests (PRs).
Egor Andreevich : At least in our android team we often use them.
We devote a lot of time to making each pull request easy to review. Sometimes there is a temptation to feed, quickly feed, and let the reviewers understand. We try to create small pull requests and a short description - the code should speak for itself. When pull requests are small, it's easy and quick to bawl.
This is where the problem arises. You are working on a feature that will require a large number of changes in the code base. What can you do? You can put it in one pull request, but then it will be huge. You can work by gradually creating a pull request, but then the problem will be that you created a branch, added a few changes and submitted a pull request, returned to master and the code that you had in pull request is not available in master until merge will not happen. If you are dependent on changes in these files, it is difficult to continue working because there is no such code.
How do we get around this? After we created the first pull request, we continue to work, create a new branch from the existing branch, which we used before the pull request. Each branch comes not from master, but from the previous branch. When we finish work on this piece of functionality, we submit another pull request and again indicate that with merge it merges not in master, but in the previous branch. It turns out such a chain of pull requests - stacked prs. When a person revises, he sees the changes that were made only by this feature, but not the previous one.
The task is to make each pull request as small and clear as possible so that there is no need to change. Because if you have to change the code in the branches that are in the middle of stacked, everything on top will break, because you have to do rebase. If pull requests are small, we try to freeze them as soon as possible, then all stacked merges step by step into master.
Daniil Popov : I understand correctly that in the end there will be some last pull request, which contains all the small pull requests. You pour this thread without looking?
Egor Andreevich : Merge comes from the source stacked: first, the very first pull request is merged in master, in the next, the base changes from the branch to master and, accordingly, Git calculates that there are already some changes in master, less snapshot.
Alexei Kudryavtsev : Do you have a race condition when the first branch has already frozen, and only after that the second one has stopped in the first because it hasn’t been changed target to master?
Egor Andreevich : We hold it by hand, so there are no such situations. I open a pull request, note the colleagues from whom I want to get a review, and when they are ready, go to bitbucket, press merge.
Alexei Kudryavtsev : But what about checks on CI that nothing is broken?
Egor Andreevich : We do not do this. CI , pull request base. , .
: master develop? , ?
: develop, master. . , - - master, . tags — - . - — -, , . , Git , .
: Git, ?
: Git . , , . , . StackOverflow . .
The AppsCast team, of course, wanted to learn more, and for advice on the practical application of all the features of Git, the guys turned to Yegor Andreyevich from Square.
Daniil Popov : Hello everyone. Today, Yegor Andreyevich from Square joined us.
Egor Andreyevich : Hello everyone. I live in Canada and work for Square, a software and hardware company for the financial industry. We started with terminals for accepting payments by credit cards, now we do services for business owners. I am working on a Cash App product. This is a mobile bank that allows you to exchange money with friends, order a debit card for payment in stores. The company has many offices around the world, and the Canadian office has about 60 programmers.
Daniil Popov : In the environment of android developers, Square is known for its open-source projects that have become industry standards: OkHttp, Picasso, Retrofit. It’s logical that developing such tools open to everyone, you work a lot with Git. We would like to talk about this.
What is git
Egor Andreevich : I have been using Git for a long time as a tool, and at some point it became interesting for me to learn more about it.
Git is a simplified file system, on top of which is a set of operations for working with version control.
Git allows you to save files in a specific format. Each time you write a file, Git returns the key to your object - hash .
Daniil Popov : Many people noticed that the repository has a magic hidden directory .git . Why is it needed? Can I delete or rename it?
Egor Andreevich : Creating a repository is possible through the git init command. It creates the .git directory that Git uses to control files. .Git stores everything you do in your project, only in a compressed format. Therefore, you can restore the repository from this directory.
Alexei Kudryavtsev : It turns out that your project folder is one of the versions of the expanded Git folder?
Egor Andreevich : Depending on which branch you are on, git restores a project that you can work with.
Alexei Kudryavtsev : What is inside the folder?
Egor Andreevich : Git creates specific folders and files. The most important folder is .git / objects, where all the objects are stored. The simplest object is blob, essentially the same as a file, but in a format that git understands. When you want to save a text file in the repository, Git compresses it, archives it, adds data and creates a blob.
There are directories - these are folders with subfolders, i.e. Git has a tree object type that contains references to blob, to other trees.
Basically, one tree is a snapshot that describes the state of your directory at a specific point.
When creating a commit, a link to the working directory is fixed - tree.
A commit is a link to a tree with information about who created it: email, name, creation time, link to parent (parent branch) and message. Git also compresses and writes commits to the object directory.
In order to see how all this works, you need to display a list of subdirectories from the command line.
Benefits of Working with Git
Daniil Popov : How does Git work? Why is the action algorithm so complicated?
Egor Andreevich : If you compare Git with Subversion (SVN), then in the first system there are a number of functions that you need to understand. I'll start with the staging area , which should not be considered a limitation of Git, but rather features.
It is well known that when working with code, not everything goes right away: somewhere you need to change the layout, somewhere to fix bugs. As a result, after a work session, a number of affected files appear that are not interconnected. If you make all the changes in one commit, then it will be inconvenient, since the changes are different in nature. Then a series of commits comes to the output, which can be created just thanks to the staging area. For example, all changes to the layout file are sent to one series, for example, the fix of unit tests to another. We take several files, move them to the staging area and create a commit only with their participation. Other files from the working directory do not fall into it. Thus, you break down all the work carried out in the working directory into several commits, each of which represents a specific work.
Alexei Kudryavtsev : How is Git different from other version control systems?
Egor Andreevich : Personally, I started with SVN and then immediately switched to Git. Importantly, Git is a decentralized version control system. All copies of the Git repository are exactly the same. Each company has a server where the main version is located, but it is no different from the one that the developer has on the computer.
SVN has a central repository and local copies. This means that any developer can break the central repository alone.
In Git, this will not happen. If the central server loses the repository data, it can be restored from any local copy. Git is designed differently, and it offers the benefits of speed.
Daniil Popov : Git is famous for its branching, which runs noticeably faster than SVN. How does he do it?
Egor Andreevich : In SVN, a branch is a complete copy of the previous branch. There is no branch physical representation in Git. This is a link to the last commit in a specific development line. When Git saves objects, when creating a commit, it creates a file with certain information about the commit. Git creates a symbolic file - symlink with a link to another file. When you have many branches, then you refer to different commits in the repository. To track the history of a branch, you need to go from each commit using the link back to the parent commit.
Merjim branches
Daniil Popov : There are two ways to merge two branches into one - this is merge and rebase. How do you use them?
Egor Andreevich : Each method has its own advantages and disadvantages. Merge is the easiest option. For example, there are two branches: master and the feature selected from it.
For merge, you can use fast forward. This is possible if from the moment work was started in the feature branch, no new commits were made in master. That is, the first commit in feature is the last commit in master.
In this case, the pointer is fixed on the master branch and moves to the most recent commit in the feature branch. In this way, branching is eliminated by connecting the feature branch to the main master thread and removing the unnecessary branch. The result is a linear history where all commits follow each other. In practice, this option happens infrequently, because constantly someone merges commits into master.
It can be otherwise. Git creates a new commit - merge commit, which has two references to parent commits: one in master, the other in feature. With the new commit, two branches are connected and feature can be deleted again.
After the merge commit, you can look at the story and see that it is bifurcated. If you use a tool that graphically renders commits, then visually it will look like a Christmas tree. This does not break Git, but it’s difficult for a developer to watch such a story.
Another tool is rebase . Conceptually, you take all the changes from the feature branch and flip them over the master branch. The first feature commit becomes the new commit on top of the latest master commit.
There is a catch - Git cannot change commits. There was a commit in feature and we can’t just wrap it over master, as each commit has a time stamp.
In the case of rebase, Git reads all the commits in feature, temporarily saves it, and then re-creates it in the same order in master. After rebase, the initial commits disappear, and new commits with the same content appear on top of master. There are problems. When you try to rebase a branch that other people work with, you can break the repository. For example, if someone started their branch from a commit that was in feature, and you destroyed and recreated that commit. Rebase is more suitable for local branches.
Daniil Popov : If you introduce restrictions that strictly one person works on one feature branch, agree that you cannot buddy one feature branch from another, then this problem does not arise. But what approach do you practice?
Egor Andreevich : We do not use feature branches in the direct sense of this term. Each time we make a change, create a new branch, work in it and immediately pour it into master. There are no long-playing branches.
This solves a large number of problems with merge and rebase, especially conflicts. Branches exist for one hour and there is a high probability of using fast forward, since no one added anything to master. When we do merge in pull request, then only merge with creation of merge commit
Daniil Popov : How are you not afraid to merge a master idle feature, because decomposing a task into hourly intervals is often unrealistic?
Egor Andreevich : We use the feature flags approach. These are dynamic flags, a specific feature with different states. For example, the function of sending payments to each other is either turned on or off. We have a service that dynamically delivers this state to customers. You from the server get the value off feature or not. You can use this value in the code - turn off the button that goes to the screen. The code itself is in the application, and it can be released, but there is no access to this functionality, because it is behind the feature flag.
Daniil Popov : Often, newcomers to Git are told that after rebase you need to push with force. Where is it from?
Egor Andreevich : When you just push, another repository may throw an error: you are trying to start a branch, but you have completely different commits on this branch. Git checks all the information so that you don't accidentally break the repository. When you say git push force , then turn off this check, believing that you know better than him, and demand to rewrite the branch.
Why is this needed after rebase? Rebase re-creates commits. It turns out that the branch is also called, but commits in it with other hashes, and Git swears at you. In this situation, it is absolutely normal to do a force push, since you are in control of the situation.
Daniil Popov : There is still the concept of interactive rebase , and many are afraid of it.
Egor Andreevich : There is nothing terrible. Due to the fact that Git recreates the story during rebase, it temporarily stores it before throwing it. When it has temporary storage, it can do anything with commits.
Rebase in interactive mode assumes that Git before rebase pops up a text editor window in which you can specify what needs to be done with each individual commit. It looks like several lines of text, where each line is one of the commits that are in the branch. Before each commit, there is an indication of the operation that is worth performing. The simplest default operation is pick , i.e. to take and include in rebase. The most common is squash , then Git will take the changes from this commit and merge it with the changes from the previous one.
Often there is such a scenario. You worked locally in your branch and created commits for the save. The result is a long history of commits, which is interesting for you, but in the same way it should not be poured into the main history. Then you give squash to rename to the general commit.
The list of teams is long. You can throw the commit - drop and it disappears, you can change the commit message, etc.
Alexei Kudryavtsev : When you have conflicts in interactive rebase, you go through all the circles of hell.
Egor Andreevich : I am very far from comprehending all the wisdom of interactive rebase, but it is a powerful tool and complex.
Practical Git Application
Daniil Popov : Let's move on to practice. At the interview, I often ask: “You have a thousand commits. On the first all is well, on the thousandth test broke. How can you find the change that led to this with the help of a gita? ”
Egor Andreevich : In this situation, you need to use bisect , although it is easier to take blame.
Let's start with the interesting one. Git bisect is applicable to a situation where you have regression - it was functional, worked, but suddenly stopped. To find when the functionality has broken, you can theoretically randomly roll back to the previous version of the application, look at the code, but there is a tool that will allow you to structured approach the problem.
Git bisect is an interactive tool. There is a git bisect bad command through which you report on the presence of a broken commit and git bisect good - for a working commit. Each time the application is released, we remember the hash of the commit from which the release was made. This hash can also be used to indicate bad and good commits. Bisect receives information about the interval where one of the commits broke the functionality, and starts the binary search session, where it gradually issues commits to check whether they work or not.
You started the session, Git switches to one of the commits in the interval, reports this. In the case of a thousand commits, there will not be many iterations.
The verification will have to be done manually: through unit tests or run the application and click manually. Git bisect is conveniently scriptable. Each time he issues a commit, you give him a script for verifying that the code is working.
Blame is a simpler tool that, based on its name, allows you to find the "culprit" of a functional failure. Due to this negative definition, many in the blame community don't like it.
What is he doing? If you give git blame a specific file, then it linearly in this file will show which commit changed this or that line. I have never used git blame from the command line. As a rule, this is done in IDEA or Android Studio - click and see who changed which line of the file and in which commit.
Daniil Popov : By the way, in Android Studio it was called Annotate. Removed the negative connotation of blame.
Alexei Kudryavtsev : Exactly, in xCode they renamed it Authors.
Egor Andreevich : I also read that there is a utility git praise - to find the one who wrote this excellent code.
Daniil Popov : It should be noted that on blame suggestions of reviewers on pull request work. He looks at who touched a particular file most of all, and suggests that this person will be able to well review your code.
In the case of the example about a thousand commits, blame in 99% of cases will show what went wrong. Bisect is already the last resort.
Egor Andreevich : Yes, I resort to bisect extremely rarely, but I use annotate regularly. Although sometimes it’s not possible to understand from the line of code why there is null checked, it is clear throughout the commit what the author wanted to do.
How to work with Stacked PRs?
Daniil Popov : I heard that Square uses Stacked pull requests (PRs).
Egor Andreevich : At least in our android team we often use them.
We devote a lot of time to making each pull request easy to review. Sometimes there is a temptation to feed, quickly feed, and let the reviewers understand. We try to create small pull requests and a short description - the code should speak for itself. When pull requests are small, it's easy and quick to bawl.
This is where the problem arises. You are working on a feature that will require a large number of changes in the code base. What can you do? You can put it in one pull request, but then it will be huge. You can work by gradually creating a pull request, but then the problem will be that you created a branch, added a few changes and submitted a pull request, returned to master and the code that you had in pull request is not available in master until merge will not happen. If you are dependent on changes in these files, it is difficult to continue working because there is no such code.
How do we get around this? After we created the first pull request, we continue to work, create a new branch from the existing branch, which we used before the pull request. Each branch comes not from master, but from the previous branch. When we finish work on this piece of functionality, we submit another pull request and again indicate that with merge it merges not in master, but in the previous branch. It turns out such a chain of pull requests - stacked prs. When a person revises, he sees the changes that were made only by this feature, but not the previous one.
The task is to make each pull request as small and clear as possible so that there is no need to change. Because if you have to change the code in the branches that are in the middle of stacked, everything on top will break, because you have to do rebase. If pull requests are small, we try to freeze them as soon as possible, then all stacked merges step by step into master.
Daniil Popov : I understand correctly that in the end there will be some last pull request, which contains all the small pull requests. You pour this thread without looking?
Egor Andreevich : Merge comes from the source stacked: first, the very first pull request is merged in master, in the next, the base changes from the branch to master and, accordingly, Git calculates that there are already some changes in master, less snapshot.
Alexei Kudryavtsev : Do you have a race condition when the first branch has already frozen, and only after that the second one has stopped in the first because it hasn’t been changed target to master?
Egor Andreevich : We hold it by hand, so there are no such situations. I open a pull request, note the colleagues from whom I want to get a review, and when they are ready, go to bitbucket, press merge.
Alexei Kudryavtsev : But what about checks on CI that nothing is broken?
Egor Andreevich : We do not do this. CI , pull request base. , .
: master develop? , ?
: develop, master. . , - - master, . tags — - . - — -, , . , Git , .
: Git, ?
: Git . , , . , . StackOverflow . .
Saint AppsConf Git . Introductory, . Avito : , 2019 .
AppsCast , , SoundCloud , .
All Articles