How to create a model more precisely than transfermarkt and not predict or what affects the cost of transfers most of all
I will try to tell you how easy it is to get interesting results by simply applying a completely standard approach from the tutorial of the machine learning course to the data that is not the most used in Deep Learning. The essence of my post is that each of us can do this, you just need to look at the array of information that you know well. To do this, in fact, it is much more important to simply understand your data well than to be an expert in the latest structures of neural networks. That is, in my opinion, we are at that golden point in the development of DL, when on the one hand it is already a tool that you can use without the need to be a PhD, and on the other there are still a lot of areas where no one really used it, if you look A little further than traditional topics.

Reading articles and in passing looking at how machine learning develops, you and I can easily get the feeling that this train is passing by. Indeed, if you take the most famous courses (for example, Andrew Ng ) or most of the articles on Habré from the same excellent community of Open Data Science, you very quickly realize that there is nothing to do here from the depths of the memory of institute knowledge in higher mathematics, well, at least some sane results (even in ' toy ' examples) can be achieved only after several weeks of studying terry theory and different ways of its implementation. But often you want another, you want to have a tool that performs its function, which solves a certain class of problems, so that, applying it in your field, get the result. Indeed, in other areas everything is exactly so, if you, for example, write a game and your task is to ensure the transfer of information from the player to the server, then you do not study the theory of graphs, do not figure out how to optimize the connectivity so that your packets reach faster - you take the tool (library, framework) that does this for you and focus on what is unique to a particular task (for example, what kind of information you need to transfer back and forth). Why is this not so for deep learning?
In fact, now we are on the verge of the time when it is becoming almost like that . And for myself, I almost found that tool - fast.ai. An excellent library and an even steeper course, the whole principle of which is just built “top-down”: first solving real problems, often at the level of accuracy of prediction of State Of The Art-models, down to the internal structure of the library and the theory behind it.
Anticipating accusations of unprofessionalism and the superficiality of my knowledge (which, of course, is more true than not), I want to make a reservation right away. Is it necessary to study the theory, watch those very fundamental lectures, remember the matrix calculus, etc.? Of course it is. And the further you plunge into the topic, the more you will need it and have to cling to the primary sources. But the more conscious the immersion will be, the easier it will be to understand how exactly these very fundamentals affect the result. The whole point of the top-down principle is precisely that it must be done after. After you have already written something tangible that you can show your friends. After you have plunged enough into the topic and it has fascinated you. And the theory in the know will overtake you, it just comes at the very moment when it will be easier for you to correlate it with what you have already done. As an explanation of why and how it actually works.
I am more than sure that someone is more comfortable with the traditional bottom-up approach. And it’s good that there are both ways, the main thing is that we meet in the middle
With about such a set of knowledge, I decided to apply DL to a topic that I myself have long been interested in and see what it can lead to. And, of course, the first thing that came to my mind was football. And when I found this wonderful transfer statistics on kaggle, the choice became all the more obvious.
A little about this data. They contain information about who and where has moved to European football over the past 10 years. There is information about clubs, statistics of players, leagues in which they participate, coaches and agents, and much more (there are more than a hundred different fields in total). The data is very interesting, but is it possible to determine how much a player should cost from them?
If you think about it, the price of a player depends on a huge number of factors. At the same time, it’s great, and I (if not most) their part is simply non-formalizable. How to understand that the club has just sold the player at a high price, needs an attacker and is quite ready to overpay for it; how to understand that a new coach has come and requires updating the roster; how to understand that the main defender of the club noticed the grand and he began to play half-heartedly, demanding a transfer? All this fundamentally affects the amount of a transaction, but is not presented in the data. From that, my initial expectations about the accuracy of such a forecast were small.
At this point, it’s time to insert the standard disclaimer that #
not a #
, I don’t make money from it, so my code is terrible, and most likely it can (and should?) Be rewritten much better, but since the task was to explore the idea and (not ?) Confirm the theory, then the code is what it is :)
Model
I began by excluding transfers cheaper than $ 1 million, which are too chaotic. Then he brought all the data into one big table with one and a half hundred fields, in which for each transfer there was all the information available about him (both about the transfer itself, the player and his statistics, as well as about the clubs participating in it, leagues, etc. )
Let's look at the steps how I created the model :
After we have completed all the Python imports and loaded the denormalized transfer table, the first thing we need to determine is which of the fields we will consider as numeric and which are categorical. This is a very interesting topic in itself, you can talk about it in the comments, but to save time, I just describe the rule that I use: I, by default, consider all fields categorical, except those that are represented as floating-point numbers or those where the number of different values is large enough.
In this context, for example, “the year of transfer” I consider categorical, although this is initially a number, because the number of different values here is small (10 - from 2008 to 2018). But, for example, the player’s performance in the last season (which is represented by the average number of his goals per match) is a float and can take almost any value, so I consider it numerical.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
Then, after explicitly indicating what we will predict - the transfer amount ( fee
), we randomly divide our data into 2 parts of 80% and 20%. On the first of them we will teach our neural network, on the other - to check the accuracy of the prediction.
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
At the last preparatory stage, we need to make a choice how we will measure the plausibility of our predictions. Then I chose not the most standard metric in the local part of the universe - the Median of the percent error ( MdAPE
). Or, more simply, how many percent (the absolute price of a transfer can differ by orders of magnitude) most likely we will make a mistake in the price of a randomly taken transfer. It seemed to me closest to what the phrase 'accuracy of the transfer prediction system' means to me.
Now is the time to actually start learning the network.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
Prediction accuracy

Validation Error = 0.3492
means that after training on a new ( validation set
, validation set
) data set, the model on average (median) is 34% mistaken relative to the real transfer price. And we did it only as a result of several lines of code taken from the tutorial.
34% error, is it a lot or a little? Everything is relative. The only comparable source, the data of which can be taken as a “ prediction ” of the transfer amount, is, of course, transfermarkt . Fortunately, there is a field in the data from kaggle that shows how this site rated this or that player at the time of transfer, and this can be compared. It should be noted here that transfermarkt never claimed that their market value
was the likely transfer price. On the contrary, they emphasized that it was rather the “ honest value ” of one or another player. And how much money a particular club will pay for it in a particular situation is a very individual thing and can fluctuate in one direction or another over a wide range. But this is the best we have, let's compare .

Transfermarkt error - 35% , our model - 35% . Very strange and, to be honest, very suspicious.
At this point, I propose to think again. A site with a huge history, created just to show the 'value' of players, which relies on the full power of the crowd effect (it derives value from the ratings of both ordinary visitors and market professionals) and the knowledge of experts on the one hand, and the model, which knows nothing about football, sees nothing except the data that we gave it (and outside of these data in the real world there are still a lot of things that people with transfermarkt take into account) on the other, they show the same error . Moreover, our model also allows predicting the player’s rental price, which the market value
, for obvious reasons, does not show (taking into account such transactions, the result of transfermarkt was even worse ).
Honestly, I still think that I have some kind of mistake here, everything is too good to be true. But, nevertheless, let's go further.
An easy way to test yourself is to try to average the predictions from 2 sources (models and transfermarkt). If the predictions are truly independent from each other and there is no annoying mistake, then the result should improve.

Indeed, averaging forecasts reduces the prediction error to 32% (!). This may seem a little, but we must understand that we are filtering some more information from the data, which is so squeezed to the maximum.
But what we will do next, in my opinion, is even more surprising and interesting, although it is beyond the scope of the fast.ai tutorial .
Feature importance
Neural networks, not to say that it’s completely undeserved, are often considered a “black box”. We know what data we can put there, we can get the predictions of the model, we can even assess how much its predictions are true on average. But we cannot explain by what criteria the model “made” this or that decision. The internal structure of the network itself is so complex, and more importantly, non-linear, that it’s impossible to directly trace the entire decision-making chain and draw conclusions that are significant in the real world from there. But really want to. I'd like to understand what affects the transfer amount most of all.
Well, we won’t climb inside the network. But what does the importance of each field mean, call it Feature Importance (FI)? One option to understand 'importance' is to calculate how much things will get worse if we didn't have this field. And this is precisely what we can measure. We now have a tool that provides predictions on any data set. So, if we just calculate how much the prediction error will increase when we substitute random data in the field, then we can just estimate how much it (the field) affects the final result, which means how important it is. To remain within the real distribution of data, the field will be filled not just with random numbers, but with randomly mixed values of it (that is, we will just mix the column, for example, 'year of transfer', in the original table). For fidelity, this process can be carried out several times for each field by averaging the result. Everything is quite simple. Now let's see how sane this gives the result:
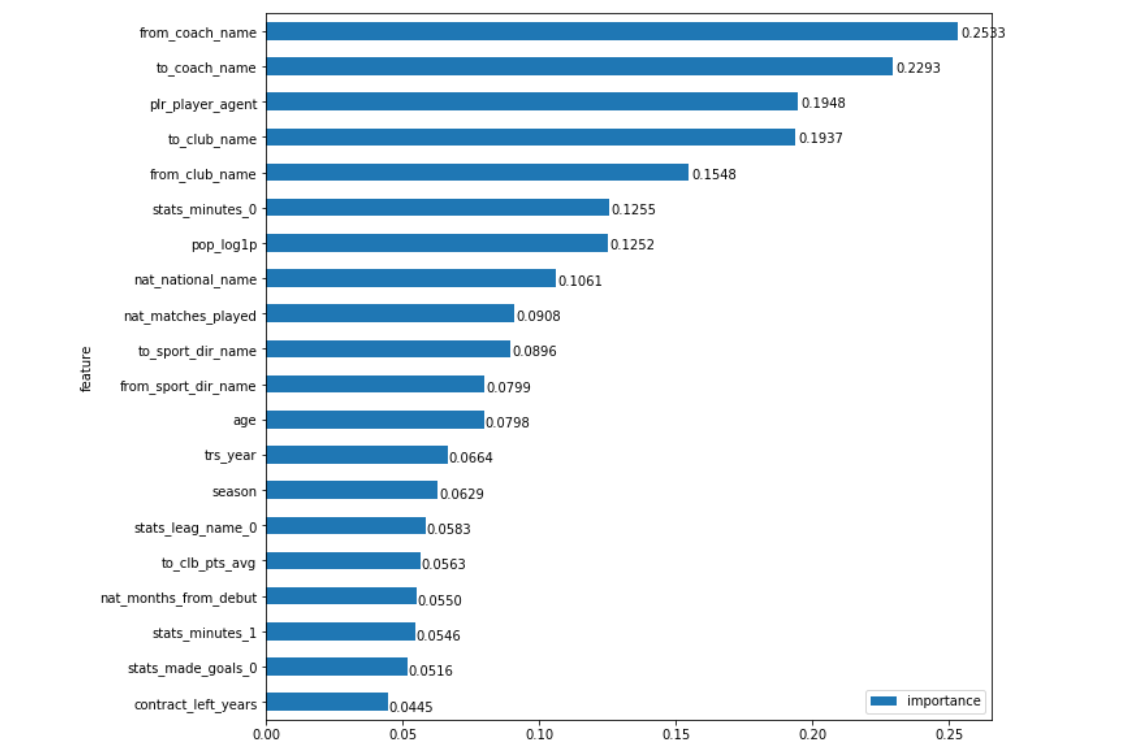
My gut says: 'Yes and no!'
On one side, the fields that you expect to see there were on top: team coaches from where and where from_coach_name
player go ( from_coach_name
, to_coach_name
), the clubs themselves participating in the transfer ( from_club_name
, to_club_name
), the player’s agent ( plr_player_agent
), his fame in social networks ( pop_log1p
) etc. But on the other hand ... Intuitively, it does not seem that the names of coaches should have more weight in the transfer price than, for example, the clubs themselves (we know well that conditional Benfica can sell her players expensive). Is the brand of a coach more influential in price than the brand of the club. Is the arrival of the conditional Mancini so much forcing the club to overpay? What is it, the case when the data gives us new, slightly counterintuitive, information or just an error in the model?
Let's get it right. With a close look at the chart, the eye quickly clings to a strange thing. Just below the center there are 2 trs_year
and season
fields trs_year
, they represent the year of the transfer and the season in which the transition will be carried out (in the general case, they may not coincide, although this does not happen so often). Firstly, it seems that they should be higher, we know how much prices for football players have risen in recent years, and secondly, they obviously mean about the same thing. What to do about it? Just summarize their importance? Not the fact that this can be done! But what we can definitely do is apply the same approach (mixing values) not separately to these two fields, but as a group. That is, measure how the error will change if there are random values in 2 of these columns at once. Well, since we have been doing this over the years, we need to see if we have other fields that are just as 'connected'.
For example, for a club, we have several parameters: the club itself ( club_name
), as well as a set of information about it - from which league, country, etc. ( club_is_first_team
, clb_lg_name
, clb_lg_country
, clb_lg_group
). Only in some cases we are interested in knowing how much it affects the price, for example, the country the player goes to separately ( clb_lg_country
), most often it is important for us to understand what the total weight of the 'club' field is, which is already in a certain country, league, etc. .
Thus, we can combine all the fields into groups according to the semantic content. This will help us as simply knowledge of the subject area and common sense, as well as the calculated 'proximity' of features. The latter just shows how the fields correlate with each other, that is, how much it is possible to consider them as a single group.
Applying this approach, we obtain an even more intuitive graph of the importance of fields:
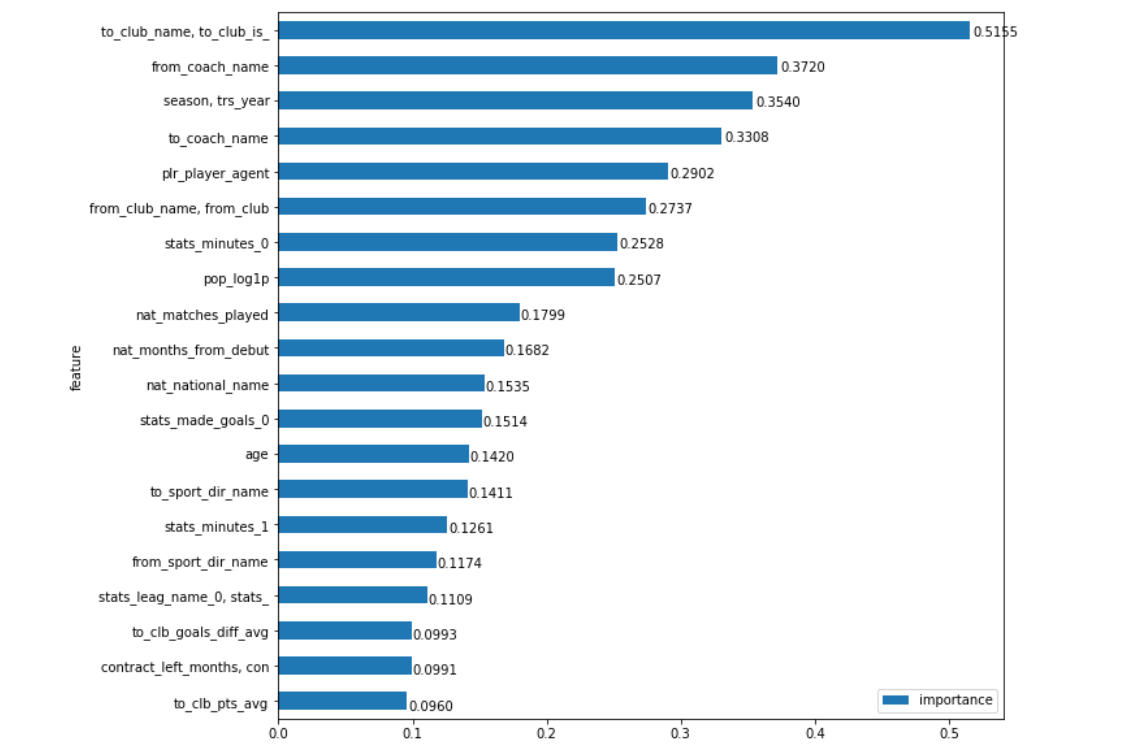
Like this. Exactly what club the player buys the most affects the transfer amount, with a very good margin. Hi Man City, Barcelona, Zenit and, for example, the same Benfica (after all, “ strongly influences ” it is also the fact that some clubs, on the contrary, are able to buy quality players cheaper than the “market”). It seems to me that the most interesting thing in working with data is that when it is obtained, the conclusions are obvious on the one hand (well, I doubted that the club-buyer had the most powerful influence on the transfer amount), and on the other hand, it’s a bit surprising (and the candidates for the first the place, intuitively, could be somewhat, and the separation from the second did not seem so significant)
There is still a lot of interesting things to discover. For example, the name of the coach from where the player is bought, from the point of view of the model, is still more important than the club ... Let the difference be greatly reduced. A logical explanation for this can be found in principle (although sometimes it can be found for anything). There are coaches (Guardiola, Klopp, Benitez, Berdyev) who adhere to a certain ideology of the game in different clubs, which better reveals or vice versa makes certain positions on the field less bright, and the visibility of the player greatly affects its price. About clubs, so to speak, almost impossible. And the fact that we see coaches who are not radically departing from their principles of the game much more often than clubs that change coaches, but remain within the same philosophy (so, offhand, except that Ajax comes to mind, and Barcelona is very questionable), speaks of that perhaps certain managers reveal players more stable than clubs. Although here I would not strongly hold on to my statement.
Of purely statistical indicators, the highest amount is simply the amount of time a player spent on the field last year in his main competition ( stats_minutes_0
). This is exactly logical, because how much this player was the “main” in his club last season seems to be a more universal statistical indicator of his success than others - for example, the number of goals scored or cards received.
Player popularity ( pop_log1p
) closes this group of 8 most important parameters. Here it is worth recalling that the data we have presented for the last 10 years. I think that the importance of this field would be higher if we were considering the last 5 years, and for the average value over the last decade this is an understandable result, especially considering the gap from the next place.
Well, the last thing I would like to draw attention to is the importance of the agent field ( plr_player_agent
). I will leave this without comment, because if you can break the margins of copies in disputes about the (un) need of agents, then there is no doubt about the degree of their influence on the modern transfer market (although the model suggests not to overestimate it).

By the way, perhaps the most interesting thing in this method of analysis is its accessibility: it is not necessary to create an “ ideal ” model in order to obtain information about the importance of parameters. In many cases, it’s enough that it simply predicts at the very least, is statistically significantly different from a coin toss, and you’ll already get results that often contain interesting insights or tell you which side you can look at the data from.
Then it’s time to round off, so as not to increase so overloaded text. In parting, I would like to once again urge all those interested in the topic to try out (the best, in my opinion, for beginners) the Deep Learning course - fast.ai and apply the knowledge gained in 'your field of expertise', it is likely you will be there first :)
And if you like it, I’ll try to master the second part of the text about my experiments in which the model using an equally powerful tool - Partial Dependency will tell you: which agency’s client is best to become a football player, which clubs have the most effective transfer policy, which coach best increases the cost of players (in addition to the obvious candidates, there are many not-so-promoted 'brands' that are clearly worth a closer look) and much more.
All Articles