The use of Siamese neural networks in the search
Hello! In this post I will tell you which approaches we use in Mail.ru Search to compare texts. What is it for? As soon as we learn how to compare different texts well with each other, the search engine will be able to better understand user requests.
What do we need for this? To begin with, strictly set the task. It is necessary to determine for ourselves which texts we consider similar and which we do not consider, and then formulate a strategy for automatically determining similarity. In our case, the texts of user queries will be compared with the texts of documents.
The task of determining text relevance consists of three stages. First, the simplest: look for matching words in two texts and draw conclusions about similarity based on the results. The next, more difficult task is to search for the connection between different words, understanding synonyms. And finally, the third stage: analysis of the entire sentence / text, isolating the meaning and comparing sentences / texts by meanings.

One way to solve this problem is to find some mapping from the space of texts to some simpler one. For example, you can translate texts into vector space and compare vectors.
Let's go back to the beginning and consider the simplest approach: search for matching words in queries and documents. Such a task in itself is already quite complicated: to do this well, we need to learn how to get the normal form of words, which in itself is nontrivial.
| Inquiry
| Document title
|
|---|---|
| Fairytale hero
| ABC of fairytale heroes
|
| Fairytale hero
| Literature for preschool age
|
The direct mapping model can be greatly improved. One solution is to match conditional synonyms. For example, you can enter probabilistic assumptions on the distribution of words in texts. You can work with vector representations and implicitly isolate the relationship between the mismatched words, and do it automatically.
Since we are engaged in search, we have a lot of data about the behavior of users when receiving certain documents in response to some queries. Based on these data, we can draw conclusions about the relationship between different words.
Let's take two sentences:

Assign each pair of words from the query and from the title some weight, which will mean how much the first word is associated with the second. We will predict the click as a sigmoidal transformation of the sum of these weights. That is, we set the task of logistic regression, in which the attributes are represented by a set of pairs of the form (word from the query, word from the title / text of the document). If we can train such a model, then we will understand which words are synonyms, more accurately, can be connected, and which ones most likely cannot.
Now you need to create a good dataset. It turns out that it’s enough to take the click history of users, add negative examples. How to mix in negative examples? It is best to add them to the dataset in a 1: 1 ratio. Moreover, the examples themselves at the first stage of training can be done randomly: for a query-document pair we find another random document, and we consider such a pair a negative. At later stages of training, it is beneficial to give more complex examples: those that have intersections, as well as random examples that the model considers similar (hard negative mining).
Example: synonyms for the word "triangle".
| Original word
| Synonym
| The weight
|
|---|---|---|
| TRIANGLE
| GEOMETRY
| 0,55878
|
| TRIANGLE
| SOLVE
| 0.66079
|
| TRIANGLE
| EQUILATERAL
| 0.37966
|
| TRIANGLE
| OGE
| 0,51284
|
| TRIANGLE
| BERMUDIAN
| 0.52195
|
At this stage, we can already distinguish a good function that matches words, but this is not what we are striving for. This function allows us to do indirect word matching, and we want to compare whole sentences.
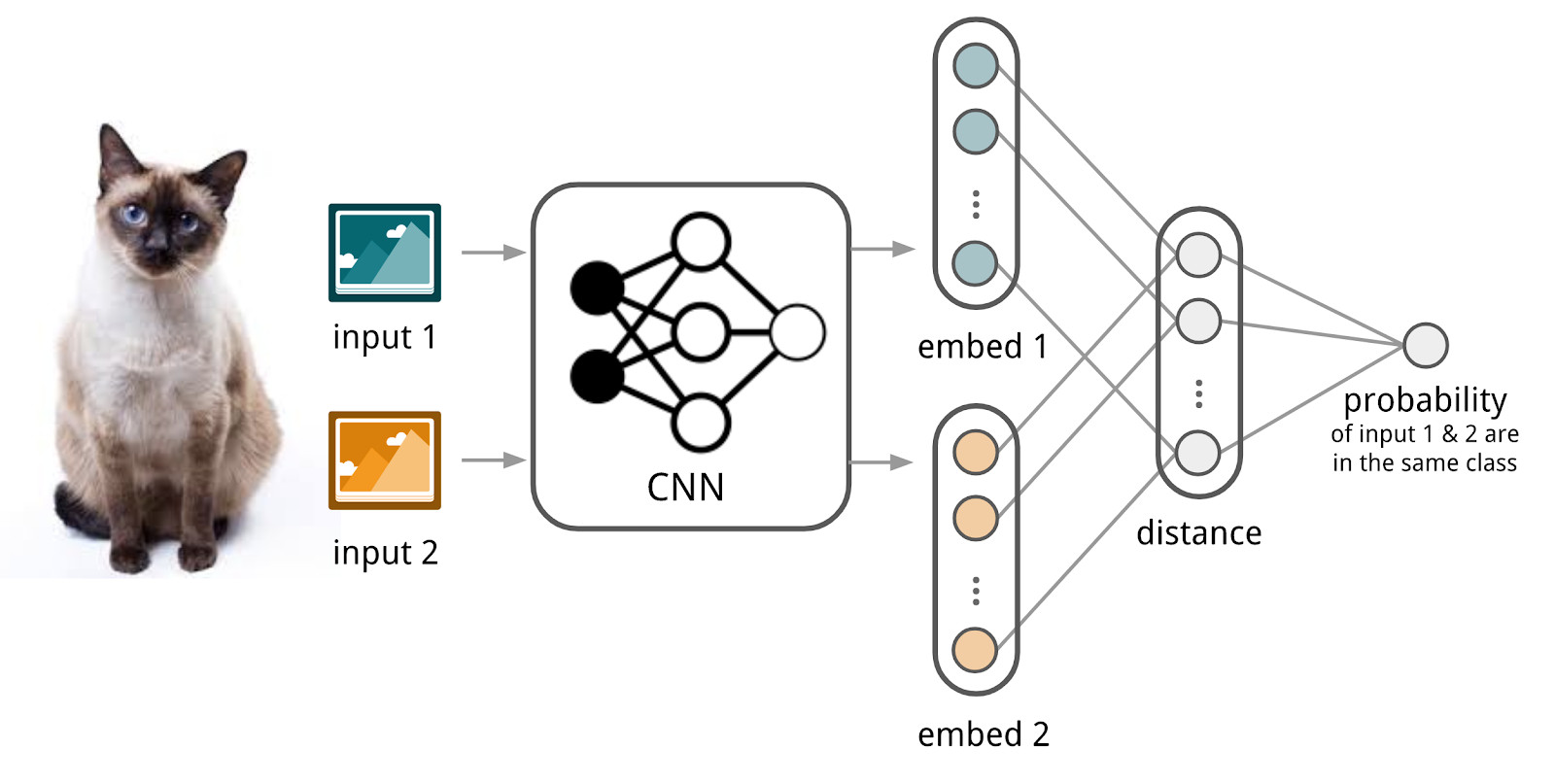
Here neural networks will help us. Let's make an encoder that accepts text (a query or a document) and produces a vector representation such that similar texts have vectors close and distant ones distant. For example, you can use the cosine distance as a measure of similarity.
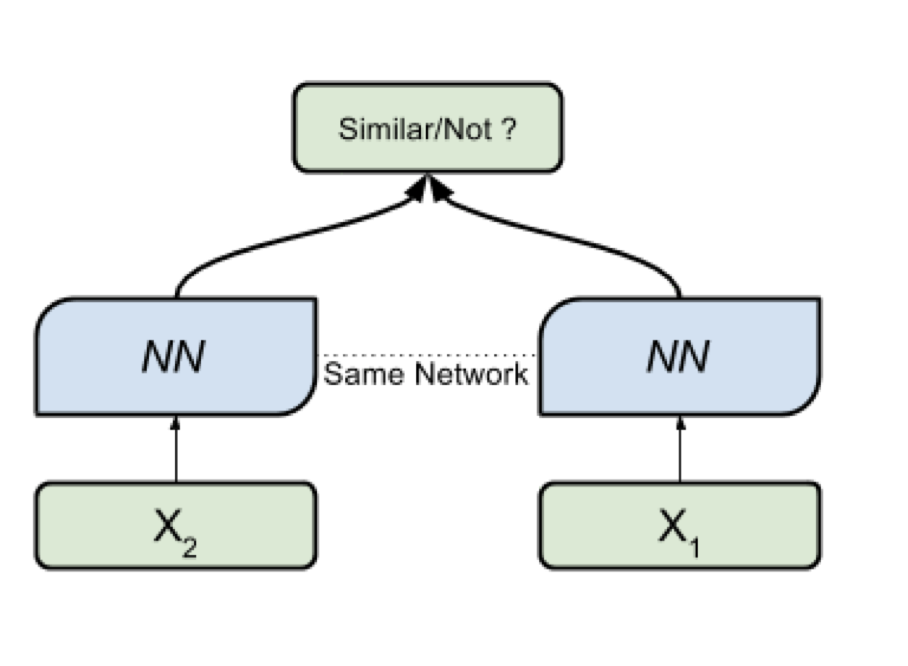
Here we will use the apparatus of Siamese networks, because they are much easier to train. The Siamese network consists of an encoder, which is applied to data samples from two or more families and a comparison operation (for example, cosine distance). When applying the encoder to elements from different families, the same weights are used; this in itself gives a good regularization and greatly reduces the number of factors needed for training.
Encoder produces vector representations from texts and learns so that the cosine between representations of similar texts is maximum, and between representations of dissimilar ones is minimal.
A network of deep semantic complexity DSSM is suitable for our task. We use it with minor changes, which I will discuss below.
How the classic DSSM works: requests and documents are presented in the form of a bag of trigrams, from which a standard vector representation is obtained. It is passed through several fully connected layers, and the network is trained in such a way as to maximize the conditional probability of the document on request, which is equivalent to maximizing the cosine distance between the vector representations obtained by a full passage through the network.
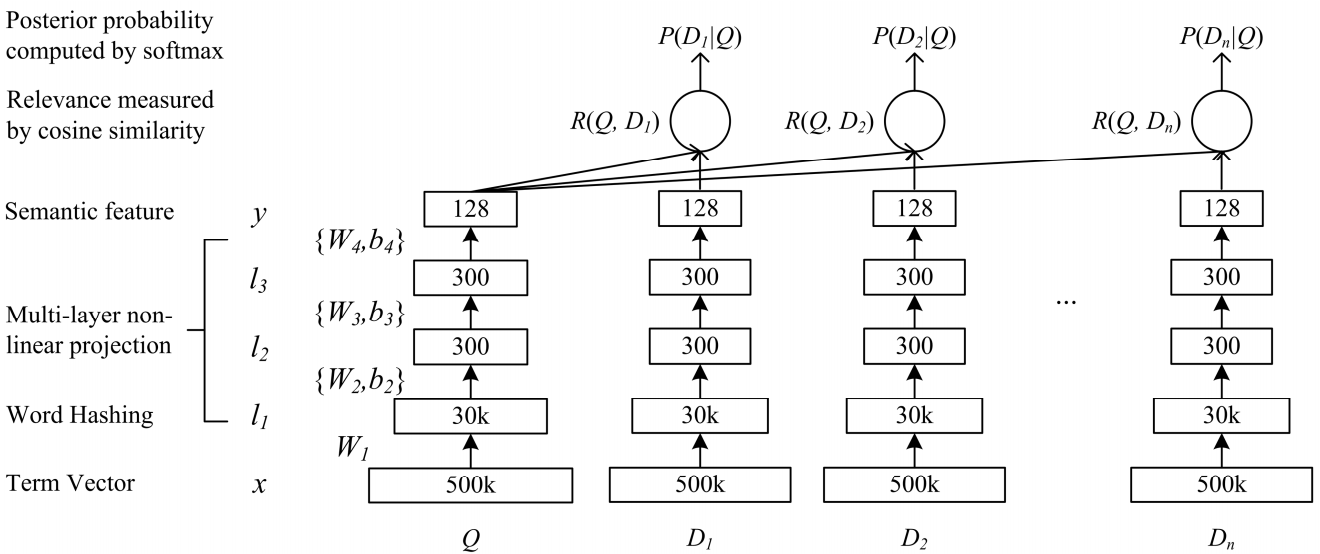
Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
We went almost the same way. Namely, each word in the query is represented as a vector of trigrams, and the text as a vector of words, thus leaving information about which word where stood. Next, we use one-dimensional convolutions inside the words, smoothing the representation of these, and the global maximum pulling operation to aggregate information about the sentence in a simple vector representation.

The dataset that we used for training almost completely coincides in essence with the one used for the linear model.
We did not stop there. Firstly, they came up with a pre-training mode. We take a list of queries for the document, entering which users interact with this document, and train the neural network to embed such pairs close. Since these pairs are from the same family, such a network is easier to learn. Plus, then it’s easier to retrain it on combat examples when we compare requests and documents.
Example: users go to e.mail.ru/login with requests: email, email input, email address, ...
| Inquiry
| Document
| BM25
| Neurorank
|
|---|---|---|---|
| Astana Toyota
| Toyota official website in Kazakhstan
| 0
| 0.839
|
| poetry
| Poetry.ru
| 0
| 0.823
|
| World Dream Pattaya
| Bangkok Dream World
| 0
| 0.818
|
| spb potato
| Buy potatoes in St. Petersburg
| 0
| 0.811
|
Finally, the last difficult part, which we are still struggling with and in which we have almost achieved success, is the task of comparing the request with some long document. Why is this task more difficult? Here, the machinery of Siamese networks is already worse suited, because the request and the long document belong to different families of objects. Nevertheless, we can afford to hardly change the architecture. It is only necessary to add convolutions also according to the words, which will save more information about the context of each word for the final vector representation of the text.
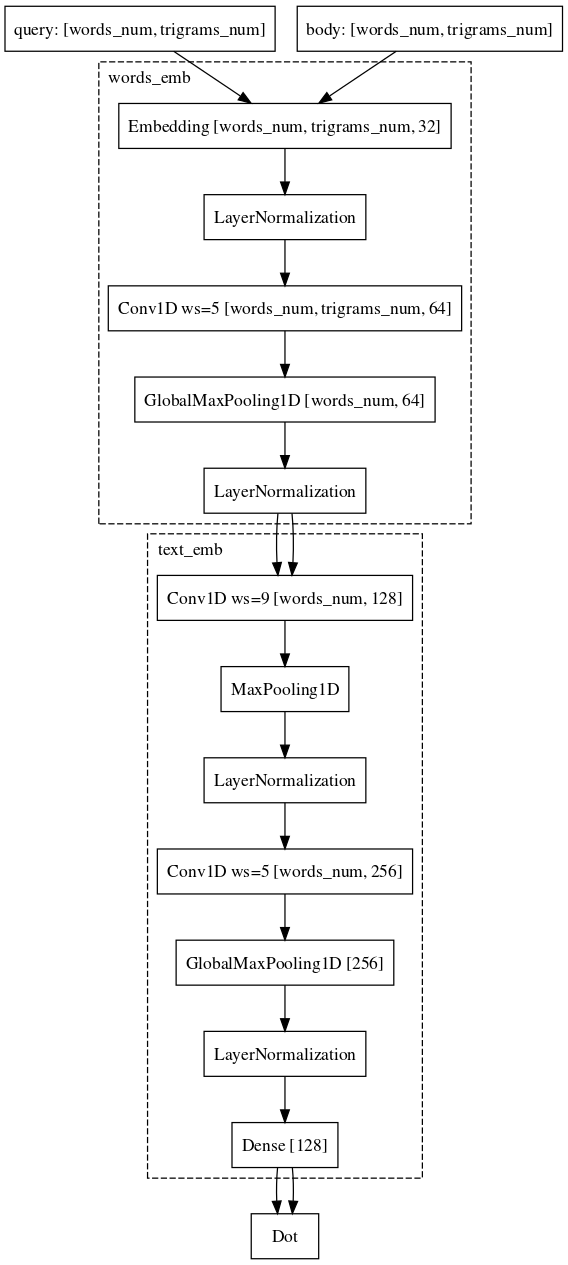
At the moment, we continue to improve the quality of our models by modifying architectures and experimenting with data sources and sampling mechanisms.
All Articles