Performance Optimization for .NET (C #) Applications

There are a lot of articles with a similar heading, so I will try to avoid commonplace topics. I hope that even very experienced developers will find here something useful for themselves. This article will consider only simple mechanisms and optimization approaches that will allow them to be applied with a minimum of effort. And these changes will not increase the entropy of your code. The article will not pay attention to what and when to optimize, this article is more about the approach to writing code in general.
1. ToArray vs ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
Agree, a very typical code for industrial projects. But what's wrong with him? The IEnumerable interface returns a collection that you can “go over”; this interface does not imply that we can add / remove elements. Accordingly, there is no need to end the LINQ expression by casting to a List (ToList). In this case, casting to Array (ToArray) is preferable. Since List is a wrapper over Array, and we cut off all the additional features provided by this wrapper with an interface. An array consumes less memory, and access to its values is faster. Accordingly, why pay more. On the one hand, this optimization is not significant, as they say “optimization on matches”, but this is not entirely true. The fact is that in a typical application in which numerous services return models for the presentation layer, there can be a myriad of such “extra” ToList calls. In the example described above, the IEnumerable interface is introduced for clarity. This approach is relevant for all cases when you need to return a collection that you are not going to change later.
I foresee a comment that Array and List will not work equivalently in the case of multi-threaded access to the collection. It really is. But if you, as a developer, are considering the possibility of multi-threaded access to such a collection with the possibility of changing it, then with a high degree of probability, neither Array nor List will suit you.
2. The “file path” parameter is not always the best choice for your method
When developing an API, avoid method signatures that get a file path as input (for later processing by your method). Instead, provide the ability to pass an array of bytes to the input, or as a last resort Stream. The fact is that over time, your method can be applied not only to a file from a disk, but also to a file transferred over the network or to a file from an archive, to a file from a database, to a file whose contents are generated dynamically in memory, etc. e. By providing a method with an input parameter "path to a file", you oblige the user of your API to save the data to disk before reading it again. This meaningless operation critically affects performance. A drive is an extremely slow thing. For convenience, you can provide a method with an input parameter "path to a file", but inside always use a public overloaded method with an array of bytes or stream at the input. There is a “marker” that can help find extra disk write / read operations, try using standard methods in your project:
Path.GetTempPath()
,
Path.GetRandomFileName()
(from System.IO). With a high degree of probability, you will encounter a workaround of the above problem or similar.
An attentive and experienced reader will notice that in some cases, writing to a disc can, on the contrary, improve performance, for example, if we are dealing with very large files. This is true, it must be taken into account, but I assume that this is a very rare situation with a specific implementation.
3. Avoid using threads as parameters and the return result of your methods
What is the problem here ... when we get a stream from some “black box”, we must keep in mind its state. Those. Is the stream open? Where is the read / write marker located? Can its state change regardless of our code? If a stream is declared as a base class of Stream, we don’t even have information on what operations on it are available. All this is solved by additional checks, and this is additional code and costs. Also, I repeatedly came across a situation where, when receiving Stream from some “obscure” method, the developer preferred to play it safe and “transfer” data from it to a completely controlled new local MemoryStream. Although, the source stream could be quite safe. Maybe even this was already kindly prepared for reading MemoryStream. Sometimes it can reach the point of absurdity - inside a method, an array of bytes is put in a MemoryStream, then this MemoryStream is returned as the result of a method declared as a base Stream. Outside, this Stream turns into a new MemoryStream, and then calling ToArray () returns an array of bytes, which we originally had. More precisely, it will already be a copy of it. The irony is that inside and outside our method, the code is completely correct. In my opinion, this example is also not out of my head, but was found somewhere in the commercial code.
As a result, if you have the ability to send / receive "clean" data, do not use streams for this - do not create traps for those who will use it. If your application already has a thread transfer / return, analyze their use based on the foregoing.
4. Inheritance of enums
This optimization is commonplace, everyone knows it, even students. But from my experience, it is extremely rarely used. So, by default, enum inherits from int. However, it can be inherited from byte, which holds 256 values (or 8 “flaggable” values). Which almost always covers the functionality of the "middle" enum. A minimal change in the code and all the values of your enum take up less memory forever. Below is an illustration of a benchmark for filling a collection with enum values inherited from int and byte.
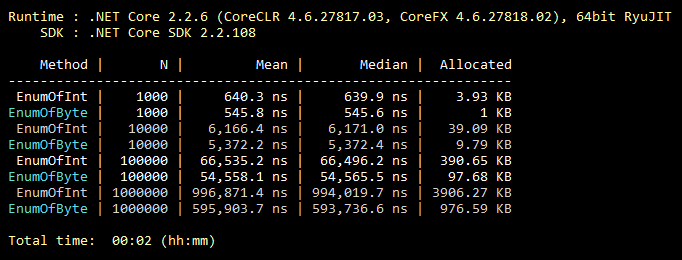
Benchmark code
public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5. A few more words about the classes Array and List
Following the logic, iterating over an array is always more efficient than iterating over a “sheet”, since a “sheet” is a wrapper over an array. Also, following the logic, “for” is always faster than “foreach”, since “foreach” does a lot of the actions required by the implementation of the IEnumerable interface. Everything is logical here, but wrong! Let's take a look at the benchmark results:

Benchmark code
public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random random = new Random(); _list = Enumerable.Repeat(0, N).Select(i => random.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
The fact is that for iterating over an array, “foreach” does not use an IEnumerable implementation. In this particular case, the most optimized iteration by index is performed, without checking for out-of-bounds of the array, since the “foreach” construct does not operate with indexes, so the developer does not have the option of “messing up” the code. Such an exception. Therefore, if in some critical section of the code you replaced the use of “foreach” with “for” for the sake of optimization, you shot yourself in the foot. Please note that this is relevant only for arrays . There are several branches on StackOverflow where this feature is discussed.
6. Is searching through a hash table always justified?
Everyone knows that hash tables are very effective for searching. But they often forget that the price for a quick search is a slow addition to the hash table. What follows from this? In order for the use of the hash table to be justified, it is necessary that the number of hash table elements be at least 8 (approximately). And so that the number of search operations was at least an order of magnitude greater than the number of operations of adding. Otherwise, use a simpler collection. The quality of the hash function can make its own adjustments to efficiency, but the meaning of this will not change. In my practice, there was a case when the most bottleneck in the loaded code was calling the Dictionary.Add () method. The key was a regular string, of short length. Remembering this and became a trigger for writing this paragraph. To illustrate, an example of very bad code:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
Maybe something similar occurs in your project?
7. Embedding methods
The code is divided into methods most often for 2 reasons. Ensure code reuse and decomposition when one task is split into several subtasks. It’s easier for a person. Inlining is the reverse process of decomposition, i.e. the method code is embedded in the place where the method should be called; as a result, we save on the call stack and passing parameters. In no way do I recommend “stuffing” everything into one method. But those methods that we could theoretically “inline” can be marked with the corresponding attribute:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
This attribute will tell the system that this method can be embedded. This does not mean that the method marked with this attribute will be necessarily built-in. For example, it is not possible to embed recursive or virtual methods. It is also worth noting that the embedding mechanism is extremely “delicate”. There are many other reasons why the system will refuse to embed your method. However, the Microsoft team working on .NET Core is actively using this attribute. The source code for .NET Core has many examples of its use.
8. Estimated Capacity
I (and I hope that most developers too) have developed a reflex: I initialized the collection - I thought about whether it is possible to set Capacity for it. However, the exact number of collection elements is not always known in advance. But this is not a reason to ignore this parameter. For example, if, talking about how many items will be in your collection, you assume a blurry “couple of thousands”, this is an occasion to set Capacity to 1000. A bit of theory, for example, for List by default, Capacity = 16, so that only reach 1000, the system will make 1008 (16 + 32 + 64 + 128 + 256 + 512) extra copies of the elements and create 7 temporary arrays to be dealt to the next GC call. Those. all this work will be wasted. Also, no one forbids using the formula as Capacity. If the size of your collection is estimated to be equal to one third of the other collection, you can set Capacity equal to otherCollection.Count / 3. When setting Capacity, it’s good to understand the range of the possible size of the collection and how closely its value is distributed. There is always a chance of harm, but when used correctly, an estimated Capacity will give you a good win.
9. Always specify your code.
Actively use (at first glance, optional) C # keywords, such as: static, const, readonly, sealed, abstract, etc. Naturally, where they make sense. And here is the performance? The fact is that the more detailed you describe your system to the compiler, the more optimal the code it can generate. An attentive and experienced reader may notice that, for example, the sealed keyword has no effect on performance. Now this is true, but in future versions everything can change. Give the compiler and virtual machine a chance! Get a bonus, identifying many errors of improper use of your code at the compilation stage. General rule: the more clearly the system is described, the more optimal the result. Apparently, with people as well.
The real story confirms this rule, but if you read laziness - you can skip
One night, while engaged in his hobby project , he set himself the task of increasing the performance of a section of code above a certain level. But this site was short and there were few options for what to do with it. I found in the documentation that, starting with version C # 7.2, the “readonly” keyword can be used for structures. And in my case, immutable structures were used, by adding a single word “readonly” I got what I wanted, even with a margin! The system, knowing that my structures are not intended to be modified, was able to generate better code for my case.
10. If possible, use one version of .NET for all Solution projects
You should strive to ensure that all assemblies within your application belong to the same version of .NET. This applies to both NuGet packages (edited in packages.config / json) and your own assemblies (edited in Project properties). This will save RAM and speed up the "cold" start, since in your application’s memory there will be no copies of the same libraries for different versions of .NET. It is worth noting that not in all cases, different versions of .NET will generate copies in memory. But assume that an application built on one version of .NET is always better. Also, this will eliminate a number of potential problems that lie outside the scope of this article. Consolidating versions of all the NuGet packages you use will also contribute to improving the performance of your application.
Some useful tools
ILSpy is a free tool that allows you to view the restored assembly source code. If I have a question about which .NET mechanism is more efficient, first of all I open ILSpy (and not Google or StackOverflow), and already there I see how it is implemented. For example, to find out what is better to use in terms of performance for receiving data via HTTP, the HttpWebRequest or WebClient class, just look at their implementation through ILSpy. In this particular case, WebClient is a wrapper over HttpWebRequest. .NET source codes are not afraid, they are written by the same ordinary programmers.
BenchmarkDotNet is a free library of benchmarks. There is a simple and intuitive StopWatch (from System.Diagnostics). But sometimes it is not enough. Since in a good way it is necessary to take into account not a single result, but the average of several comparisons, it is better to compare their median in order to minimize the influence of the OS. Also, you need to take into account the "cold start" and the amount of allocated memory. For such complex tests, BenchmarkDotNet was created. It is this library that .NET Core developers use in official tests. The library is easy to use, but if its authors suddenly read this post, please give a more convenient opportunity to influence the structure of the results table.
U2U Consult Performance Analyzers is a free plug-in for Visual Studio that provides tips on improving code in terms of performance. 100% rely on the advice of this analyzer is not worth it. Since I came across a situation where one piece of advice surprised me a little and after a detailed analysis it really turned out to be erroneous. Unfortunately, this example is lost, so take a word. However, if you use it thoughtfully, it’s a very useful tool. For example, he will suggest that instead of
myStr.Replace("*", "-")
more efficient to use
myStr.Replace('*', '-')
. And the two Where expressions in LINQ are better combined into one. These are all “optimization on matches”, but they are easy to apply and do not lead to an increase in code / complexity.
In conclusion
If every 10th person who reads the article applies the above approaches to his current project (or a critical part of it), and also adheres to these approaches in the future, then TOGETHER we can save the whole forest! Forest??? Those. the saved resources of computer systems, in the form of electricity obtained from burning wood, will remain unused. In this case, the "forest" is just some kind of equivalent. Probably a strange conclusion came out, but I hope you are inspired by the thought.
PS Update based on post comments
The advantage of ToArray over ToList is relevant only for .NET Core. If you use the old .NET Framework, then ToList will be preferable for you. In general, this question turned out to be more complicated, since different classes implementing IEnumerable may have different implementations of ToArray and ToList, with different levels of efficiency.
If enum is used as a member of a class (structure), and not separately, then the enum inherited from byte will not save memory. Due to the alignment of the occupied memory of all members of the class (structure). This point is missing in the article. Nevertheless, the potential gain is better than its absence, since in addition to the occupied memory, enum's are also used. Therefore, paragraph 4 is still relevant, but with this important reservation.
Thanks to KvanTTT and epetrukhin for constructive comments on these issues.
Also, as Taritsyn noted, optimization at the JIT compilation stage for the “sealed” keyword still exists. But, this only confirms all the theses of the 9th paragraph.
It seems that all constructive comments have been taken into account.
I am very pleased with these comments. Since I myself, as an author, received a feedback and also learned something new for myself.
All Articles