Full Text Search in Android
In mobile applications, the search function is very popular. And if it can be neglected in small products, then in applications that provide access to a large amount of information, you can not do without a search. Today I will tell you how to correctly implement this function in programs for Android.

In the latter case, the full-text search built into SQLite comes to the rescue. With it, you can very quickly find matches in a large amount of information, which allows us to make multiple queries to different tables without sacrificing performance.
Consider the implementation of such a search using a specific example.
Let's say we need to implement an application that shows a list of movies from themoviedb.org . To simplify (so as not to go online), take a list of films and form a JSON file from it, put it in assets and locally populate our database.
Example JSON file structure:
SQLite uses virtual tables to implement full-text search. Outwardly, they look like regular SQLite tables, but any access to them does some backstage work.
Virtual tables allow us to speed up the search. But, in addition to advantages, they also have disadvantages:
To solve the latter problem, you can use additional tables that will contain part of the information, and store links to elements of a regular table in a virtual table.
Creating a table is slightly different from the standard, we have the keywords
and
:
Filling is no different from usual:
When executing the query, the
keyword is used instead of
:
To implement text input processing in the interface, we will use
:
The result is a basic search option. In the first element, the desired word was found in the description, and in the second element both in the title and in the description. Obviously, in this form it is not entirely clear what we found. Let's fix it.

To improve the obviousness of the search, we will use the auxiliary function
. It is used to display a formatted piece of text in which a match is found.
The code is identical to the first, not counting the request:
We try again:
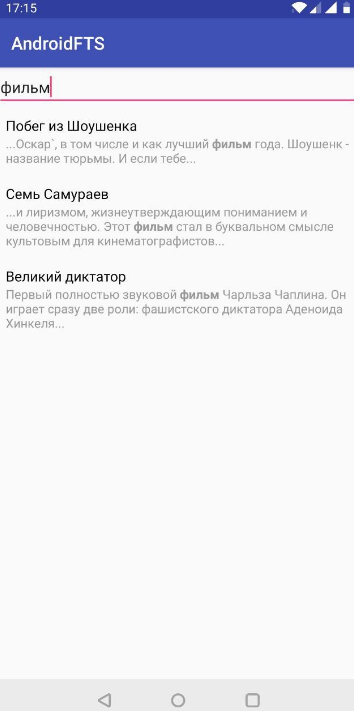
It turned out more clearly than in the previous version. But this is not the end. Let's make our search more "complete." We will use the lexical analysis and highlight the significant parts of our search query.
SQLite has built-in tokens that allow you to perform lexical analysis and transform the original search query. If when creating the table we did not specify a specific tokenizer, then “simple” will be selected. In fact, it just converts our data to lowercase and discards unreadable characters. It doesn’t quite suit us.
For a qualitative improvement in the search, we need to use stemming - the process of finding the word base for a given source word.
SQLite has an additional built-in tokenizer that uses the Porter Stemmer Stemming algorithm. This algorithm sequentially applies a number of specific rules, highlighting significant parts of a word by cutting off endings and suffixes. For example, when searching for “keys”, we can get a search where the words “key”, “keys” and “key” are contained. I will leave a link to a detailed description of the algorithm at the end.
Unfortunately, the tokenizer built into SQLite works only with English, so for the Russian language you need to write your own implementation or use ready-made developments. We will take the finished implementation from the algorithmist.ru site.
We transform our search query into the necessary form:
After this conversion, the phrase “courtyards and ghosts” looks like “yard * OR ghost * ”.
The symbol " * " means that the search will be conducted by the occurrence of a given word in other words. The " OR " operator means that results will be shown that contain at least one word from the search phrase. We look:
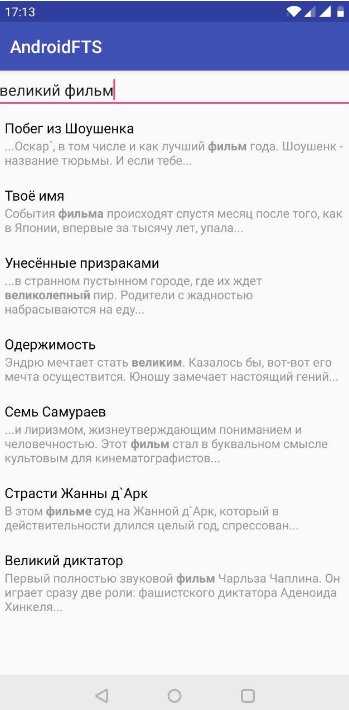
Full-text search is not as complicated as it might seem at first glance. We have analyzed a specific example that you can quickly and easily implement in your project. If you need something more complicated, then you should turn to the documentation, since there is one and it’s pretty well written.
Approaches to the implementation of search in a mobile application
- Search as a data filter
Usually it looks like a search bar above some list. That is, we just filter the finished data. - Server search
In this case, we give the entire implementation to the server, and the application acts as a thin client, from which it is only necessary to show the data in the right form. - Integrated Search
- the application contains a large amount of data of various types;
- the application works offline;
- Search is needed as a single access point to sections / content of the application.
In the latter case, the full-text search built into SQLite comes to the rescue. With it, you can very quickly find matches in a large amount of information, which allows us to make multiple queries to different tables without sacrificing performance.
Consider the implementation of such a search using a specific example.
Data preparation
Let's say we need to implement an application that shows a list of movies from themoviedb.org . To simplify (so as not to go online), take a list of films and form a JSON file from it, put it in assets and locally populate our database.
Example JSON file structure:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
Database Filling
SQLite uses virtual tables to implement full-text search. Outwardly, they look like regular SQLite tables, but any access to them does some backstage work.
Virtual tables allow us to speed up the search. But, in addition to advantages, they also have disadvantages:
- You cannot create a trigger on a virtual table;
- You cannot execute ALTER TABLE and ADD COLUMN commands for a virtual table;
- each column in the virtual table is indexed, which means that resources can be wasted on indexing columns that should not be involved in the search.
To solve the latter problem, you can use additional tables that will contain part of the information, and store links to elements of a regular table in a virtual table.
Creating a table is slightly different from the standard, we have the keywords
VIRTUAL
and
fts4
:
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
Commenting on the fts5 version
It has already been added to SQLite. This version is more productive, more accurate and contains a lot of new features. But due to the large fragmentation of Android, we cannot use fts5 (available with API24) on all devices. You can write different logic for different versions of the operating system, but this will seriously complicate further development and support. We decided to go the easier way and use fts4, which is supported on most devices.
Filling is no different from usual:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
Basic version
When executing the query, the
MATCH
keyword is used instead of
LIKE
:
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
To implement text input processing in the interface, we will use
RxJava
:
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
The result is a basic search option. In the first element, the desired word was found in the description, and in the second element both in the title and in the description. Obviously, in this form it is not entirely clear what we found. Let's fix it.
Add accents
To improve the obviousness of the search, we will use the auxiliary function
SNIPPET
. It is used to display a formatted piece of text in which a match is found.
snippet(movies, '<b>', '</b>', '...', 1, 15)
- movies - table name;
- <b & gt and </b> - these arguments are used to highlight a piece of text that was searched;
- ... - for the design of the text, if the result was an incomplete value;
- 1 - column number of the table from which pieces of text will be allocated;
- 15 is an approximate number of words included in the returned text value.
The code is identical to the first, not counting the request:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
We try again:
It turned out more clearly than in the previous version. But this is not the end. Let's make our search more "complete." We will use the lexical analysis and highlight the significant parts of our search query.
Finish improvement
SQLite has built-in tokens that allow you to perform lexical analysis and transform the original search query. If when creating the table we did not specify a specific tokenizer, then “simple” will be selected. In fact, it just converts our data to lowercase and discards unreadable characters. It doesn’t quite suit us.
For a qualitative improvement in the search, we need to use stemming - the process of finding the word base for a given source word.
SQLite has an additional built-in tokenizer that uses the Porter Stemmer Stemming algorithm. This algorithm sequentially applies a number of specific rules, highlighting significant parts of a word by cutting off endings and suffixes. For example, when searching for “keys”, we can get a search where the words “key”, “keys” and “key” are contained. I will leave a link to a detailed description of the algorithm at the end.
Unfortunately, the tokenizer built into SQLite works only with English, so for the Russian language you need to write your own implementation or use ready-made developments. We will take the finished implementation from the algorithmist.ru site.
We transform our search query into the necessary form:
- Remove extra characters.
- Break the phrase into words.
- Skip through the stemmer.
- Collect in a search query.
Porter Algorithm
object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
Algorithm where we break the phrase into words
val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
After this conversion, the phrase “courtyards and ghosts” looks like “yard * OR ghost * ”.
The symbol " * " means that the search will be conducted by the occurrence of a given word in other words. The " OR " operator means that results will be shown that contain at least one word from the search phrase. We look:
Summary
Full-text search is not as complicated as it might seem at first glance. We have analyzed a specific example that you can quickly and easily implement in your project. If you need something more complicated, then you should turn to the documentation, since there is one and it’s pretty well written.
References:
All Articles