Livy - the missing link in the Hadoop Spark Airflow Python chain
Hi everyone, some information "from under the hood" is the date of the engineering workshop of Alfastrakhovaniya - which excites our technical minds.

Apache Spark is a wonderful tool that allows you to simply and very quickly process large amounts of data on fairly modest computing resources (I mean cluster processing).
Traditionally, jupyter notebook is used in ad hoc data processing. In combination with Spark, this allows us to manipulate long-lived data frames (Spark deals with the allocation of resources, the data frames "live" somewhere in the cluster, their lifetime is limited by the lifetime of the Spark context).
After transferring data processing to Apache Airflow, the lifetime of the frames is greatly reduced - the Spark context "lives" within the same Airflow statement. How to get around this, why get around and what does Livy have to do with it - read under the cut.
Let's look at a very, very simple example: suppose we need to denormalize data in a large table and save the result in another table for further processing (a typical element of the data processing pipeline).
How would we do this:
- loaded data into a dataframe (selection from a large table and directories)
- looked with "eyes" at the result (did it work correctly)
- saved dataframe to Hive table (for example)
Based on the results of the analysis, we may need to insert in the second step some specific processing (dictionary replacement or something else). In terms of logic, we have three steps
- step 1: download
- step 2: processing
- step 3: save
This is how it works in jupyter notebook - we can process the downloaded data for an arbitrarily long time, giving Spark resources control.
It is logical to expect that such a partition can be transferred to Airflow. That is, to have a graph of this kind

Unfortunately, this is not possible when using the Airflow + Spark combination: each Airflow statement is executed in its python interpreter, therefore, among other things, each statement must somehow "persist" the results of its activities. Thus, our processing is “compressed” in one step - “denormalize data”.
How can jupyter notebook's flexibility be brought back to Airflow? It is clear that the above example is “not worth it” (maybe, on the contrary, it turns out a good understandable processing step). But still - how to make sure that Airflow statements can be executed in the same Spark context over the common dataframe space?
Welcome Livy
Another Hadoop ecosystem product comes to the rescue - Apache Livy.
I will not try to describe here what kind of “beast” it is. If it is very brief and black and white - Livy allows you to "inject" python code into a program that driver executes:
- first we create a work session with Livy
- after that we have the ability to execute arbitrary python code in this session (very similar to the jupyter / ipython ideology)
And to all this there is a REST API.
Returning to our simple task: with Livy we can save the original logic of our denormalization
- in the first step (the first statement of our graph) we will load and execute the data loading code in the dataframe
- in the second step (second statement) - execute the code for the necessary additional processing of this dataframe
- in the third step - the code to save the dataframe to the table
What in terms of Airflow might look like this:
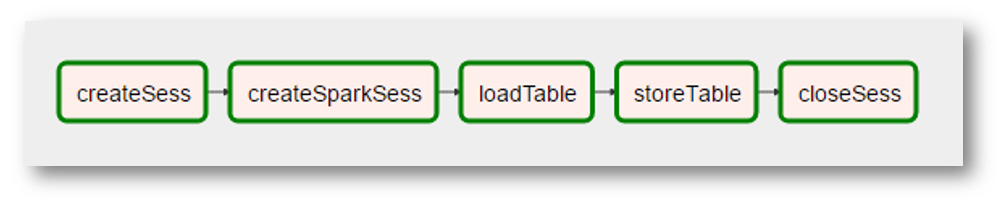
(since the picture is a very real screenshot, additional “realities” were added - creating Spark context became a separate operation with a strange name, the “processing” of the data disappeared because it was not needed, etc.)
To summarize, we get
- universal airflow statement that executes python code in a Livy session
- the ability to "organize" python code into fairly complex graphs (Airflow for that)
- the ability to tackle higher-level optimizations, for example, in what order do we need to perform our transformations so that Spark can hold the general data for as long as possible
A typical pipeline for preparing data for modeling contains about 25 queries over 10 tables, it is obvious that some tables are used more often than others (the same “general data") and there is something to optimize.
What's next
The technical ability has been tested, we think further - how to more technologically translate our transformations into this paradigm. And how to approach the optimization mentioned above. We are still at the beginning of this part of our journey - when there is something interesting, we will definitely share it.
All Articles