Sustainable Neural Machine Translation
In recent years, neural machine translation (NMI) using the "transformer" models has achieved extraordinary success. IMFs based on deep neural networks are usually trained from beginning to end in very voluminous parallel cases of texts (text pairs) solely on the basis of the data themselves, without the need to assign exact language rules.
Despite all the successes, NMP models can be sensitive to small changes in input data, which can manifest itself in the form of various errors - under-translation, over-translation, incorrect translation. For example, the next German proposal, the high-quality NMP-model “transformer” will translate correctly.
In our paper, “Sustainable Machine Translation with Double Adversarial Input,” we propose an approach that uses the generated adversarial examples to improve the stability of machine translation models for small input changes. We teach a stable NMP model to overcome competitive examples generated taking into account the knowledge about this model and in order to distort its predictions. We show that this approach improves the efficiency of the NMP model in standard tests.
An ideal NMP model should generate similar translations for different inputs that have slight differences. The idea of our approach is to interfere with the translation model using competitive input in the hope of increasing its stability. This is done using the Adversarial Generation (AdvGen) algorithm, which generates valid competitive examples that interfere with the model and then feed them into the model for training. Although this method is inspired by the idea of generative adversarial networks (GSS), it does not use a discriminator network, but simply uses a competitive example in training, essentially diversifying and expanding the training set.
The first step is to outrage the data with AdvGen. We start by using a transformer to calculate the loss of a transfer based on the original incoming offer, the target input offer, and the target output offer. AdvGen then randomly selects the words in the original sentence, acting on the assumption of their uniform distribution. Each word has a corresponding list of similar words, i.e. substitution candidates. From it, AdvGen selects the word that is most likely to lead to errors in the output of the transformer. Then this generated competitive offer is fed back to the transformer, starting the defense stage.

First, the transformer model is applied to the incoming sentence (bottom left), and then the translation loss is calculated together with the target output sentence (above top) and the target input sentence (in the middle right, starting with “<sos>”). AdvGen then accepts the original sentence, word selection distribution, word candidates, and translation loss as input and creates an example of a contentious source code.
At the defense stage, the adversarial source code is fed back to the transformer. Again, the loss of translation is calculated, but this time using the contentious input source. Using the same method as before, AdvGen uses a targeted incoming sentence, word selection distribution calculated from the attention matrix, candidates for word substitution, and translation loss to create an example of contentious source code.

At the defense stage, the adversarial source text becomes the input for the transformer, and translation losses are calculated. Using the same method as before, AdvGen creates an example of contentious source code based on the target input.
Finally, the adversarial sentence is fed back to the transformer, and the loss of stability is calculated based on the adversarial source example, the adversarial example of the target input and the target sentence. If the intervention in the text caused significant losses, they are minimized so that when the models encounter similar perturbations, she does not repeat the same error. On the other hand, if the disturbance leads to small losses, nothing happens, which suggests that the model is already able to cope with such disturbances.
We demonstrate the effectiveness of our approach by applying it to standard translation tests from Chinese to English and from English to German. We get a significant improvement in translation by 2.8 and 1.6 points BLEU, respectively, compared with the competing model of the transformer, and achieve a new record quality of translation.

Comparison of transformer models on standard tests
Then we evaluate the performance of our model on a noisy data set using a procedure similar to that described for AdvGen. We take pure input data, for example, those used in standard tests of translators, and randomly select words that we replace with similar ones. We find that our model shows improved stability compared to other recent models.
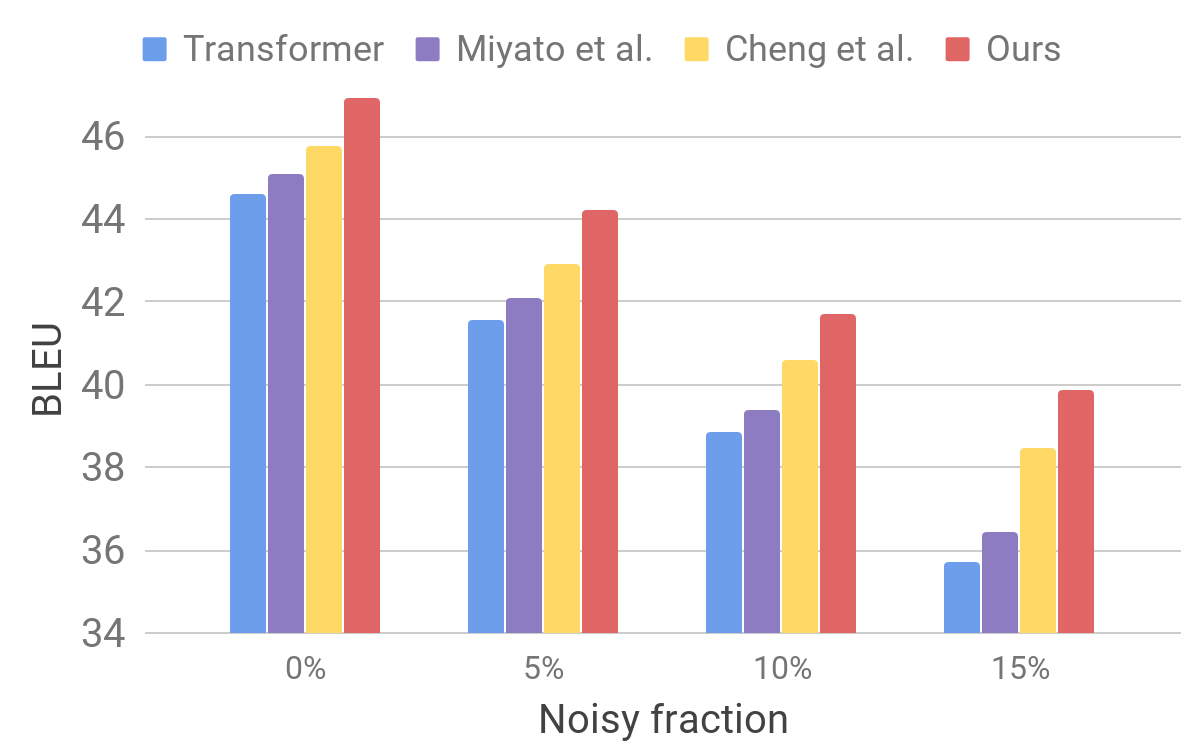
Comparison of transformer and other models on artificially noisy input data
These results show that our methods are able to overcome the small disturbances arising in the incoming sentence and improve the efficiency of generalization. He is ahead of competing translation models and achieves record translation efficiency on standard tests. We hope that our translator model will become a stable basis for improving the results of solving many of the following problems, especially those that are sensitive or intolerant of imperfect input texts.
Despite all the successes, NMP models can be sensitive to small changes in input data, which can manifest itself in the form of various errors - under-translation, over-translation, incorrect translation. For example, the next German proposal, the high-quality NMP-model “transformer” will translate correctly.
“Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die geladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.”However, when you make a small change to the incoming sentence, replacing geladenen with the synonym vorgeladenen, the translation changes dramatically (and becomes incorrect):
(Machine translation: “The spokesman of the Committee of Inquiry has announced that if the witnesses summoned continue to refuse to testify, he will be brought to court.”)
Translation: A representative of the Investigative Committee announced that if invited witnesses continue to refuse to testify, he will be held accountable.
“Der Sprecher des Untersuchungsausschusses hat angekündigt, vor Gericht zu ziehen, falls sich die vorgeladenen Zeugen weiterhin weigern sollten, eine Aussage zu machen.”The lack of stability of NMP models does not allow commercial systems to be applied to tasks in which a similar level of instability is unacceptable. Therefore, the presence of learners of stable translation models is not just desirable, but often necessary. At the same time, although the stability of neural networks is actively being studied by a community of computer vision researchers, there are few materials on stable learning NMF models.
(Machine translation: “The investigative committee has announced that he will be brought to justice if the witnesses who have been invited continue to refuse to testify.”).
Translation: the investigative committee announced that he would be brought to justice if invited witnesses continue to refuse to testify.
In our paper, “Sustainable Machine Translation with Double Adversarial Input,” we propose an approach that uses the generated adversarial examples to improve the stability of machine translation models for small input changes. We teach a stable NMP model to overcome competitive examples generated taking into account the knowledge about this model and in order to distort its predictions. We show that this approach improves the efficiency of the NMP model in standard tests.
Model Training with AdvGen
An ideal NMP model should generate similar translations for different inputs that have slight differences. The idea of our approach is to interfere with the translation model using competitive input in the hope of increasing its stability. This is done using the Adversarial Generation (AdvGen) algorithm, which generates valid competitive examples that interfere with the model and then feed them into the model for training. Although this method is inspired by the idea of generative adversarial networks (GSS), it does not use a discriminator network, but simply uses a competitive example in training, essentially diversifying and expanding the training set.
The first step is to outrage the data with AdvGen. We start by using a transformer to calculate the loss of a transfer based on the original incoming offer, the target input offer, and the target output offer. AdvGen then randomly selects the words in the original sentence, acting on the assumption of their uniform distribution. Each word has a corresponding list of similar words, i.e. substitution candidates. From it, AdvGen selects the word that is most likely to lead to errors in the output of the transformer. Then this generated competitive offer is fed back to the transformer, starting the defense stage.
First, the transformer model is applied to the incoming sentence (bottom left), and then the translation loss is calculated together with the target output sentence (above top) and the target input sentence (in the middle right, starting with “<sos>”). AdvGen then accepts the original sentence, word selection distribution, word candidates, and translation loss as input and creates an example of a contentious source code.
At the defense stage, the adversarial source code is fed back to the transformer. Again, the loss of translation is calculated, but this time using the contentious input source. Using the same method as before, AdvGen uses a targeted incoming sentence, word selection distribution calculated from the attention matrix, candidates for word substitution, and translation loss to create an example of contentious source code.
At the defense stage, the adversarial source text becomes the input for the transformer, and translation losses are calculated. Using the same method as before, AdvGen creates an example of contentious source code based on the target input.
Finally, the adversarial sentence is fed back to the transformer, and the loss of stability is calculated based on the adversarial source example, the adversarial example of the target input and the target sentence. If the intervention in the text caused significant losses, they are minimized so that when the models encounter similar perturbations, she does not repeat the same error. On the other hand, if the disturbance leads to small losses, nothing happens, which suggests that the model is already able to cope with such disturbances.
Model Performance
We demonstrate the effectiveness of our approach by applying it to standard translation tests from Chinese to English and from English to German. We get a significant improvement in translation by 2.8 and 1.6 points BLEU, respectively, compared with the competing model of the transformer, and achieve a new record quality of translation.
Comparison of transformer models on standard tests
Then we evaluate the performance of our model on a noisy data set using a procedure similar to that described for AdvGen. We take pure input data, for example, those used in standard tests of translators, and randomly select words that we replace with similar ones. We find that our model shows improved stability compared to other recent models.
Comparison of transformer and other models on artificially noisy input data
These results show that our methods are able to overcome the small disturbances arising in the incoming sentence and improve the efficiency of generalization. He is ahead of competing translation models and achieves record translation efficiency on standard tests. We hope that our translator model will become a stable basis for improving the results of solving many of the following problems, especially those that are sensitive or intolerant of imperfect input texts.
All Articles