Openstack Load Balancing (Part 2)
In a previous article, we talked about trying to use Watcher and presented a test report. We periodically conduct such tests to balance and other critical functions of a large corporate or operator cloud.
The high complexity of the problem being solved may require several articles to describe our project. Today we are publishing the second article in the series on balancing virtual machines in the cloud.
VmWare has introduced the DRS (Distributed Resource Scheduler) utility to balance the load of their virtualization environment.
As searchvmware.techtarget.com/definition/VMware-DRS writes
“VMware DRS (Distributed Resource Scheduler) is a utility that balances computing load with available resources in a virtual environment. The utility is part of a virtualization package called VMware Infrastructure.
Using VMware DRS, users define the rules for distributing physical resources between virtual machines (VMs). The utility can be configured for manual or automatic control. VMware resource pools can be easily added, removed or reorganized. If desired, resource pools can be isolated between different business units. If the workload of one or more virtual machines changes dramatically, VMware DRS redistributes the virtual machines between physical servers. If the overall workload is reduced, some physical servers may be temporarily down and the workload consolidated. ”
In our opinion, DRS is an indispensable feature of the cloud, although this does not mean that DRS should be used anytime, anywhere. Different requirements for DRS and balancing methods may exist depending on the purpose and needs of the cloud. Perhaps there are situations when balancing is not needed at all. Or even harmful.
To better understand where and for which DRS clients are needed, consider their goals and objectives. Clouds can be divided into public and private. Here are the main differences between these clouds and customer goals.
For private clouds provided to large corporate customers, DRS can be applied subject to restrictions:
For public clouds that provide services to small customers, DRS can be used much more often, with advanced features:
The difficulty of balancing is that DRS must work with a lot of uncertain factors:
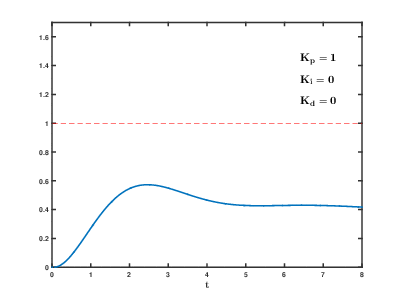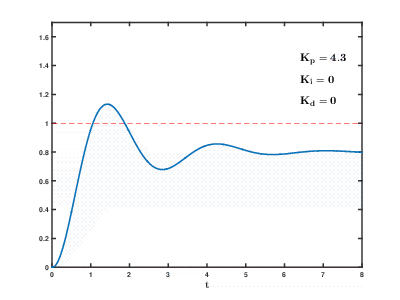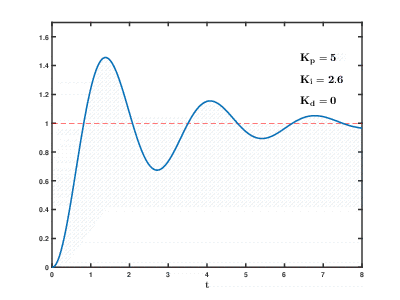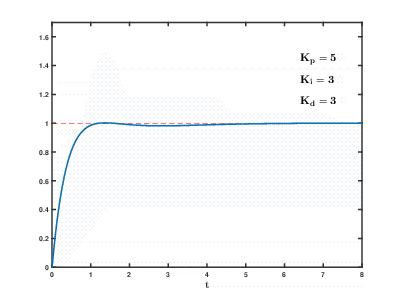
The load of a large number of virtual application servers and databases on cloud resources occurs over time, the consequences can occur and overlap with each other with an unpredictable effect after an unpredictable time. Even to control relatively simple processes (for example, to control an engine, a water heating system at home), automatic control systems need to use complex proportional-integral-differentiating feedback algorithms.

Our task is many orders of magnitude more complicated, and there is a risk that the system will not be able to balance the load to the established values in a reasonable time, even if there are no external influences from users.
To solve this problem, we decided not to start from scratch, but build on existing experience, and began to interact with experts in this field. Fortunately, our understanding of the problems coincided completely.
We used a system based on neural network technology, and tried to optimize our resources on its basis.
The interest of this stage was to test the new technology, and its importance was to apply a non-standard approach to solving the problem, where, other things being equal, the standard approaches have practically exhausted themselves.
We started the system, and we really went balancing. The scale of our cloud did not allow us to get optimistic results announced by the developers, but it was clear that balancing was working.
At the same time, we had rather serious limitations:
Since we were not happy with the state of affairs, we decided to modify the system, and for this to answer the main question - for whom are we doing it?
First, for corporate clients. So, we need a system that works efficiently, with those corporate restrictions that only simplify implementation.
The second question is what is meant by the word “operational”? As a result of a short debate, we decided that it is possible to build on the response time of 5-10 minutes so that short-term jumps do not introduce the system into resonance.
The third question is what size of the balanced number of servers to choose?
This issue was resolved by itself. Typically, clients do not make server aggregates very large, and this is consistent with the recommendations in the article to limit aggregates to 30-40 servers.
In addition, by segmenting the server pool, we simplify the task of the balancing algorithm.
The fourth question is how much a neural network suits us with its long learning process and rare balancing? We decided to abandon it in favor of simpler operational algorithms in order to get the result in seconds.
A description of the system using such algorithms and its shortcomings can be found here.
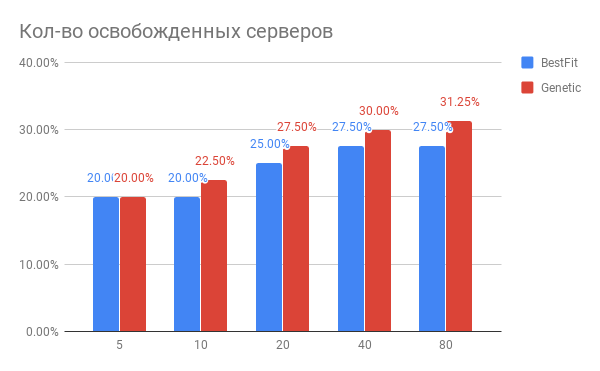
We implemented and launched this system and received encouraging results - now it regularly analyzes the cloud load and gives recommendations on moving virtual machines, which are largely correct. Even now it is clear that we can achieve 10-15% release of resources for new virtual machines with improving the quality of existing ones.

If an imbalance is detected by RAM or CPU, the system gives commands to the Tionics scheduler to perform live migration of the required virtual machines. As can be seen from the monitoring system, the virtual machine moved from one (upper) to another (lower) host and freed memory on the upper host (highlighted in yellow circles), occupying it respectively on the lower host (highlighted in white circles).
Now we are trying to more accurately evaluate the effectiveness of the current algorithm and are trying to find possible errors in it.
It would seem that you can calm down on this, wait for proven effectiveness and close the topic.
But the following obvious optimization opportunities are pushing us to conduct a new phase.
The result of our work on improving balancing algorithms was an unambiguous conclusion that due to modern algorithms it is possible to achieve significant resource optimization (25-30%) of data centers and improve the quality of customer service.
The algorithm based on neural networks is, of course, an interesting solution that needs further development, and due to existing restrictions, it is not suitable for solving such problems on volumes characteristic of private clouds. At the same time, in public clouds of a significant size, the algorithm showed good results.
We will tell you more about the capabilities of processors, schedulers and high-level balancing in the following articles.
The high complexity of the problem being solved may require several articles to describe our project. Today we are publishing the second article in the series on balancing virtual machines in the cloud.
Some terminology
VmWare has introduced the DRS (Distributed Resource Scheduler) utility to balance the load of their virtualization environment.
As searchvmware.techtarget.com/definition/VMware-DRS writes
“VMware DRS (Distributed Resource Scheduler) is a utility that balances computing load with available resources in a virtual environment. The utility is part of a virtualization package called VMware Infrastructure.
Using VMware DRS, users define the rules for distributing physical resources between virtual machines (VMs). The utility can be configured for manual or automatic control. VMware resource pools can be easily added, removed or reorganized. If desired, resource pools can be isolated between different business units. If the workload of one or more virtual machines changes dramatically, VMware DRS redistributes the virtual machines between physical servers. If the overall workload is reduced, some physical servers may be temporarily down and the workload consolidated. ”
Why do I need balancing?
In our opinion, DRS is an indispensable feature of the cloud, although this does not mean that DRS should be used anytime, anywhere. Different requirements for DRS and balancing methods may exist depending on the purpose and needs of the cloud. Perhaps there are situations when balancing is not needed at all. Or even harmful.
To better understand where and for which DRS clients are needed, consider their goals and objectives. Clouds can be divided into public and private. Here are the main differences between these clouds and customer goals.
| Private clouds / Large corporate clients | Public Clouds / Medium and Small Business, People | |
| The main criteria and objectives of the operator | Providing a reliable service or product | Reducing the cost of services in the fight in a competitive market |
| Service Requirements | Reliability at all levels and in all elements of the system
Guaranteed Performance Prioritization of virtual machines into several categories Information and physical data security SLA and 24/7 support | Maximum ease of service
Relatively simple services Responsibility for the data lies with the client VM prioritization not required Information security at the level of standard services, customer responsibility There may be failures No SLA, quality not guaranteed Mail Support Backup is optional |
| Customer Features | A very wide range of applications.
Legacy applications inherited in the company. Sophisticated custom architectures for each client. Affinity rules. Software work without stopping in 7x24 mode. Backup tools on the fly. Predictable customer cyclic load. | Typical applications - network balancing, Apache, WEB, VPN, SQL
It is possible to stop the application for a while Arbitrary distribution of VMs in the cloud is allowed Client backup A statistically averaged load predictable with a large number of customers. |
| Implications for Architecture | Geoclustering
Centralized or distributed storage Reserved IBS | Local storage of data on computing nodes |
| Balancing goals | Even load distribution
Maximum app responsiveness Minimum balancing delay time Balancing only when clearly needed Conclusion of a piece of equipment for preventive maintenance | Reducing the cost of services and operator costs
Disabling some resources in case of low load Energy saving Reduced staff costs |
We draw the following conclusions for ourselves:
For private clouds provided to large corporate customers, DRS can be applied subject to restrictions:
- information security and accounting affinity rules for balancing;
- availability of sufficient resources in the event of an accident;
- virtual machine data resides on a centralized or distributed storage system;
- time diversity of administration, backup and balancing procedures;
- balancing only within the aggregate of client hosts;
- balancing only with a strong imbalance, the most efficient and safe migration of VMs (after all, migration can fail);
- balancing relatively “quiet” virtual machines (migration of “noisy” virtual machines can take a very long time);
- balancing taking into account the "cost" - the load on the storage system and network (with customized architectures for large customers);
- balancing taking into account the individual behavior of each VM;
- balancing is desirable after hours (night, weekends, holidays).
For public clouds that provide services to small customers, DRS can be used much more often, with advanced features:
- lack of information security restrictions and affinity rules;
- balancing within the cloud;
- balancing at any reasonable time;
- balancing any VM;
- balancing “noisy” virtual machines (so as not to interfere with the rest);
- virtual machine data is often located on local disks;
- accounting for the average storage and network performance (cloud architecture is unified);
- balancing according to generalized rules and available statistics of data center behavior.
Problem complexity
The difficulty of balancing is that DRS must work with a lot of uncertain factors:
- user behavior of each of the customer information systems;
- algorithms for the operation of information system servers;
- DBMS server behavior
- load on computing resources, storage, network;
- server interaction among themselves in the struggle for cloud resources.
The load of a large number of virtual application servers and databases on cloud resources occurs over time, the consequences can occur and overlap with each other with an unpredictable effect after an unpredictable time. Even to control relatively simple processes (for example, to control an engine, a water heating system at home), automatic control systems need to use complex proportional-integral-differentiating feedback algorithms.
Our task is many orders of magnitude more complicated, and there is a risk that the system will not be able to balance the load to the established values in a reasonable time, even if there are no external influences from users.
History of our developments
To solve this problem, we decided not to start from scratch, but build on existing experience, and began to interact with experts in this field. Fortunately, our understanding of the problems coincided completely.
Stage 1
We used a system based on neural network technology, and tried to optimize our resources on its basis.
The interest of this stage was to test the new technology, and its importance was to apply a non-standard approach to solving the problem, where, other things being equal, the standard approaches have practically exhausted themselves.
We started the system, and we really went balancing. The scale of our cloud did not allow us to get optimistic results announced by the developers, but it was clear that balancing was working.
At the same time, we had rather serious limitations:
- For training a neural network, virtual machines need to run without significant changes for weeks or months.
- The algorithm is designed for optimization based on the analysis of earlier "historical" data.
- Neural network training requires a sufficiently large amount of data and computing resources.
- Optimization and balancing can be done relatively rarely - once every few hours, which is clearly not enough.
Stage 2
Since we were not happy with the state of affairs, we decided to modify the system, and for this to answer the main question - for whom are we doing it?
First, for corporate clients. So, we need a system that works efficiently, with those corporate restrictions that only simplify implementation.
The second question is what is meant by the word “operational”? As a result of a short debate, we decided that it is possible to build on the response time of 5-10 minutes so that short-term jumps do not introduce the system into resonance.
The third question is what size of the balanced number of servers to choose?
This issue was resolved by itself. Typically, clients do not make server aggregates very large, and this is consistent with the recommendations in the article to limit aggregates to 30-40 servers.
In addition, by segmenting the server pool, we simplify the task of the balancing algorithm.
The fourth question is how much a neural network suits us with its long learning process and rare balancing? We decided to abandon it in favor of simpler operational algorithms in order to get the result in seconds.
A description of the system using such algorithms and its shortcomings can be found here.
We implemented and launched this system and received encouraging results - now it regularly analyzes the cloud load and gives recommendations on moving virtual machines, which are largely correct. Even now it is clear that we can achieve 10-15% release of resources for new virtual machines with improving the quality of existing ones.
If an imbalance is detected by RAM or CPU, the system gives commands to the Tionics scheduler to perform live migration of the required virtual machines. As can be seen from the monitoring system, the virtual machine moved from one (upper) to another (lower) host and freed memory on the upper host (highlighted in yellow circles), occupying it respectively on the lower host (highlighted in white circles).
Now we are trying to more accurately evaluate the effectiveness of the current algorithm and are trying to find possible errors in it.
Stage 3
It would seem that you can calm down on this, wait for proven effectiveness and close the topic.
But the following obvious optimization opportunities are pushing us to conduct a new phase.
- Statistics, for example, here and here show that two- and four-processor systems in their performance are significantly lower than single-processor ones. This means that all users get significantly lower returns from CPUs, RAMs, SSDs, LANs, FCs purchased in multiprocessor systems compared to single-processor ones.
- Resource planners themselves can work with serious errors, here is one of the articles on this topic.
- The technologies offered by Intel and AMD for monitoring RAM and cache allow you to study the behavior of virtual machines and place them in such a way that noisy neighbors do not interfere with quiet virtual machines.
- Extension of the set of parameters (network, storage, virtual machine priority, migration cost, its readiness for migration).
Total
The result of our work on improving balancing algorithms was an unambiguous conclusion that due to modern algorithms it is possible to achieve significant resource optimization (25-30%) of data centers and improve the quality of customer service.
The algorithm based on neural networks is, of course, an interesting solution that needs further development, and due to existing restrictions, it is not suitable for solving such problems on volumes characteristic of private clouds. At the same time, in public clouds of a significant size, the algorithm showed good results.
We will tell you more about the capabilities of processors, schedulers and high-level balancing in the following articles.
All Articles