How I taught a snake to play itself using Q-Network
Once, exploring the depths of the Internet, I stumbled upon a video where a person trains a snake using a genetic algorithm. And I wanted the same. But just taking all the same and writing in python would not be interesting. And I decided to use a more modern approach for training agent systems, namely Q-network. But let's start from the beginning.
Reinforcement training
In machine learning, RL (Reinforcement Learning) is quite different from other areas. The difference is that the classic ML algorithm learns from ready-made data, while RL, so to speak, creates this data for itself. The idea of RL is that in addition to the algorithm itself, which is called an agent, there is an environment in which this agent is placed. At each stage, the agent must perform some action (action), and the environment responds with a reward (reward) and its state (state), on the basis of which the agent performs the action.
Dqn
There should be an explanation of how the algorithm works, but I will leave a link to where smart people explain it.
Snake implementation
After we figured out c rl, we need to create an environment in which we will place the agent. Fortunately, there is no need to reinvent the wheel, as a company such as open-ai has already written the gym library, with which you can write your own environment. In the library they are already in large numbers. From simple atari games to complex 3d models. But among all this there is no snake. Therefore, we proceed to its creation.
I will not describe all the moments of creating an environmental in gym, but I will show only the main class, in which it is required to implement several functions.
import gym class Env(gym.Env): def __init__(self): pass def step(self, action): """ . , """ def reset(self): """ """ def render(self, mode='human'): """ """
But to implement these functions, you need to come up with a system of rewards and in what form we will give information about the environment.
condition
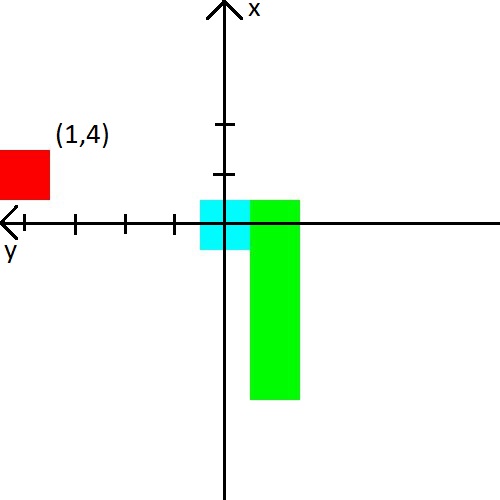
In the video, a man gave the snake the distance to the wall, snake and apple in 8 directions. Those are 24 numbers. I decided to reduce the amount of data, but complicate them a bit. First, I will combine the distance to the walls with the distance to the snake. Simply put, we will tell her the distance to the nearest object that can kill in a collision. Secondly, there will be only 3 directions and they will depend on the direction of movement of the snake. For example, when starting, the snake looks up, so we will tell it the distance to the upper, left and right walls. But when the head of the snake turns to the right, then we will already report the distance to the right, upper and lower walls. For simplicity, I’ll give you a picture.

I also decided to play with the apple. Information about it we will present in the form of (x, y) coordinates in the coordinate system, which originates at the head of the snake. The coordinate system will also change its orientation behind the snake’s head. After the picture, I think it should definitely become clear.
Reward
If you can come up with some kind of features with the state and hope that the neural network will figure it out, then with an award it’s more and more difficult. It depends on her whether the agent will learn and whether he will learn what we want.
I will immediately give the reward system with which I have achieved stable training.
- At each step, the reward is -0.25.
- At death -10.
- Upon death, up to 15 steps -100.
- When eating an apple sqrt ( number of apples eaten ) * 3.5.
And also give examples of what leads to a bad reward system.
- If you do not give a small enough reward for death in the first few steps, then the snake will prefer to kill against the wall. It's easier than looking for apples :)
- If you give a positive reward for the steps, then the snake will begin to spin endlessly. Because in her opinion it will be more profitable than looking for apples.
- And many other cases where the snake simply will not learn.

Total
The main interest in writing the snake was to see how the snake learns by knowing so little about its environment. And she studied well, as the average rate of eaten apples reached 23, which, it seems to me, is not very bad. Therefore, the experiment can be considered successful.
All Articles