Interpreted machine learning model. Part 1
Hello. Before the start of the Machine Learning course, just over a week remains. In anticipation of the start of classes, we have prepared a useful translation that will be of interest to both our students and all readers of the blog. Let's get started.

It's time to get rid of the black boxes and build faith in machine learning!
In his book “Interpretable Machine Learning”, Christoph Molnar perfectly highlights the essence of Machine Learning interpretability using the following example: Imagine that you are a Data Science expert and in your free time trying to predict where your friends will go on summer vacation based on their data from facebook and twitter. So, if the forecast is correct, then your friends will consider you a wizard who can see the future. If the predictions are wrong, then it will not do harm to anything other than your reputation as an analyst. Now imagine that it was not just a fun project, but investments were attracted to it. Let's say you wanted to invest in real estate where your friends are likely to relax. What happens if model predictions fail? You will lose money. As long as the model does not have a significant impact, its interpretability does not matter much, but when there are financial or social consequences associated with the predictions of the model, its interpretability takes on a completely different meaning.
To interpret is to explain or show in understandable terms. In the context of an ML-system, interpretability is the ability to explain its action or show it in a human-readable form .
Many people have dubbed machine learning models “black boxes”. This means that despite the fact that we can get an accurate forecast from them, we cannot clearly explain or understand the logic of their compilation. But how can you extract insights from the model? What things should be kept in mind and what tools do we need to do this? These are important questions that come to mind when it comes to model interpretability.
The question that some people ask is, why not just be glad that we are getting a concrete result of the model’s work, why is it so important to know how this or that decision was made? The answer lies in the fact that the model can have a certain impact on subsequent events in the real world. Interpretation will be much less important for models that are designed to recommend films than for models that are used to predict the effect of a drug.
“The problem is that just one metric, such as classification accuracy, is an inadequate description of most real-world tasks.” ( Doshi-Veles and Kim 2017 )
Here's a big picture about explainable machine learning. In a sense, we capture the world (or rather information from it), collecting raw data and using it for further forecasts. In essence, interpretability is just another layer of the model that helps people understand the whole process.
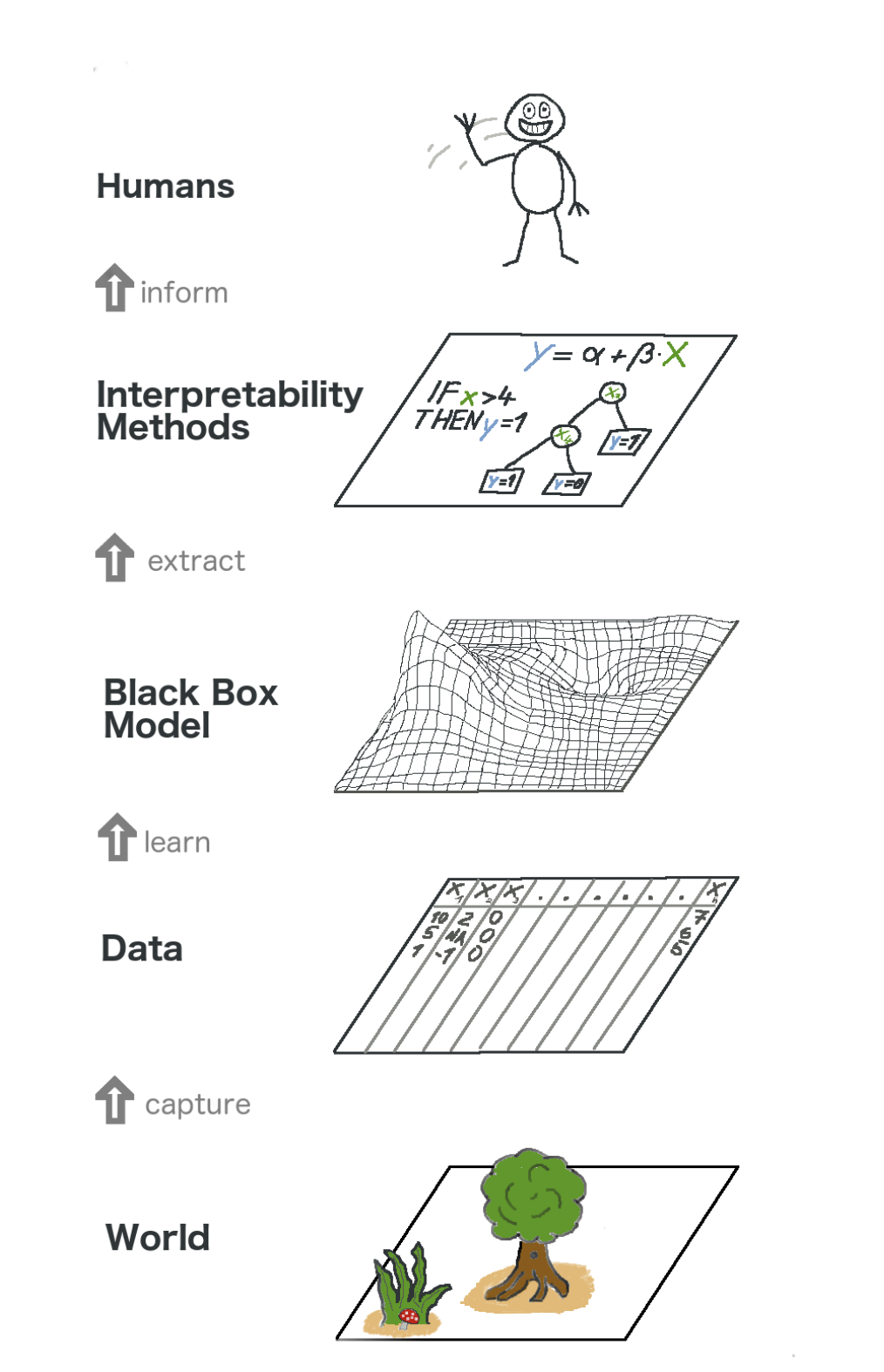
The text in the image from bottom to top: World -> Getting information -> Data -> Training -> Black Box model -> Extract -> Interpretation methods -> People
Some of the benefits that interpretability brings are:
A theory makes sense only as long as we can put it into practice. In case you really want to deal with this topic, you can try the Kaggle Machine Learning Explainability course. In it you will find the correct correlation of theory and code in order to understand the concepts and be able to put into practice the concepts of interpretability (explainability) of models to real cases.
Click on the screenshot below to go directly to the course page. If you want to get an overview of the topic first, continue reading.
To understand the model, we need the following insights:
Let's discuss a few methods that help extract the above insights from the model:
What features does the model consider important? What symptoms have the most impact? This concept is called feature importance, and Permutation Importance is a method widely used to calculate the importance of features. It helps us to see at what point the model produces unexpected results, it also helps us show others that our model works exactly as it should.
Permutation Importance works for many scikit-learn ratings. The idea is simple: Arbitrarily rearrange or shuffle one column in the validation dataset, leaving all other columns intact. A sign is considered "important" if the accuracy of the model falls and its change causes an increase in errors. On the other hand, a feature is considered “unimportant” if shuffling its values does not affect the accuracy of the model.
Consider a model that predicts whether a football team will receive the “Man of the Game” award or not, based on certain parameters. This award is given to the player who demonstrates the best skills of the game.
Permutation Importance is calculated after training the model. So, let's train and prepare the
model, designated as
, on the training data.
Permutation Importance is calculated using the ELI5 library. ELI5 is a library in Python that allows you to visualize and debug various machine learning models using a unified API. It has built-in support for several ML frameworks and provides ways to interpret the black-box model.
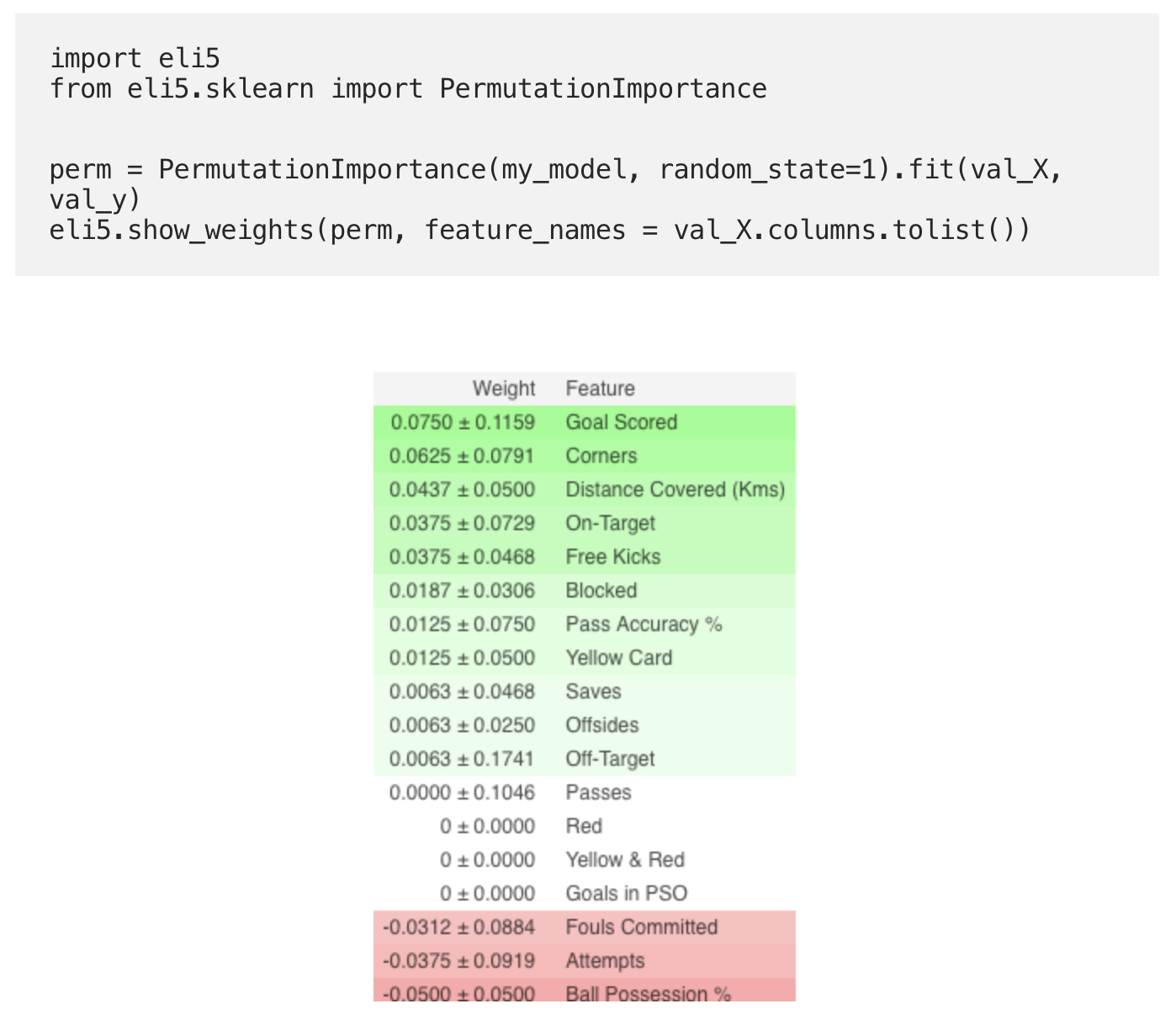
Calculation and visualization of importance using the ELI5 library:
(Here
,
denote validation sets, respectively)
And now, to look at the full example and check whether you understood everything correctly, go to the Kaggle page using the link .
So the first part of the translation came to an end. Write your comments and to meet on the course!
In the coming days we will publish the second part, which talks about Partial Dependence Plots, do not miss.
It's time to get rid of the black boxes and build faith in machine learning!
In his book “Interpretable Machine Learning”, Christoph Molnar perfectly highlights the essence of Machine Learning interpretability using the following example: Imagine that you are a Data Science expert and in your free time trying to predict where your friends will go on summer vacation based on their data from facebook and twitter. So, if the forecast is correct, then your friends will consider you a wizard who can see the future. If the predictions are wrong, then it will not do harm to anything other than your reputation as an analyst. Now imagine that it was not just a fun project, but investments were attracted to it. Let's say you wanted to invest in real estate where your friends are likely to relax. What happens if model predictions fail? You will lose money. As long as the model does not have a significant impact, its interpretability does not matter much, but when there are financial or social consequences associated with the predictions of the model, its interpretability takes on a completely different meaning.
Explained Machine Learning
To interpret is to explain or show in understandable terms. In the context of an ML-system, interpretability is the ability to explain its action or show it in a human-readable form .
Many people have dubbed machine learning models “black boxes”. This means that despite the fact that we can get an accurate forecast from them, we cannot clearly explain or understand the logic of their compilation. But how can you extract insights from the model? What things should be kept in mind and what tools do we need to do this? These are important questions that come to mind when it comes to model interpretability.
Importance of Interpretability
The question that some people ask is, why not just be glad that we are getting a concrete result of the model’s work, why is it so important to know how this or that decision was made? The answer lies in the fact that the model can have a certain impact on subsequent events in the real world. Interpretation will be much less important for models that are designed to recommend films than for models that are used to predict the effect of a drug.
“The problem is that just one metric, such as classification accuracy, is an inadequate description of most real-world tasks.” ( Doshi-Veles and Kim 2017 )
Here's a big picture about explainable machine learning. In a sense, we capture the world (or rather information from it), collecting raw data and using it for further forecasts. In essence, interpretability is just another layer of the model that helps people understand the whole process.
The text in the image from bottom to top: World -> Getting information -> Data -> Training -> Black Box model -> Extract -> Interpretation methods -> People
Some of the benefits that interpretability brings are:
- Reliability;
- Convenience of debugging;
- Information on engineering features;
- Managing data collection for characteristics
- Information on decision making;
- Building trust.
Model Interpretation Methods
A theory makes sense only as long as we can put it into practice. In case you really want to deal with this topic, you can try the Kaggle Machine Learning Explainability course. In it you will find the correct correlation of theory and code in order to understand the concepts and be able to put into practice the concepts of interpretability (explainability) of models to real cases.
Click on the screenshot below to go directly to the course page. If you want to get an overview of the topic first, continue reading.
Insights that can be extracted from models
To understand the model, we need the following insights:
- The most important features in the model;
- For any specific forecast of the model, the effect of each individual attribute on a specific forecast.
- The influence of each trait on a large number of possible forecasts.
Let's discuss a few methods that help extract the above insights from the model:
Permutation Importance
What features does the model consider important? What symptoms have the most impact? This concept is called feature importance, and Permutation Importance is a method widely used to calculate the importance of features. It helps us to see at what point the model produces unexpected results, it also helps us show others that our model works exactly as it should.
Permutation Importance works for many scikit-learn ratings. The idea is simple: Arbitrarily rearrange or shuffle one column in the validation dataset, leaving all other columns intact. A sign is considered "important" if the accuracy of the model falls and its change causes an increase in errors. On the other hand, a feature is considered “unimportant” if shuffling its values does not affect the accuracy of the model.
How it works?
Consider a model that predicts whether a football team will receive the “Man of the Game” award or not, based on certain parameters. This award is given to the player who demonstrates the best skills of the game.
Permutation Importance is calculated after training the model. So, let's train and prepare the
RandomForestClassifier
model, designated as
my_model
, on the training data.
Permutation Importance is calculated using the ELI5 library. ELI5 is a library in Python that allows you to visualize and debug various machine learning models using a unified API. It has built-in support for several ML frameworks and provides ways to interpret the black-box model.
Calculation and visualization of importance using the ELI5 library:
(Here
val_X
,
val_y
denote validation sets, respectively)
Interpretation
- The signs above are the most important, below are the least. For this example, the most important sign was goals scored.
- The number after ± reflects how productivity has changed from one permutation to another.
- Some weights are negative. This is due to the fact that in these cases the forecasts for the shuffled data turned out to be more accurate than the actual data.
Practice
And now, to look at the full example and check whether you understood everything correctly, go to the Kaggle page using the link .
So the first part of the translation came to an end. Write your comments and to meet on the course!
In the coming days we will publish the second part, which talks about Partial Dependence Plots, do not miss.
All Articles