The book "Grok deep learning"
 Hello, habrozhiteli! The book lays the foundation for further mastery of deep learning technology. It begins with a description of the basics of neural networks and then examines in detail the additional levels of architecture.
Hello, habrozhiteli! The book lays the foundation for further mastery of deep learning technology. It begins with a description of the basics of neural networks and then examines in detail the additional levels of architecture.
The book is specially written with the intention of providing the lowest possible entry threshold. You do not need knowledge of linear algebra, numerical methods, convex optimizations, and even machine learning. All that is required to understand deep learning will be clarified as you go.
We offer you to familiarize yourself with the passage "What is a deep learning framework?"
Good tools reduce errors, speed development, and increase execution speed.
If you read a lot about deep learning, you probably came across such well-known frameworks as PyTorch, TensorFlow, Theano (recently declared obsolete), Keras, Lasagne and DyNet. In the past few years, frameworks have evolved very quickly, and despite the fact that all these frameworks are distributed free and open source, each of them has a spirit of competition and camaraderie.
Until now, I have avoided discussing frameworks, because, first of all, it was extremely important for you to understand what was going on behind the scenes, implementing the algorithms manually (using only the NumPy library). But now we will start using such frameworks, because the networks we are going to train, networks with long-term short-term memory (LSTM), are very complex, and the code that implements them using NumPy is difficult to read, use and debug (gradients in this code are found everywhere).
It is this complexity that deep learning frameworks are designed to eliminate. The deep learning framework can significantly reduce code complexity (as well as reduce the number of errors and increase development speed) and increase its execution speed, especially if you use a graphics processor (GPU) to train a neural network, which can speed up the process by 10-100 times. For these reasons, the frameworks are used almost everywhere in the research community, and understanding the features of their work will come in handy in your career as a user and a deep learning researcher.
But we will not limit ourselves to the framework of any particular framework, because this will prevent you from learning how all these complex models (such as LSTM) work. Instead, we will create our own lightweight framework, following the latest trends in the development of frameworks. Following this path, you will know exactly what frameworks do when complex architectures are created with their help. In addition, an attempt to create your own small framework on your own will help you smoothly switch to the use of real deep learning frameworks, because you will already know the principles of organizing a program interface (API) and its functionality. This exercise was very useful to me, and the knowledge gained when creating my own framework turned out to be very helpful when debugging problem models.
How does the framework simplify code? Speaking abstractly, it eliminates the need to write the same code again and again. Specifically, the most convenient feature of the deep learning framework is support for automatic backpropagation and automatic optimization. This allows you to write only direct distribution code, and the framework will automatically take care of the back distribution and correction of weights. Most modern frameworks even simplify code that implements direct distribution by offering high-level interfaces for defining typical layers and loss functions.
Introduction to Tensors
Tensors are an abstract form of vectors and matrices
Until that moment, we used vectors and matrices as the main structures. Let me remind you that a matrix is a list of vectors, and a vector is a list of scalars (single numbers). A tensor is an abstract representation of nested lists of numbers. A vector is a one-dimensional tensor. The matrix is a two-dimensional tensor, and structures with a large number of dimensions are called n-dimensional tensors. So, let's start creating a new deep learning framework by defining a base type, which we'll call Tensor:
import numpy as np class Tensor (object): def __init__(self, data): self.data = np.array(data) def __add__(self, other): return Tensor(self.data + other.data) def __repr__(self): return str(self.data.__repr__()) def __str__(self): return str(self.data.__str__()) x = Tensor([1,2,3,4,5]) print(x) [1 2 3 4 5] y = x + x print(y) [2 4 6 8 10]
This is the first version of our basic data structure. Note that it stores all numerical information in the NumPy array (self.data) and supports a single tensor operation (addition). Adding additional operations is not difficult at all; just add additional functions with the corresponding functionality to the Tensor class.
Introduction to automatic gradient calculation (autograd)
Previously, we performed manual back propagation. Now let's make it automatic!
In chapter 4, we introduced derivatives. Since then, we have manually calculated these derivatives in each new neural network. Let me remind you that this is achieved by reverse movement through the neural network: first, the gradient at the output of the network is calculated, then this result is used to calculate the derivative in the previous component, and so on, until the correct gradients are determined for all weights in the architecture. This logic for calculating gradients can also be added to the tensor class. The following shows what I had in mind.
import numpy as np class Tensor (object): def __init__(self, data, creators=None, creation_op=None): self.data = np.array(data) self.creation_op = creation_op self.creators = creators self.grad = None def backward(self, grad): self.grad = grad if(self.creation_op == "add"): self.creators[0].backward(grad) self.creators[1].backward(grad) def __add__(self, other): return Tensor(self.data + other.data, creators=[self,other], creation_op="add") def __repr__(self): return str(self.data.__repr__()) def __str__(self): return str(self.data.__str__()) x = Tensor([1,2,3,4,5]) y = Tensor([2,2,2,2,2]) z = x + y z.backward(Tensor(np.array([1,1,1,1,1])))
This method introduces two innovations. First, each tensor receives two new attributes. creators is a list of any tensors used to create the current tensor (defaults to None). That is, if the tensor z is obtained by adding the other two tensors, x and y, the creators attribute of the tensor z will contain the tensors x and y. creation_op is a companion attribute that stores the operations used in the process of creating this tensor. That is, the instruction z = x + y will create a computational graph with three nodes (x, y and z) and two edges (z -> x and z -> y). In this case, each edge is signed by an operation from creation_op, that is, add. This graph helps organize the recursive backward propagation of gradients.
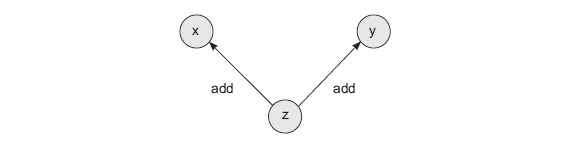
The first innovation in this implementation is the automatic creation of a graph during each mathematical operation. If we take z and perform another operation, the graph will be continued in a new variable referencing z.
The second innovation in this version of the Tensor class is the ability to use a graph to calculate gradients. If you call the z.backward () method, it will pass the gradient for x and y, taking into account the function with which the z (add) tensor was created. As shown in the example above, we pass the gradient vector (np.array ([1,1,1,1,1]]) to z, and that one applies it to its parents. As you probably remember from Chapter 4, backward propagation through addition means applying backward propagation. In this case, we have only one gradient to add to x and y, so we copy it from z to x and y:
print(x.grad) print(y.grad) print(z.creators) print(z.creation_op) [1 1 1 1 1] [1 1 1 1 1] [array([1, 2, 3, 4, 5]), array([2, 2, 2, 2, 2])] add
The most remarkable feature of this form of automatic gradient calculation is that it works recursively - each vector calls the .backward () method of all its parents from the self.creators list:

»More details on the book can be found on the publisher’s website
» Contents
» Excerpt
25% off coupon for hawkers - Deep Learning
Upon payment of the paper version of the book, an electronic book is sent by e-mail.
All Articles