Dirty assembler hacks 6502
This article lists some of the tricks that participants in my little Commodore 64 programming contest used. The rules of the competition were simple: create a C64 executable (PRG) file that draws two lines to form the image below. The one whose file is smaller in size won.

Competition entries were published in open tweets and in private messages that contained only bytes of the PRG file and an MD5 hash.
List of participants with links to the source code:
(If I missed someone, please let me know, I will update the list).
The rest of the article is devoted to some assembler tricks that were used in the competition.
Graphics C64 works by default in 40x25 character encoding mode. The framebuffer in RAM is divided into two arrays:
To set a character, you save the byte to the on-screen RAM, at
(for example,
). Color RAM is initialized by default in light blue (color 14): this is the color we use for the lines, that is, the color RAM can be left without touch.
You control the colors of the border and background using the memory I / O registers in
(border) and
(background).
Drawing two lines is pretty easy if you directly program the slope of a fixed line. Here is a C implementation that draws lines and flushes the contents of the screen to stdout (
is used to make the code work on a PC):
The screen codes above are
(blank) and
(filled 8 × 8 block). If run, you will see an ASCII picture with two lines:
The same is trivially implemented in assembler:
It turns out PRG pretty large size of 286 bytes.
Before diving into optimization, we make a few observations.
Firstly, we work on C64 with the ROM routines in place. There are tons of routines that can be useful. For example, clearing the screen with
.
Secondly, address calculations on an 8-bit processor such as 6502 can be cumbersome and eat a lot of bytes. This processor also does not have a multiplier, so a calculation like
usually includes either a bunch of logical shifts or a lookup table that also eats bytes. To avoid multiplying by 40, it’s best to advance the screen cursor incrementally:
We continue to add the slope of the line to the fixed counter
, and when 8-bit addition sets the carry flag, add 40.
Here is an incremental assembler approach:
With 82 bytes, it's still pretty hefty. One obvious problem is 16-bit address calculations. Set the
value for indirect
:
We translate
to the next line by adding 40:
Of course, this code can be optimized, but what if you get rid of 16-bit addresses at all? Let's see how to do it.
Instead of building a line in the on-screen RAM, we draw only in the last screen line Y = 24 and scroll up the whole screen, calling the ROM scroll function with
!
Here's how xloop is optimized:
This is how the rendering looks:

This is one of my favorite tricks in this program. Almost all the contestants found it on their own.
The code for storing pixel values ends like this:
This is encoded in the following sequence of 14 bytes:
Using self-modifying code (SMC), you can write this more compactly:
... which is encoded at 13 bytes:
It was considered normal in the competition to make wild assumptions about the work environment. For example, that the line drawing is the first thing that starts after turning on the C64 power, and there are no requirements for a clean output back to the BASIC command line. Therefore, everything that you find in the initial environment when entering PRG can and should be used to your advantage:
In the same way, when calling some KERNAL ROM procedures, you can take full advantage of any side effects: returned CPU flags, temporary zeropage values, etc.
After the first optimizations, let's look for something interesting in machine memory:
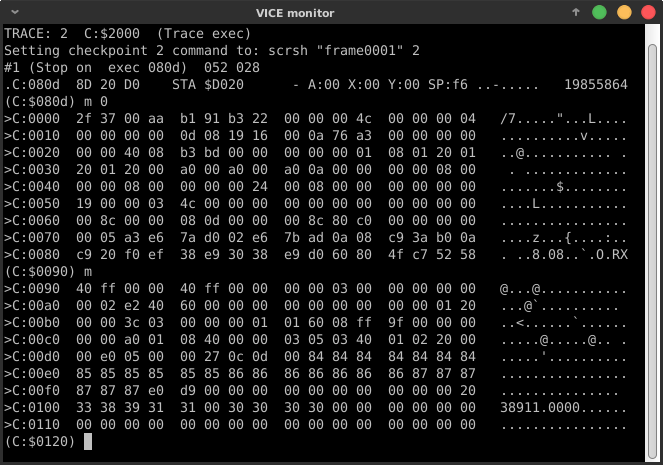
Zeropage really contains some useful values for our purposes:
This will save a few bytes during initialization. For example:
Since
contains the value 39, you can specify it to the counter
, getting rid of the LDA / STA pair:
Philip, the winner of the contest, takes this to an extreme. Recall the address of the last character of the string
(==
). This value is not present in zeropage during initialization. However, as a side effect of how the scrolling routine from ROM uses temporary zeropage values, the addresses
at the output of the function will contain the value
. Therefore, for storing a pixel, instead of
you can use one shorter of the indirectly indexed addressing
.
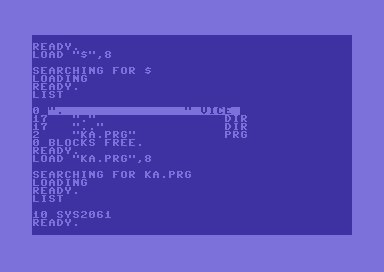
A typical C64 PRG binary contains the following:
The main boot sequence looks like this (addresses
):
Without going into details about the BASIC tokenized memory layout , this sequence more or less corresponds to '10 SYS 2061 '. Address
(
) is where our actual machine code program runs when the BASIC interpreter executes the SYS command.
It just seems that 14 bytes is too much. Philip, Matlev and Geir used several tricky tricks to completely get rid of the main sequence. This requires loading the PRG with
, since
ignores the PRG load address (first two bytes) and always loads at
.
Two methods were used here:
The trick is to
into the processor stack at
value that indicates our desired entry point. This is done by creating a PRG that starts with a 16-bit pointer to our code and loading the PRG at
:
As soon as the BASIC loader (see the code after disassembly ) has finished loading and wants to return to the calling object using
, it returns directly to our PRG.
This is a little easier to explain simply by looking at the PRG after disassembling.
Pay attention to the last line (
). The JMP instruction starts at
with a jump address of
.
When this code is loaded into memory starting at address
, the value
written to addresses
. Well, this location has a special meaning: it contains a pointer to the “BASIC wait cycle” (see the C64 memory card for more details). Downloading PRG overwrites it with
and therefore, when the BASIC interpreter after a warm reset tries to go to the wait loop, it never enters this loop, but instead gets into the rendering program!
Petri discovered another BASIC launch trick that allows you to enter your own constants in zeropage. In this method, you manually create your own tokenized BASIC start sequence and encode the constants in the line numbers of the BASIC program. At the input, the BASIC line numbers, ahem, that is, your constants will be stored in the addresses
. Very clever!
Here is a slightly simplified version of x-loop that only prints one line and then stops execution:
But there is a mistake. When we drew the last pixel, it is NO longer possible to scroll the screen. Thus, additional branches are needed to stop scrolling after writing the last pixel:
The control flow is very similar to what the C compiler will produce from a structured program. The code to skip the last scroll introduces a new
instruction that takes 3 bytes. Conditional jumps are only two bytes in length, since they encode jump addresses using a relative 8-bit operand with direct addressing.
JMP to “skip the last scroll” can be avoided by moving the scroll call up to the top of the loop and slightly changing the control flow structure. Here's how Philip implemented it:
This completely eliminates one three-byte JMP and converts the other JMP to a two-byte conditional branch, saving a total of 4 bytes.
Some elements do not use a line slope counter, but rather compress the bits into an 8-bit constant. Such packaging is based on the fact that the position of the pixel along the line corresponds to a repeating 8-pixel pattern:
This translates to a fairly compact assembler. However, tilt counter options are usually even smaller.
Here is the 34-byte contest winning program from Philip. Most of the above tricks work well in his code:
As soon as the contest ended, everyone shared their code and notes - and a series of lively discussions took place on how to improve it further. After the deadline, several more options were presented:
Be sure to look - there are several real pearls.
Thank you for reading. And special thanks to Matlev, Phil, Geir, Petri, Jamie, Ian and David for participating (I hope that I didn’t miss anyone - it was really difficult to track all the mentions on Twitter!)
PS Petri called my contest "annual", so, uh, probably see you next year.
Competition entries were published in open tweets and in private messages that contained only bytes of the PRG file and an MD5 hash.
List of participants with links to the source code:
- Philip Heron ( code - 34 bytes, winner)
- Geir Straume ( code - 34 bytes)
- Petri Hakkinen ( code - 37 bytes)
- Matlev Raksenblatts ( code - 38 bytes)
- Jan Ahrenius ( code - 48 bytes)
- Jamie Fuller ( code - 50 bytes)
- David A. Gershman ( code - 53 bytes)
- Janne Hellsten ( code - 56 bytes)
(If I missed someone, please let me know, I will update the list).
The rest of the article is devoted to some assembler tricks that were used in the competition.
The basics
Graphics C64 works by default in 40x25 character encoding mode. The framebuffer in RAM is divided into two arrays:
-
$0400
(Screen RAM, 40x25 bytes)
-
$d800
(Color RAM, 40x25 bytes)
To set a character, you save the byte to the on-screen RAM, at
$0400
(for example,
$0400+y*40+x
). Color RAM is initialized by default in light blue (color 14): this is the color we use for the lines, that is, the color RAM can be left without touch.
You control the colors of the border and background using the memory I / O registers in
$d020
(border) and
$d021
(background).
Drawing two lines is pretty easy if you directly program the slope of a fixed line. Here is a C implementation that draws lines and flushes the contents of the screen to stdout (
malloc()
is used to make the code work on a PC):
#include <stdint.h> #include <stdio.h> #include <stdlib.h> void dump(const uint8_t* screen) { const uint8_t* s = screen; for (int y = 0; y < 25; y++) { for (int x = 0; x < 40; x++, s++) { printf("%c", *s == 0xa0 ? '#' : '.'); } printf("\n"); } } void setreg(uintptr_t dst, uint8_t v) { // *((uint8_t *)dst) = v; } int main() { // uint8_t* screenRAM = (uint_8*)0x0400; uint8_t* screenRAM = (uint8_t *)calloc(40*25, 0x20); setreg(0xd020, 0); // Set border color setreg(0xd021, 0); // Set background color int yslope = (25<<8)/40; int yf = yslope/2; for (int x = 0; x < 40; x++) { int yi = yf >> 8; // First line screenRAM[x + yi*40] = 0xa0; // Second line (X-mirrored) screenRAM[(39-x) + yi*40] = 0xa0; yf += yslope; } dump(screenRAM); }
The screen codes above are
$20
(blank) and
$a0
(filled 8 × 8 block). If run, you will see an ASCII picture with two lines:
## .................................... ## .. # .................................. # .. ... ## .............................. ## ... ..... # ............................ # ..... ...... ## ........................ ## ...... ........ ## .................... ## ........ .......... # .................. # .......... ........... ## .............. ## ........... ............. # ............ # ............. .............. ## ........ ## .............. ................ ## .... ## ................ .................. # .. # .................. ................... ## ................... .................. # .. # .................. ................ ## .... ## ................ .............. ## ........ ## .............. ............. # ............ # ............. ........... ## .............. ## ........... .......... # .................. # .......... ........ ## .................... ## ........ ...... ## ........................ ## ...... ..... # ............................ # ..... ... ## .............................. ## ... .. # .................................. # .. ## .................................... ##
The same is trivially implemented in assembler:
!include "c64.asm" +c64::basic_start(entry) entry: { lda #0 ; black color sta $d020 ; set border to 0 sta $d021 ; set background to 0 ; clear the screen ldx #0 lda #$20 clrscr: !for i in [0, $100, $200, $300] { sta $0400 + i, x } inx bne clrscr ; line drawing, completely unrolled ; with assembly pseudos lda #$a0 !for i in range(40) { !let y0 = Math.floor(25/40*(i+0.5)) sta $0400 + y0*40 + i sta $0400 + (24-y0)*40 + i } inf: jmp inf ; halt }
It turns out PRG pretty large size of 286 bytes.
Before diving into optimization, we make a few observations.
Firstly, we work on C64 with the ROM routines in place. There are tons of routines that can be useful. For example, clearing the screen with
JSR $E544
.
Secondly, address calculations on an 8-bit processor such as 6502 can be cumbersome and eat a lot of bytes. This processor also does not have a multiplier, so a calculation like
y*40+i
usually includes either a bunch of logical shifts or a lookup table that also eats bytes. To avoid multiplying by 40, it’s best to advance the screen cursor incrementally:
int yslope = (25<<8)/40; int yf = yslope/2; uint8_t* dst = screenRAM; for (int x = 0; x < 40; x++) { dst[x] = 0xa0; dst[(39-x)] = 0xa0; yf += yslope; if (yf & 256) { // Carry set? dst += 40; yf &= 255; } }
We continue to add the slope of the line to the fixed counter
yf
, and when 8-bit addition sets the carry flag, add 40.
Here is an incremental assembler approach:
!include "c64.asm" +c64::basic_start(entry) !let screenptr = $20 !let x0 = $40 !let x1 = $41 !let yf = $60 entry: { lda #0 sta x0 sta $d020 sta $d021 ; kernal clear screen jsr $e544 ; set screenptr = $0400 lda #<$0400 sta screenptr+0 lda #>$0400 sta screenptr+1 lda #80 sta yf lda #39 sta x1 xloop: lda #$a0 ldy x0 ; screenRAM[x] = 0xA0 sta (screenptr), y ldy x1 ; screenRAM[39-x] = 0xA0 sta (screenptr), y clc lda #160 ; line slope adc yf sta yf bcc no_add ; advance screen ptr by 40 clc lda screenptr adc #40 sta screenptr lda screenptr+1 adc #0 sta screenptr+1 no_add: inc x0 dec x1 bpl xloop inf: jmp inf }
With 82 bytes, it's still pretty hefty. One obvious problem is 16-bit address calculations. Set the
screenptr
value for indirect
screenptr
:
; set screenptr = $0400 lda #<$0400 sta screenptr+0 lda #>$0400 sta screenptr+1
We translate
screenptr
to the next line by adding 40:
; advance screen ptr by 40 clc lda screenptr adc #40 sta screenptr lda screenptr+1 adc #0 sta screenptr+1
Of course, this code can be optimized, but what if you get rid of 16-bit addresses at all? Let's see how to do it.
Trick 1. Scrolling!
Instead of building a line in the on-screen RAM, we draw only in the last screen line Y = 24 and scroll up the whole screen, calling the ROM scroll function with
JSR $E8EA
!
Here's how xloop is optimized:
lda #0 sta x0 lda #39 sta x1 xloop: lda #$a0 ldx x0 ; hardcoded absolute address to last screen line sta $0400 + 24*40, x ldx x1 sta $0400 + 24*40, x adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: inc x0 dec x1 bpl xloop
This is how the rendering looks:
This is one of my favorite tricks in this program. Almost all the contestants found it on their own.
Trick 2. Self-modifying code
The code for storing pixel values ends like this:
ldx x1 ; hardcoded absolute address to last screen line sta $0400 + 24*40, x ldx x0 sta $0400 + 24*40, x inc x0 dec x1
This is encoded in the following sequence of 14 bytes:
0803: A6 22 LDX $22 0805: 9D C0 07 STA $07C0,X 0808: A6 20 LDX $20 080A: 9D C0 07 STA $07C0,X 080D: E6 22 INC $22 080F: C6 20 DEC $20
Using self-modifying code (SMC), you can write this more compactly:
ldx x1 sta $0400 + 24*40, x addr0: sta $0400 + 24*40 ; advance the second x-coord with SMC inc addr0+1 dec x1
... which is encoded at 13 bytes:
0803: A6 22 LDX $22 0805: 9D C0 07 STA $07C0,X 0808: 8D C0 07 STA $07C0 080B: EE 09 08 INC $0809 080E: C6 22 DEC $22
Trick 3. Operation state 'power on'
It was considered normal in the competition to make wild assumptions about the work environment. For example, that the line drawing is the first thing that starts after turning on the C64 power, and there are no requirements for a clean output back to the BASIC command line. Therefore, everything that you find in the initial environment when entering PRG can and should be used to your advantage:
- Registers A, X, Y are taken as zeros
- All CPU flags cleared
- Zeropage content (addresses
$00
-$ff
)
In the same way, when calling some KERNAL ROM procedures, you can take full advantage of any side effects: returned CPU flags, temporary zeropage values, etc.
After the first optimizations, let's look for something interesting in machine memory:
Zeropage really contains some useful values for our purposes:
-
$d5
: 39 / $ 27 == line length - 1
-
$22
: 64 / $ 40 == initial value for the line slope counter
This will save a few bytes during initialization. For example:
!let x0 = $20 lda #39 ; 0801: A9 27 LDA #$27 sta x0 ; 0803: 85 20 STA $20 xloop: dec x0 ; 0805: C6 20 DEC $20 bpl xloop ; 0807: 10 FC BPL $0805
Since
$d5
contains the value 39, you can specify it to the counter
x0
, getting rid of the LDA / STA pair:
!let x0 = $d5 ; nothing here! xloop: dec x0 ; 0801: C6 D5 DEC $D5 bpl xloop ; 0803: 10 FC BPL $0801
Philip, the winner of the contest, takes this to an extreme. Recall the address of the last character of the string
$07C0
(==
$0400+24*40
). This value is not present in zeropage during initialization. However, as a side effect of how the scrolling routine from ROM uses temporary zeropage values, the addresses
$D1-$D2
at the output of the function will contain the value
$07C0
. Therefore, for storing a pixel, instead of
STA $07C0,x
you can use one shorter of the indirectly indexed addressing
STA ($D1),y
.
Trick 4. Download Optimization
A typical C64 PRG binary contains the following:
- First 2 bytes: download address (usually
$0801
)
- 12 bytes of the BASIC boot sequence
The main boot sequence looks like this (addresses
$801-$80C
):
0801: 0B 08 0A 00 9E 32 30 36 31 00 00 00 080D: 8D 20 D0 STA $D020
Without going into details about the BASIC tokenized memory layout , this sequence more or less corresponds to '10 SYS 2061 '. Address
2061
(
$080D
) is where our actual machine code program runs when the BASIC interpreter executes the SYS command.
It just seems that 14 bytes is too much. Philip, Matlev and Geir used several tricky tricks to completely get rid of the main sequence. This requires loading the PRG with
LOAD"*",8,1
, since
LOAD"*",8
ignores the PRG load address (first two bytes) and always loads at
$0801
.
Two methods were used here:
- Stack trick
- BASIC Vector Warm Reset Trick
Stack trick
The trick is to
$01F8
into the processor stack at
$01F8
value that indicates our desired entry point. This is done by creating a PRG that starts with a 16-bit pointer to our code and loading the PRG at
$01F8
:
* = $01F8 !word scroll - 1 ; overwrite stack scroll: jsr $E8EA
As soon as the BASIC loader (see the code after disassembly ) has finished loading and wants to return to the calling object using
RTS
, it returns directly to our PRG.
BASIC Vector Warm Reset Trick
This is a little easier to explain simply by looking at the PRG after disassembling.
02E6: 20 EA E8 JSR $E8EA 02E9: A4 D5 LDY $D5 02EB: A9 A0 LDA #$A0 02ED: 99 20 D0 STA $D020,Y 02F0: 91 D1 STA ($D1),Y 02F2: 9D B5 07 STA $07B5,X 02F5: E6 D6 INC $D6 02F7: 65 90 ADC $90 02F9: 85 90 STA $90 02FB: C6 D5 DEC $D5 02FD: 30 FE BMI $02FD 02FF: 90 E7 BCC $02E8 0301: 4C E6 02 JMP $02E6
Pay attention to the last line (
JMP $02E6
). The JMP instruction starts at
$0301
with a jump address of
$0302-$0303
.
When this code is loaded into memory starting at address
$02E6
, the value
$02E6
written to addresses
$0302-$0303
. Well, this location has a special meaning: it contains a pointer to the “BASIC wait cycle” (see the C64 memory card for more details). Downloading PRG overwrites it with
$02E6
and therefore, when the BASIC interpreter after a warm reset tries to go to the wait loop, it never enters this loop, but instead gets into the rendering program!
Other tricks with the launch of BASIC
Petri discovered another BASIC launch trick that allows you to enter your own constants in zeropage. In this method, you manually create your own tokenized BASIC start sequence and encode the constants in the line numbers of the BASIC program. At the input, the BASIC line numbers, ahem, that is, your constants will be stored in the addresses
$39-$3A
. Very clever!
Gimmick 5. Custom Control Flow
Here is a slightly simplified version of x-loop that only prints one line and then stops execution:
lda #39 sta x1 xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: dec x1 bpl xloop ; intentionally halt at the end inf: jmp inf
But there is a mistake. When we drew the last pixel, it is NO longer possible to scroll the screen. Thus, additional branches are needed to stop scrolling after writing the last pixel:
lda #39 sta x1 xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x dec x1 ; skip scrolling if last pixel bmi done adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: jmp xloop done: ; intentionally halt at the end inf: jmp inf
The control flow is very similar to what the C compiler will produce from a structured program. The code to skip the last scroll introduces a new
JMP abs
instruction that takes 3 bytes. Conditional jumps are only two bytes in length, since they encode jump addresses using a relative 8-bit operand with direct addressing.
JMP to “skip the last scroll” can be avoided by moving the scroll call up to the top of the loop and slightly changing the control flow structure. Here's how Philip implemented it:
lda #39 sta x1 scroll: jsr $e8ea xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x adc yf sta yf dec x1 ; doesn't set carry! inf: bmi inf ; hang here if last pixel! bcc xloop ; next pixel if no scroll bcs scroll ; scroll up and continue
This completely eliminates one three-byte JMP and converts the other JMP to a two-byte conditional branch, saving a total of 4 bytes.
Trick 6. Lines with bit compression
Some elements do not use a line slope counter, but rather compress the bits into an 8-bit constant. Such packaging is based on the fact that the position of the pixel along the line corresponds to a repeating 8-pixel pattern:
int mask = 0xB6; // 10110110 uint8_t* dst = screenRAM; for (int x = 0; x < 40; x++) { dst[x] = 0xA0; if (mask & (1 << (x&7))) { dst += 40; // go down a row } }
This translates to a fairly compact assembler. However, tilt counter options are usually even smaller.
Winner
Here is the 34-byte contest winning program from Philip. Most of the above tricks work well in his code:
ov = $22 ; == $40, initial value for the overflow counter ct = $D5 ; == $27 / 39, number of passes. Decrementing, finished at -1 lp = $D1 ; == $07C0, pointer to bottom line. Set by the kernal scroller ; Overwrite the return address of the kernal loader on the stack ; with a pointer to our own code * = $01F8 .word scroll - 1 scroll: jsr $E8EA ; Kernal scroll up, also sets lp pointer to $07C0 loop: ldy ct ; Load the decrementing counter into Y (39 > -1) lda #$A0 ; Load the PETSCII block / black col / ov step value sta $D020, y ; On the last two passes, sets the background black p1: sta $07C0 ; Draw first block (left > right line) sta (lp), y ; Draw second block (right > left line) inc p1 + 1 ; Increment pointer for the left > right line adc ov ; Add step value $A0 to ov sta ov dec ct ; Decrement the Y counter bmi * ; If it goes negative, we're finished bcc loop ; Repeat. If ov didn't overflow, don't scroll bcs scroll ; Repeat. If ov overflowed, scroll
But why dwell on 34 bytes?
As soon as the contest ended, everyone shared their code and notes - and a series of lively discussions took place on how to improve it further. After the deadline, several more options were presented:
Be sure to look - there are several real pearls.
Thank you for reading. And special thanks to Matlev, Phil, Geir, Petri, Jamie, Ian and David for participating (I hope that I didn’t miss anyone - it was really difficult to track all the mentions on Twitter!)
PS Petri called my contest "annual", so, uh, probably see you next year.
All Articles