The film in which there was soil. Yandex research and a brief history of search by meaning
Sometimes people turn to Yandex to find a movie whose name popped out of their heads. They describe the plot, memorable scenes, vivid details: for example, [what’s the name of the film where a man chooses a red or blue pill]. We decided to study the descriptions of forgotten films and find out what is most remembered by people in the movies.
Today we will not only share a link to our study , but also briefly talk about how Yandex's semantic search evolved. You will find out what technologies help the search to find the answer even when it is simply impossible to formulate the exact request.
And we also added riddle sliders with examples of real people's requests - feel like a search engine and try to guess the answer.
All search engines began with a word search. Yandex already at the start was able to take into account the morphology of the Russian language, but it was still the same search for words from a query on pages on the network. We kept lists of all known pages for each word. If the request contained a phrase, then it was enough to cross the word lists - here's the answer. It worked great in those days when there were few sites, and the question of ranking was not yet so acute.
Runet developed, sites became more and more. Two more factors were added to the word crossing factor. On the one hand, the users themselves helped us. We began to consider which sites and for what queries they choose. There is no exact match of words, but does the site solve the human problem? This is a useful signal. On the other hand, links between sites that helped evaluate the importance of the pages came to the rescue.
Three factors are very few. Especially when they are often tried by the very talented search engine optimizers. But digesting more by hand was difficult. And here began the era of machine learning. In 2009, we introduce Matrixnet based on gradient boosting (later this technology formed the basis of the more advanced open source library CatBoost ).
Since then, there have been more and more factors, because we no longer have to look for the relationships between them manually. A car did it for us.
To tell about all subsequent changes in the Search, not only the post, but also the books will be enough, so we will try to focus on the most revealing ones.
Ranking is not only a comparison of query words and page for a long time. Two examples.
Back in 2014, we introduced the technology of document annotation with characteristic queries. Suppose in the past there was a request [a series from Brazil about the meat king], for which a good answer is already known. Then another user enters a query [the Brazilian series in which there were a meat king and a milk king], for which the machine does not yet know the answer. But these queries have many common words. This is a signal that the page found on the first request may be relevant on the second.
Another example. Let's take inquiries [the Brazilian series in which there were a meat king and a milk king] and [a fatal inheritance series]. Of the total, they have only one word - "series", and this is not enough for explicit matching of requests. In this case, we began to take into account the history of the search. If two dissimilar requests are in demand the same sites in the issuance, then we can assume that the requests are interchangeable. This is useful because now we will use the text of both queries to search to find more useful pages. But this only works for repeated queries when there is already at least some statistics. What to do with new requests?
The lack of statistics can be compensated by content analysis. And in the analysis of homogeneous data (text, voice, images), neural networks show themselves best. In 2016, we first told the Habr community about the Palekh technology , which became the starting point for the wider use of neural networks in the Search.
We began to train the neural network to compare the semantic (semantic) proximity of query texts and page title. Two texts are represented in the form of vectors in multidimensional space so that the cosine of the angle between them well predicts the likelihood of a person choosing a page, and therefore semantic proximity. This allows you to evaluate the closeness of the meanings of even those texts in which there is no intersection of words.
In the same way, we began to compare query texts in order to identify links between them. A real example from under the hood of a search engine: for a query [the American series about how methamphetamine is boiled] it is the neural network that finds the phrases [meaning bad] and [breaking bad] as similar in meaning.
Requests and headers are already good, but we did not give up hope to use neural networks in the full text of the pages. In addition, when we receive a user request, we begin to select the best pages among millions of index pages, but in Palekh we used neural network models only at the very latest stages of ranking (L3) - to about 150 of the best documents. This can lead to the loss of good answers.

The reason is predictable - limited resources and high requirements for response speed. The strict limitations of the calculations are connected with a simple fact: you cannot force the user to wait. But then we came up with something.
In 2017, we presented the search update Korolev, which included not only the expanded use of neural networks, but also serious work on architecture to save resources. In more detail, with schemes of layers and other details we already told in another post on Habré, but now we will remind the main thing.
Instead of taking the title of the document and calculating its semantic vector during query execution, you can pre-calculate this vector and save it in the search database. In other words, we can do a substantial part of the work in advance. Of course, at the same time, we needed more space for storing vectors, but this saved us CPU time. But that is not all.
We built an additional index. It is based on the hypothesis: if you take a sufficiently large list of the most relevant documents for each word or phrase for a query of several words, then among them there will be documents that are relevant at the same time to all words. In practice, this means this. For all words and popular word pairs, an additional index is generated with a list of pages and their preliminary relevance to the query. That is, we transfer part of the work from stage L0 to the indexing stage and, again, save.
As a result, a change in architecture and redistribution of loads allowed us to use neural networks not only at the L3 stage, but also for L2 and L1. Moreover, the ability to form a vector in advance and with less stringent performance requirements allowed us to use not only the page title, but also its text.
Further more. Over time, we began to use neural networks at the earliest stage of ranking. We teach neural networks to identify implicit patterns in word order and their relative positions. And even to reveal the semantic similarity of texts in different languages. Each of these areas is drawn to a separate article, and we will try to return with them in the near future.
Today, we once again recalled how search engines learn to find the answer in the conditions of a vague query and lack of information. Searching for films by their description is not only a special case of such requests, but also a great topic for research . From it you will learn: what is most remembered by people in cinema, with which different genres and cinematographs of different countries are associated, which plot moves make a special impression.
Today we will not only share a link to our study , but also briefly talk about how Yandex's semantic search evolved. You will find out what technologies help the search to find the answer even when it is simply impossible to formulate the exact request.
And we also added riddle sliders with examples of real people's requests - feel like a search engine and try to guess the answer.
All search engines began with a word search. Yandex already at the start was able to take into account the morphology of the Russian language, but it was still the same search for words from a query on pages on the network. We kept lists of all known pages for each word. If the request contained a phrase, then it was enough to cross the word lists - here's the answer. It worked great in those days when there were few sites, and the question of ranking was not yet so acute.
Runet developed, sites became more and more. Two more factors were added to the word crossing factor. On the one hand, the users themselves helped us. We began to consider which sites and for what queries they choose. There is no exact match of words, but does the site solve the human problem? This is a useful signal. On the other hand, links between sites that helped evaluate the importance of the pages came to the rescue.
Three factors are very few. Especially when they are often tried by the very talented search engine optimizers. But digesting more by hand was difficult. And here began the era of machine learning. In 2009, we introduce Matrixnet based on gradient boosting (later this technology formed the basis of the more advanced open source library CatBoost ).
Since then, there have been more and more factors, because we no longer have to look for the relationships between them manually. A car did it for us.
To tell about all subsequent changes in the Search, not only the post, but also the books will be enough, so we will try to focus on the most revealing ones.
Ranking is not only a comparison of query words and page for a long time. Two examples.
Back in 2014, we introduced the technology of document annotation with characteristic queries. Suppose in the past there was a request [a series from Brazil about the meat king], for which a good answer is already known. Then another user enters a query [the Brazilian series in which there were a meat king and a milk king], for which the machine does not yet know the answer. But these queries have many common words. This is a signal that the page found on the first request may be relevant on the second.
Another example. Let's take inquiries [the Brazilian series in which there were a meat king and a milk king] and [a fatal inheritance series]. Of the total, they have only one word - "series", and this is not enough for explicit matching of requests. In this case, we began to take into account the history of the search. If two dissimilar requests are in demand the same sites in the issuance, then we can assume that the requests are interchangeable. This is useful because now we will use the text of both queries to search to find more useful pages. But this only works for repeated queries when there is already at least some statistics. What to do with new requests?
The lack of statistics can be compensated by content analysis. And in the analysis of homogeneous data (text, voice, images), neural networks show themselves best. In 2016, we first told the Habr community about the Palekh technology , which became the starting point for the wider use of neural networks in the Search.
We began to train the neural network to compare the semantic (semantic) proximity of query texts and page title. Two texts are represented in the form of vectors in multidimensional space so that the cosine of the angle between them well predicts the likelihood of a person choosing a page, and therefore semantic proximity. This allows you to evaluate the closeness of the meanings of even those texts in which there is no intersection of words.
An example of layer architecture for the curious 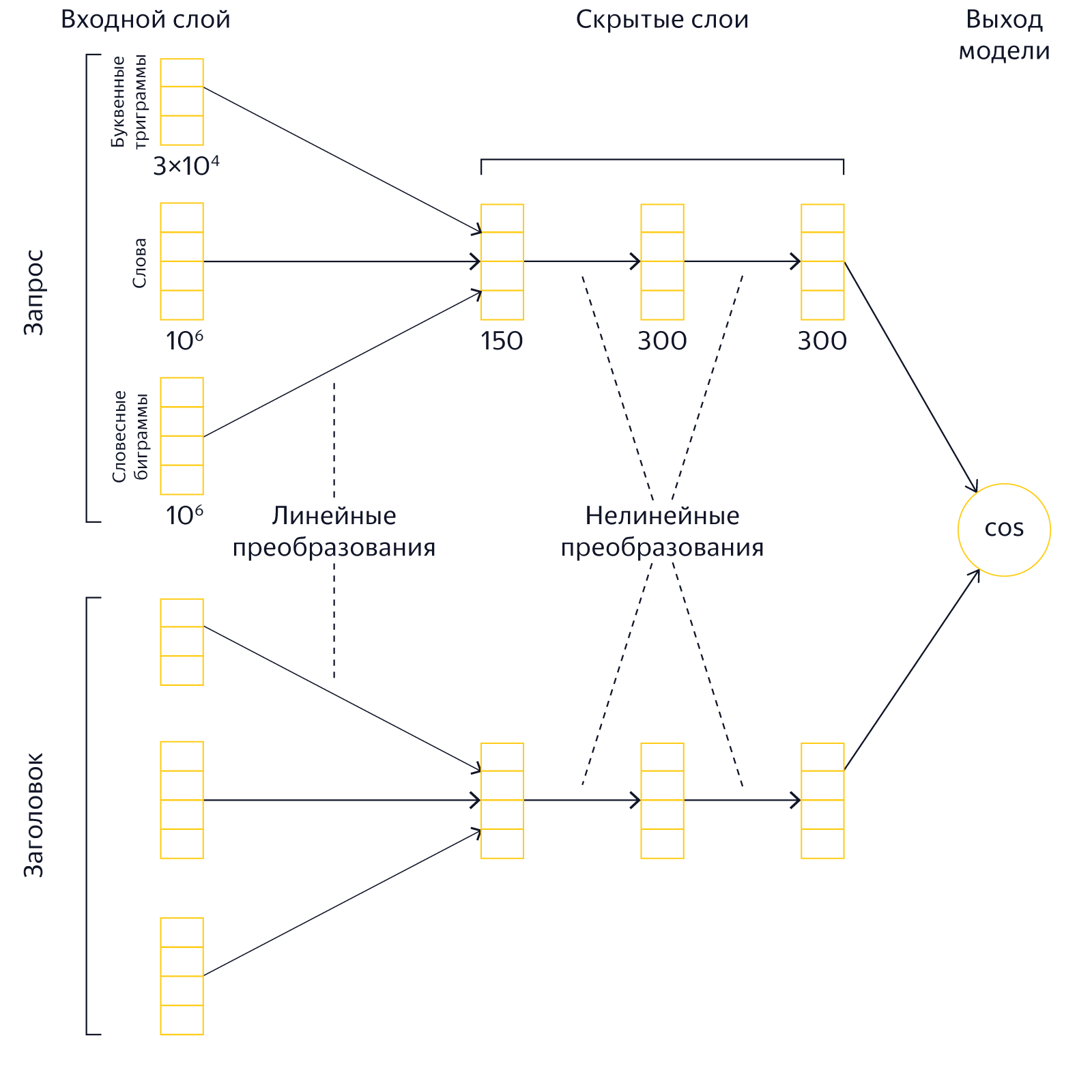
In the same way, we began to compare query texts in order to identify links between them. A real example from under the hood of a search engine: for a query [the American series about how methamphetamine is boiled] it is the neural network that finds the phrases [meaning bad] and [breaking bad] as similar in meaning.
Requests and headers are already good, but we did not give up hope to use neural networks in the full text of the pages. In addition, when we receive a user request, we begin to select the best pages among millions of index pages, but in Palekh we used neural network models only at the very latest stages of ranking (L3) - to about 150 of the best documents. This can lead to the loss of good answers.
The reason is predictable - limited resources and high requirements for response speed. The strict limitations of the calculations are connected with a simple fact: you cannot force the user to wait. But then we came up with something.
In 2017, we presented the search update Korolev, which included not only the expanded use of neural networks, but also serious work on architecture to save resources. In more detail, with schemes of layers and other details we already told in another post on Habré, but now we will remind the main thing.
Instead of taking the title of the document and calculating its semantic vector during query execution, you can pre-calculate this vector and save it in the search database. In other words, we can do a substantial part of the work in advance. Of course, at the same time, we needed more space for storing vectors, but this saved us CPU time. But that is not all.
Another scheme for the curious 
We built an additional index. It is based on the hypothesis: if you take a sufficiently large list of the most relevant documents for each word or phrase for a query of several words, then among them there will be documents that are relevant at the same time to all words. In practice, this means this. For all words and popular word pairs, an additional index is generated with a list of pages and their preliminary relevance to the query. That is, we transfer part of the work from stage L0 to the indexing stage and, again, save.
As a result, a change in architecture and redistribution of loads allowed us to use neural networks not only at the L3 stage, but also for L2 and L1. Moreover, the ability to form a vector in advance and with less stringent performance requirements allowed us to use not only the page title, but also its text.
Further more. Over time, we began to use neural networks at the earliest stage of ranking. We teach neural networks to identify implicit patterns in word order and their relative positions. And even to reveal the semantic similarity of texts in different languages. Each of these areas is drawn to a separate article, and we will try to return with them in the near future.
Today, we once again recalled how search engines learn to find the answer in the conditions of a vague query and lack of information. Searching for films by their description is not only a special case of such requests, but also a great topic for research . From it you will learn: what is most remembered by people in cinema, with which different genres and cinematographs of different countries are associated, which plot moves make a special impression.
All Articles