Professional regular expression lexical analysis
Text parsing always starts with lexical analysis or tokenizing. There is an easy way to solve this problem for almost any language using regular expressions. Another use of the good old regexp.
I often encounter the task of parsing texts. For simple tasks, such as analyzing a user-entered value, the basic functionality of regular expressions is sufficient. For complex and heavy tasks like writing a compiler or static code analysis, you can use specialized tools (AntLR, JavaCC, Yacc). But I often come across tasks of an intermediate level, when there are not enough regular expressions, but I don’t feel like pulling heavy tools into the project. In addition, these tools usually work at the compile-time stage and at run-time do not allow changing analysis parameters (for example, forming a list of keywords from a file or database table).
As an example, I’ll give a task that arose during the process of accelerating SQL queries . We analyzed the logs of our SQL queries and wanted to find "bad" queries according to certain rules. For example, queries in which the same field is checked for a set of values using OR
name = 'John' OR name = 'Michael' OR name = 'Bob'
We wanted to replace such requests with
name IN ('John', 'Michael', 'Bob')
Regular expressions can no longer cope, but I also did not want to create a full-fledged SQL parser using AntLR. It would be possible to break the request text into tokens and use simple code to make parsing without any specialized tools.
This problem can be solved using the basic functionality of regular expressions. Let's try to split the SQL query into tokens. We’ll look at a simplified version of SQL so as not to overload the text with details. To create a full-fledged SQL lexer, you will have to write slightly more complex regular expressions.
Here is a set of expressions for basic SQL language tokens:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
I want to pay attention to the regular expression for keyword
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
It has two features.
- The \ b operator is used at the beginning and at the end, for example, so as not to cut off the or prefix from the word organization , which is a keyword and which some regex engines will separate into a separate token without using the \ b operator.
- all words are grouped by non-capturing brackets (?:) that do not capture the match. This will be used in the future so as not to violate the indexing of partial regular expressions within the general expression.
Now you can combine all these expressions into a single whole, using the grouping and operator |
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
Now you can try to apply this expression to an SQL expression, for example to such
SELECT count(id) -- count of 'Johns' FROM person WHERE name = 'John'
Here is the result on the Regex Tester. By clicking on the link you can play around with the expression and the result of the analysis. It can be seen that, for example, SELECT immediately corresponds to a 1-group, which corresponds to the keyword type.
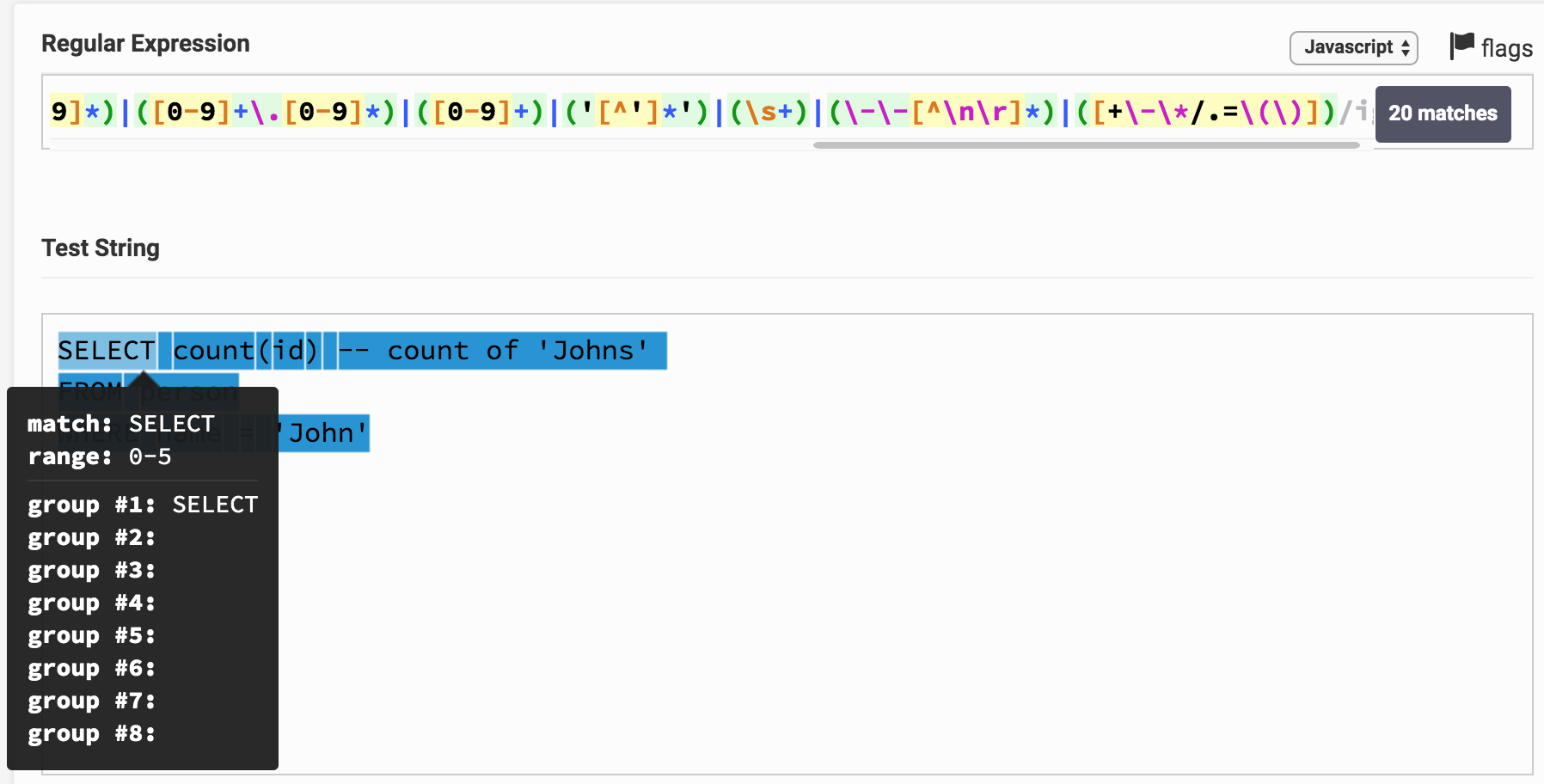
You may notice that the entire text of the request turned out to be divided into substrings and each corresponds to a certain group. By group number, you can correlate it with the type of token (token).
Making the given algorithm into a program in any programming language that supports regular expressions is not difficult. Here is a small class that implements this in Java.
package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; /** * . * , . */ public class RegexTokenizer implements Enumeration<Token> { // , private final String content; // private final ITokenType[] tokenTypes; private final Matcher matcher; // private int currentPosition = 0; /** * @param content * @param tokenTypes */ public RegexTokenizer(String content, ITokenType[] tokenTypes) { this.content = content; this.tokenTypes = tokenTypes; // List<String> regexList = new ArrayList<>(); for (int i = 0; i < tokenTypes.length; i++) { ITokenType tokenType = tokenTypes[i]; regexList.add("(?<g" + i + ">" + tokenType.getRegex() + ")"); } String regex = regexList.stream().collect(Collectors.joining("|")); Pattern pattern = Pattern.compile(regex, Pattern.CASE_INSENSITIVE); // matcher = pattern.matcher(content); matcher.find(); } @Override public boolean hasMoreElements() { return currentPosition < content.length(); } @Override public Token nextElement() { boolean found = currentPosition > matcher.start() ? matcher.find() : true; int start = found ? matcher.start() : content.length(); int end = found ? matcher.end() : content.length(); if(found && currentPosition == start) { currentPosition = end; // - for (int i = 0; i < tokenTypes.length; i++) { String si = "g" + i; if (matcher.start(si) == start && matcher.end(si) == end) { return createToken(content, tokenTypes[i], start, end); } } } throw new IllegalStateException(" " + currentPosition); } /** * - , , , * (, ) * @param content * @param tokenType * @param start * @param end * @return - */ protected Token createToken(String content, ITokenType tokenType, int start, int end) { return new Token(content.substring(start, end), tokenType, start); } /** * SQL */ public enum SQLTokenType implements ITokenType { KEYWORD("\\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\\b"), ID("[A-Za-z][A-Za-z0-9]*"), REAL_NUMBER("[0-9]+\\.[0-9]*"), NUMBER("[0-9]+"), STRING("'[^']*'"), SPACE("\\s+"), COMMENT("\\-\\-[^\\n\\r]*"), OPERATION("[+\\-\\*/.=\\(\\)]"); private final String regex; SQLTokenType(String regex) { this.regex = regex; } @Override public String getRegex() { return regex; } } public static void main(String[] args) { String s = "select count(id) -- count of 'Johns' \n" + "FROM person\n" + "where name = 'John'"; RegexTokenizer tokenizer = new RegexTokenizer(s, SQLTokenType.values()); while(tokenizer.hasMoreElements()) { Token token = tokenizer.nextElement(); System.out.println(token.getText() + " : " + token.getType()); } } } /** * - () */ public class Token { // private final String text; // private final ITokenType type; // private final int start; public Token(String text, ITokenType type, int start) { this.text = text; this.type = type; this.start = start; } public String getText() { return text; } public ITokenType getType() { return type; } public int getStart() { return start; } } /** * */ public interface ITokenType { /** * */ String getRegex(); }
In this class, the algorithm is implemented using named groups, which are not present in all engines. This feature allows you to access groups not by indexes, but by name, which is slightly more convenient than accessing by index.
On my I7 2.3GHz, this class demonstrates an analysis speed of 5-20 MB per second (depending on the complexity of the expressions). The algorithm can be parallelized by analyzing several files at once, increasing the overall speed of work.
I found several similar algorithms on the network, but I came across options that do not form a common regular expression, but consistently apply regular expressions for each type of token to the beginning of the line, then discard the found token from the beginning of the line and again try to apply all regexps. This works about 10-20 times slower, requires more memory and the algorithm is more complicated. I achieved greater speed of work only using my regular expression implementation based on DFA ( deterministic finite state machine). In regex engines, NKA is usually used - a nondeterministic finite state machine). DFA is 2-3 times faster, but regular expressions for it are more difficult to write due to a limited set of operators.
In my example for SQL, I simplified regular expressions a little and the resulting tokenizer cannot be considered a full-fledged lexical analyzer of SQL queries, but the purpose of the article is to show the principle, and not create a real SQL tokenizer. I used this approach in my practice and created full-fledged lexical analyzers for SQL, Java, C, XML, HTML, JSON, Pascal and even COBOL (I had to tinker with it).
Here are a few simple rules for writing regular expressions for lexical analysis.
- If the same token can be assigned to different types (for example, any keyword can be recognized as an identifier), then a narrower type must be defined at the beginning. Then the regular expression for it will be applied first and it will determine the type of token. For example, in my example, the keywords are defined before id and the select token will be recognized as keyword , not id
- Define longer tokens first, then shorter ones. For example, you first need to define <= , > = and then separate > , < , = In this case, the text <= will be correctly recognized as a single token of the operator "less than or equal to", and not two separate tokens < and =
- Learn to use lookahead and lookbehind . For example, the * character in SQL has the meaning of a multiplication operator and an indication of all fields in a table. You can separate these two cases using a simple lookbehind , for example, here regexp (? <=. \ S | select \ s ) * finds the character * only in the value "all fields of the table".
- It is sometimes useful to define regular expressions for errors that occur in the text. For example, if you do syntax highlighting, you can define the type of token "unfinished string" as
'[^\n\r]*
. In the process of editing text, the user may not have time to close the quotation mark in the string, but your tokenizer will be able to correctly recognize this situation and correctly highlight it.
Using these rules and applying this algorithm, you can quickly split the text into tokens for almost any language.
All Articles