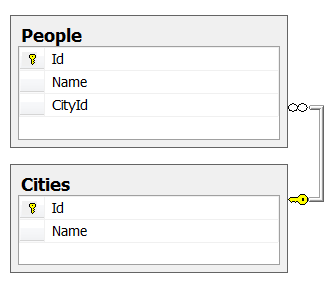
歴史は世界と同じくらい古いです。 2つのテーブル:
- 都市-100のユニークな都市。
- 人々-1000万人。 一部の人々にとって、都市は示されないかもしれません。
都市ごとの人の分布は均一です。
フィールドCites.Id、Cites.Name、People .CityIdのインデックスは在庫があります。
引用順に並べ替えられた最初の100人のエントリを選択する必要があります。
袖をまくり、元気に書きます:
select top 100 p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name
そうすることで、次のようなものが得られます。
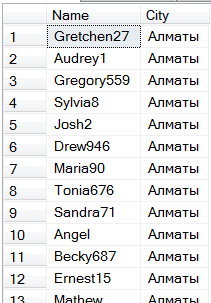
で... 6秒。 (MS SQL 2008 R2、i5 / 4Gb)
しかし、どのように! から6秒はどこですか?! 最初の100エントリには、アルマトイのみが含まれることがわかっています。 結局、1000万のエントリがあり、これは都市が10万を占めることを意味します。そうでない場合でも、リストの最初の都市を選択し、少なくとも100人の住民がいるかどうかを確認できます。
統計があるSQL Serverがこれを行わない理由:
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
このクエリは、1秒未満で約10万件のレコードを返します! 必要な100件のレコードがあると確信し、非常に迅速に提供しました。
ただし、MSSQLは計画に従ってすべてを実行します。 そして、彼は「純粋な熱核毒」という計画を立てている(c)。
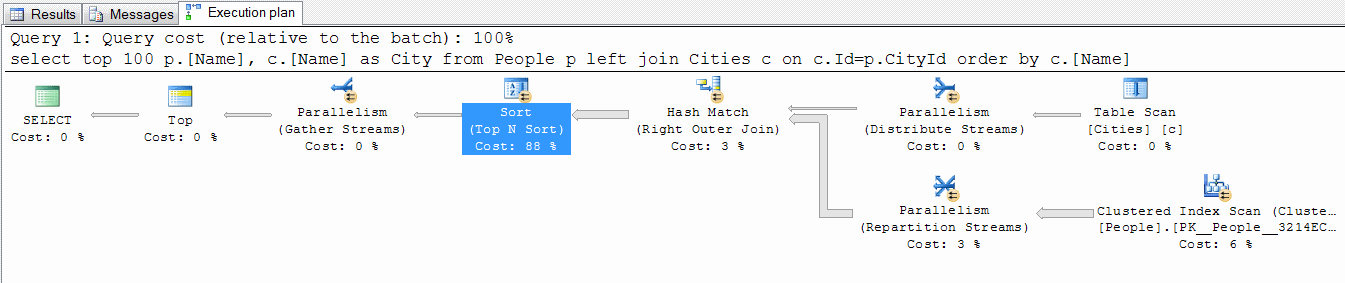
専門家への質問:
SQLクエリを修正する方法、またはサーバーで何らかのアクションを実行して、最初の要求で結果を10倍高速化する方法
PS
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
[CityId] uniqueidentifier
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
PPS
足はどこから成長しますか:
タスクは非常に現実的です。 主な本質を持つテーブルがあり、「星」の原則に従って多くの次元がそこから離れています。 ユーザーはそれをグリッドに表示し、フィールドでソートする必要があります。
メインテーブルの特定のサイズから開始して、同じ(極端な)値を持つウィンドウ(「Almaty」など)が選択されるという事実にソートが縮小されますが、システムはひどく遅くなり始めます。
Peopleテーブルの小さいサイズと大きいテーブルの両方で効果的に機能する1つのパラメーター化されたクエリが必要です。
PPPS
興味深いことに、CityがNotNullで、InnerJoinが使用された場合、リクエストは即座に実行されます。
興味深いことに、CityフィールドがNotNullで、LeftJoinが使用されていたとしても、リクエストは遅くなります。
コメントのアイデア:最初に、すべてのInnerJoinを選択してから、Union by Null値を選択します。 明日、これと他のクレイジーなアイデアをチェックします)
PPPPS試しました。 うまくいきました!
ヘルプAS
(
People pからCityとしてトップ100 p.Name、c.Nameを選択します
INNERはc.Id = p.CityIdで都市cに参加します
c.Name ASCによる注文
UNION
People pからCityとしてNULLを選択します。
WHERE p.CityIdはNULLです
)
SELECT TOP 100 * FROMヘルプ
同じ条件下で150ミリ秒を与えます! ありがとうholem 。