エントリー
3年前から単体テストを書いており、1年前から専門的にTDDに携わっています。 そしてこれまでずっと、私はそのようなことに何度も気づきました:ユニットテストはある種のコードに対して簡単かつ自然に書かれ、コードの品質を大幅に改善しますが、他の人にとっては多大な努力を必要としますが、欠陥を排除するのにはまったく役立ちませんが、むしろ反対です-リファクタリングまたは改善を試みる場合にのみ障害になります。
そして、これは驚くことではありません。人生のさまざまな分野で確立されたアプローチのほとんどすべては、実際には特定の状況でのみ有効であり、他の条件ではその利点を失います。 それがここにあります:多くの開発者は、単体テストを書くことが常に良いとは限らないことに同意するでしょう。
したがって、このメモを書く目的は次のとおりです。
- この特定のコードの単体テストの価値を実際に決定するものを理解します。
- 各機能ブロックの実装を開始する前に、100%のカバレッジの必要性とテストの義務的な記述に関する広範な意見の矛盾を示します。
テストの利点
単体テストを行うことの利点のリストは、主に2つに減らすことができます。 次のことができます。
- コードを作成するときにコードを直接設計します。
- 実装が意図したとおりに機能することを確認してください。
しかし、疑問が生じます。なぜ追加の設計および検証システムが必要なのか、コード自体にはデバイスとアプリケーションの動作に関する情報が含まれていないのですか? また、テストが根本的に新しい情報を提供しない場合、設計されたシステムの正確性をどのように確認しますか? 「再現性の原則」( DRY )はどうですか?
私にとって個人的には、タスクの最初の考えでその実装のコードが明白にならない場合、それを書くために座って考えなければならないことを意味し、追加のヘルプ(例えば、ユニットテストの形で)、すべてが正しく動作することを確認できるようにします、非常に役立つでしょう。 たとえば、ビジネスルールのシステムを開発している場合、または複雑な階層式を解析している場合、考えられるすべてのコード動作の分岐をすぐに追跡することはできません。 そのような場合、単体テストは非常に価値があります。
逆もまた同様です。コードがシンプルで明白であり、一目でそれが何をするのかすぐに明らかな場合、単体テストの利点は無効になります。 たとえば、現在の日付と空きディスク領域を受け取り、このデータを別のメソッドに転送するメソッドを作成します。 この場合、コードはそれ自体を物語っています。追加の単体テストに追加するものは何もありません。
そのため、単体テストの利点は、コードの複雑度に直接依存します。
試験価格
製品のコストに影響する要因には次のものがあります。
- テストの作成に費やした時間。
- コードのリファクタリングまたは他の変更を行った後のテストの修正と最終化に費やされた時間。
- いくつかのテストが失敗し、書き直さなければならないという期待のために、コードを改善することへの恐怖。
もちろん、テストシステムをサポートするコストは、 さまざまな推奨事項に従うことで削減できますが、それでも比較的大きいままでかまいません。
私の観察によると、特定のコードの単体テストの総コストは、コードの残りの部分に存在する依存関係の数と非常に相関しています。 なぜだろう?
初期作成。 メソッドが他のブロックに依存せず、1つのパラメーターを取る通常の関数のように機能する場合、単体テストは入力データと出力データ間の対応のリストになります。 しかし、メソッドが多くのパラメーターを取り、クラスのプロパティを介して多くの外部サービスとやり取りする場合は、一連の偽(モック)オブジェクトを作成する必要があります。 しかし、この作業のコストは次の段落に比べて小さいです。
サポート。 コードブロックに存在する依存関係が多いほど、このコードが変更を余儀なくされることが多くなることが確立されました(これがコードの不安定性の判定方法です)。 そして、理由は明らかです。これらの依存関係のそれぞれについて、一定期間、そのシグネチャまたは動作が変更される可能性があり、その結果、コードと対応するテストを更新する必要が生じます。
これらの問題は、クリーンなインターフェースで作業しているときにIoC ( DI )を使用する場合にも同様に当てはまることに注意してください。
そのため、単体テストのコストは、コードセクションの依存関係の数に直接依存します。
テストのコストと利点のグラフィカルな表現
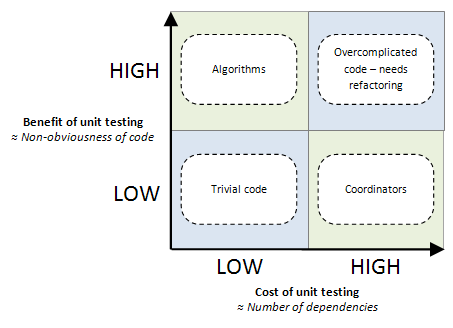
この意図的に簡略化された図は、4種類のコードを示しています。
- 少数の依存関係を持つ複雑なコード(左上のセクション)。 通常、これらはビジネスルールを記述したり、式の解析を実装したりする自己完結型のアルゴリズムです。 このタイプのコードは安価で簡単にテストできるため、単体テストに最も適しています。
- 多数の依存関係を持つ単純なコード(右下のセクション)。 このタイプのコードは、他のコードブロック間の相互作用をリンクおよび整理するように設計されているため、このサイトは「コーディネーター」として署名されています。 このようなコードのテストは採算が取れません。テストの作成には費用がかかりますが、実際的な利点はわずかです。 作業時間をより効率的に費やすことができます。
- 多くの依存関係を持つ複雑なコード(右上のセクション)。 そのようなコードのテストを書くことは、非常に危険なことを書くよりもかなり高価です。 原則として、ソリューションは2つの部分に分けることができます。複雑なロジックを組み込む部分(アルゴリズム)と、外部の依存関係を集中させる部分(コーディネーター)です。
- いくつかの依存関係がある通常の通常のコード(左下の領域)。 このタイプのコードについて心配する必要はありません。 経済的利益の観点からは、テストされるかどうかは問題ではありません。
最後に練習。 では、ASP.NET MVCはどうでしょうか?
ASP.NET MVCでは、一見したところアプリケーションロジックはコントローラーに配置するのが最も簡単です。 また、コントローラーにビジネスルールを押し込み続ける間、後者は非常に面倒になります。コントローラー自体に複雑なロジックが蓄積され、同時に多くのオブジェクトに依存するため、テストには十分な費用がかかります。 馬、人、またはむしろ、異なるアプリケーション層のタスク(いわゆるアンチパターン「シックコントローラー」 )がまとまります。
このような混乱を避けるために、アプリケーションロジックの独立した部分をモデルレベルのクラスに分解する必要があります(式はごめんなさい)。 次に、純粋なコントローラーの本来の目的と矛盾する部分を他の部分から分離し、それらをActionFilters、独自のModelBinders、およびActionResultsに配置できます。
このようにコントローラーを構成すればするほど、コントローラーはよりシンプル、クリーン、美しくなり、最終的にはアプリケーションの他のレイヤー間の相互作用を管理するコーディネーターが純粋な水に退化すると同時に、独自の追加ロジックなしで一貫したシステムに成長します。 言い換えれば、コントローラーの構造が優れているほど、ダイアグラムの右下部分に引き寄せられ、テストの感覚が失われます。
コントローラの目的は、さまざまなサービスのさまざまなAPIの単なる待ち合わせ場所にすることです。 このようなコントローラーのコードは簡単に読み取り可能で、多くの依存関係を結び付けます。 経済的利益の観点から、コントローラーの単体テストではなく、統合テストのリファクタリングと記述に時間をかけると、私の仕事ははるかに効果的であるという結論に達しました。
おわりに
誰かが私の言葉を誤解する可能性がある場合:実際、私はユニットテストやTDDに反対していません。 私の主なポイントは次のとおりです。
- 私自身の経験から判断すると、TDDを使用する場合の長期にわたる私の仕事の生産性は、TDDが経済的に有益なタイプのコードに対してのみ高くなります-少数の依存関係を持つ複雑なコード(アルゴリズムまたは自給自足のビジネス)ロジック);
- コードをアルゴリズム部分と調整部分に意図的に分割することもあります。そのため、最初の部分は非常に単純に単体テストの対象となり、2番目の部分は非常に明確で理解しやすく、単体テストは不要です。 典型的な例は、コントローラーからビジネスロジックを削除することです。
- 統合テストの実際的な価値をますます認識しています。 Webアプリケーションの場合、これには通常、いくつかのブラウザー自動化ツール( Selenium RCやWatiNなど )の使用が含まれます。 当然、これは単体テストをキャンセルしませんが、簡単なコードの単体テストを書くこの時間を殺すよりも、システム全体がスムーズに動作することを確認するために統合テストを書くのに1時間を費やすことをお勧めします、および基になるAPIが変更されるとすぐに変更される可能性があります。
上記のすべては、私の観察結果の単なる説明であり、あなたの観察結果と一致しない場合があります。
オリジナル記事
おそらく、スコット・ベルバー(スコット・ベルウェア)の言葉を思い出すだけである:「TDDはテストすることではなく、デザインすることだ」。