このプロジェクトは非常に古く、2003年に開始されました。 いくつかのことについて、「歴史的に」と言えます。 しかし、私は一般的な考え方が役立つと思います。
だから。 同社は菓子の卸売に従事しています。 卸売菓子はかなり具体的なビジネスです。 比較的低速では、大量のデータを処理する必要があります。 同社の顧客は、地域の村にある大規模な小売チェーンと小さな店の両方です。 さらに、膨大な種類の製品。 さらに、クライアントは、1つのスニーカーからクッキーキャリッジまで(マシュマロの半分が返品倉庫に到着した前例がありました(返品の理由が何であるかについては履歴がありません))、あらゆる量の商品を購入できます。
メインの会計システムは、dbfバージョンを備えた1C「Trade and Warehouse」7.0です。 彼女は商品の会計のタスクにうまく対処しています。 ただし、長期間にわたってレポートを取得することはほとんど不可能です。 このような試みはサーバーに深刻な負荷をかけ、1cオペレーターは問題を抱え始め、IT部門に苦情を申し立てます。
そのようなレポートの必要性は常にありました。 biプロジェクトを実装するための理想的な状況は、大量の情報とその分析に関心がある人々です。
まず、ユーザーが自分で情報を受け取る方法を示す短いビデオ。
ここから 5.25Mbをダウンロードして 、通常の品質でaviを視聴できます (6分)
2.64Mbの例をダウンロードして、ローカルキューブを操作できます。
またはここで 8Mb
実装方法:
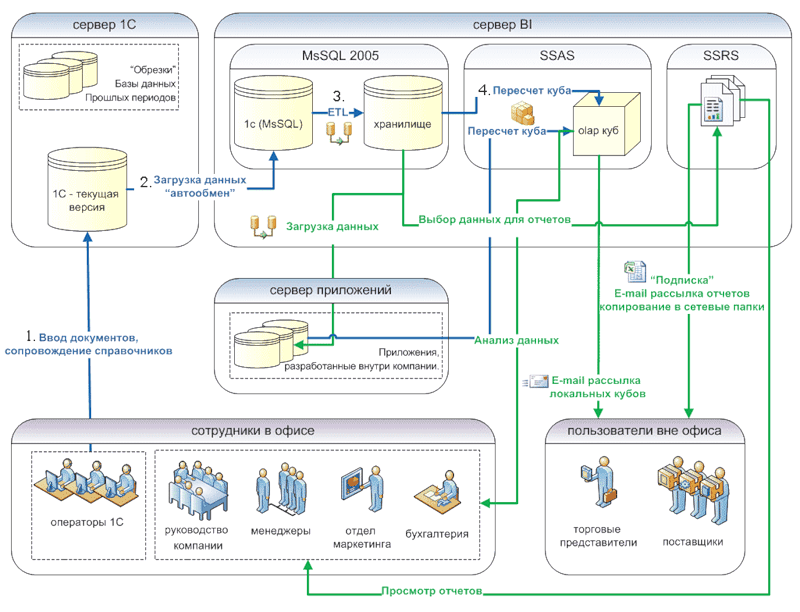
青色の矢印-情報がシステムに入力される方法、緑色-情報が将来使用される場合。
- 注文に関する情報は、システム1c-dbfバージョンに入力されます。
- データをダウンロード「自動交換」。 実際、これは追加のステップです。 データは、dbfデータベースから直接取得できます。 しかし、1cプログラマーは、標準(1秒間)のデータアップロードメカニズムの害は少ないと判断しました。
- 1日1回、過去1日間の変更が特別に準備されたMsSqlデータベース-ストレージにアップロードされます。 すべての情報がアップロードされるわけではなく、キューブに必要なものだけがアップロードされます。
原則として、「リポジトリ」を構築する必要はありません。 キューブのデータは、1cデータベース(MsSQLまたはdbf)から直接取得できます。 しかし、私の場合、1から過去の期間のデータが定期的に削除され、ディレクトリがクリアされます。 さらに、ストレージにロードする前に、データは少し「クリーニング」されます。
- キューブが再計算されます-データはキューブに分類されます。
ストレージからの情報は、キューブだけでなく、外部アプリケーションでも使用されます。たとえば、このデータは、給与の計算、支払いと配達の会計、マネージャーの作業計画に必要です。 同時に、これらの外部プログラムからのデータもキューブに分類されます。
オフィスの従業員は、キューブ(管理、マネージャー、マーケティング、経理)で作業します。 情報は、地域のさまざまな都市のサプライヤーおよび営業担当者にも送信されます。
どのユーザーもさまざまな方法で情報を取得できます。
- WebページまたはExcelで自分でレポートを作成する
最初はExcelのみが使用されましたが、Excelファイルが「ばらばら」であるという事実には多くの問題があり、情報を選択するために1つの「エントリポイント」を取得する必要がありました。
そのため、PivotTableを含むページが公開されるローカルサイトが作成されました。 「今ここで」数個の数字を取得したい従業員がこのサイトにアクセスし、必要な形式でレポートを作成します。 将来このレポートを使用する必要がある場合は、リクエストを書いてレポートをSSRSで公開するか、Excelで保存することができます。
- SQL Server Reporting Services(SSRS)で公開されている標準レポートを表示する
- ローカルキューブを取得し、社外のExcelを使用してデータを「回転」させる
- ニュースレターを購読し、SSRSから電子メールで標準レポートを受信します
- マーケティング部門もCubeSliceプログラムを使用しています。 その中で、ローカルキューブを自分で作成でき、Excelよりもはるかに便利です
ローカルキューブ
ユーザーが大量のデータを含むレポートを定期的に受信する必要がある場合があります。 たとえば、マーケティング部門は数十ページを含むExcelファイルの形式でサプライヤーにレポートを送信しました。
Olapは、そのような情報を受け取ったとして「投獄」されていません-非常に長い間、レポートが生成されています。
原則として、サプライヤは大きなレポートを扱うのに不便です。 そのため、ローカルキューブでの作業を試みた大多数は、このフォームでレポートを受け取ることに同意しました。 マーケティング部門が生成するレポートのリストは大幅に削減されました。 残りの重いレポートはSSRSに実装され、サブスクリプションが作成されました(レポートは自動的に生成され、スケジュールに従ってサプライヤーに送信されます)
主要なシステムパラメータ
サーバー構成:
プロセッサー:2xAMD Opteron 280
メモリー:4Gb
ディスクアレイ:
オペレーティングシステム:RAID 1(ミラー)2xSCSI 15k
データ:RAID 0 + 1 4xSCSI 10k
同意します、そのようなマシンは「強力な」サーバーとはほとんど言えません
データ量:
10GBストレージ、2002年のデータ
集約30%
多次元ベース350Mのサイズ
「大きな次元」のメンバー数:商品25,000、住所-2万
1日あたりのドキュメント数-400。ドキュメントの平均行数-30
会社が最終的に受け取ったもの:
長所
エンタープライズ管理用
これにより、ビジネス開発の一般的な法律を特定するために、「上から」状況を見ることができます。
組織全体の主要な指標の変化のダイナミクスを追跡し、部下の業績指標を迅速に評価するのに役立ちます。
マネージャー向け
独立して短時間で意思決定に必要な情報を受け取る能力。
作業の単純さ。 すべてのアクションは直感的です。
サプライヤー向け
情報を活用したインタラクティブな仕事の可能性
ITスペシャリストの観点から
日常業務を削減します。 ユーザーはほとんどのレポートを自分で受け取ります。
短所:
- 実装のコスト。 追加のハードウェアとソフトウェアが必要です。
- 訓練を受けた専門家の不足。 IT部門の従業員のトレーニングコスト。