定義上、MOを備えたシステムは安定していません。 特定の地域の人に勝つシステムでさえ、微妙な違いを作るときに単純な問題の解決策に対処できない場合があります。 たとえば、画像の摂動の問題を考えてみましょう。画像よりも分類しやすいニューラルネットワークは、ナマケモノがレースカーであると簡単に信じられ、慎重に計算されたノイズのほんの一部を画像に追加します。

通常の画像にオーバーレイされたときに競合する入力は、AIを混乱させる可能性があります。 2つの極端な画像は、ピクセルごとに0.0078以下しか異なりません。 最初は、ナマケモノとして99%の確率で分類されます。 2番目は99%の確率のレースカーのようなものです。
この問題は新しいものではありません。 プログラムには常にエラーがあります。 何十年もの間、プログラマーは単体テストから正式な検証まで、印象的な一連の技術を獲得してきました。 従来のプログラムでは、これらの方法はうまく機能しますが、数億個のパラメーターを含むことができるモデルの規模と構造の不足のため、これらのアプローチをMOモデルの厳密なテストに適合させることは非常に困難です。 これは、MOシステムの信頼性を確保するための新しいアプローチを開発する必要性を示唆しています。
プログラマーの観点から見ると、バグとは、仕様、つまりシステムの計画された機能を満たさない動作です。 AIの研究の一環として、MOシステムがトレーニングおよびテストセットだけでなく、システムの望ましい特性を記述する仕様のリストの要件を満たしているかどうかを評価するための手法を研究しています。 これらのプロパティの中には、入力データの十分に小さな変更、壊滅的な障害を防ぐ安全制限、または予測の物理法則への準拠に対する抵抗があります。
この記事では、MOシステムを堅牢で、望ましい仕様に確実に適合させるために、MOコミュニティが直面する3つの重要な技術的問題について説明します。
- 仕様への準拠の効果的な検証。 開発者とユーザーが要求するMOシステムがその特性(安定性や不変性など)に対応することを検証するための効果的な方法を研究しています。 モデルがこれらのプロパティから離れることができるケースを見つけるための1つのアプローチは、最悪の作業結果を体系的に検索することです。
- MOモデルを仕様に合わせてトレーニングします。 十分な量のトレーニングデータが存在する場合でも、標準のMOアルゴリズムは、操作が目的の仕様を満たさない予測モデルを作成できます。 トレーニングデータでうまく機能するだけでなく、目的の仕様を満たすように、トレーニングアルゴリズムを修正する必要があります。
- MOモデルが望ましい仕様に適合していることの正式な証明。 モデルがすべての可能な入力データの望ましい仕様を満たしていることを確認するためのアルゴリズムを開発する必要があります。 フォーマル検証の分野では数十年にわたってそのようなアルゴリズムを研究してきましたが、その印象的な進歩にもかかわらず、これらのアプローチは現代のMOシステムに拡張するのは容易ではありません。
望ましい仕様のモデル準拠を検証する
競争的な例に対する抵抗は、民間防衛のかなりよく研究された問題です。 主な結論の1つは、強力な攻撃の結果としてのネットワークのアクションを評価することの重要性と、非常に効果的に分析できる透明なモデルの開発です。 私たちは、他の研究者とともに、多くのモデルが競争力の弱い例に対して堅牢であることが判明しました。 ただし、より強力な競合例の場合、それらはほぼ0%の精度を提供します( Athalye et al。、2018 、 Uesato et al。、2018 、 Carlini and Wagner、2017 )。
ほとんどの作業は、教師による指導という文脈でのまれな失敗に焦点を当てていますが(これは主に画像の分類です)、これらのアイデアの適用を他の分野に拡大する必要があります。 壊滅的な障害を見つけるための競争力のあるアプローチを用いた最近の研究では、これらのアイデアを、強化されたトレーニングを受け、セキュリティ要件の高い場所で使用するために設計されたテストネットワークに適用します。 自律システムを開発する際の課題の1つは、1つのエラーが重大な結果を招く可能性があるため、わずかな障害の可能性でさえ許容範囲と見なされないことです。
私たちの目標は、(制御された環境で)そのようなエラーを事前に認識するのに役立つ「ライバル」を設計することです。 攻撃者が特定のモデルの最悪の入力データを効果的に決定できる場合、これにより、展開する前にまれな障害のケースをキャッチできます。 画像分類器の場合と同様に、弱い相手との作業方法を評価すると、展開中に誤った安心感が得られます。 このアプローチは、「レッドチーム」を使用したソフトウェア開発に似ています[レッドチーミング-脆弱性を検出するために攻撃者の役割を担うサードパーティの開発チームが関与します。 しかし、それは、侵入者によって引き起こされた障害の検索を超えており、たとえば、不十分な一般化のために自然に発生するエラーも含みます。
強化された学習ネットワークの競争力のあるテストへの2つの補完的なアプローチを開発しました。 最初の方法では、デリバティブを使用しない最適化を使用して、予想される報酬を直接最小化します。 2番目の方法では、敵対的価値の関数を学習します。これは、経験上、どの状況でネットワークが失敗するかを予測します。 次に、この学習した関数を使用して最適化を行い、最も問題のある入力データの評価に専念します。 これらのアプローチは、潜在的アルゴリズムの豊富で成長しているスペースのごく一部にすぎず、この分野の将来の発展に非常に興味があります。
どちらのアプローチも、ランダムテストよりも大幅に改善されています。 この方法を使用すると、数分で、以前は終日検索する必要があったか、おそらくまったく見つからなかった欠陥を検出することができます( 上里ら、2018b )。 また、競合テストでは、ランダムなテストセットでの評価から予想されるものと比較して、ネットワークの質的に異なる動作が明らかになる可能性があることもわかりました。 特に、我々の方法を使用して、3次元マップ上でオリエンテーションタスクを実行し、通常は人間レベルでこれに対処するネットワークは、予想外に単純な迷路でターゲットを見つけることができないことを発見しました( Ruderman et al。、2018 )。 また、私たちの仕事は、ライバルだけでなく、自然故障に対して安全なシステムを設計する必要性を強調しています。

ランダムなサンプルでテストを実施すると、失敗の可能性が高いカードはほとんど見られませんが、競合テストではそのようなカードの存在が示されます。 多くの壁を削除した後でも、つまり、元の壁と比較してマップを単純化した後でも、失敗の可能性は高いままです。
スペックモデルトレーニング
競合テストでは、仕様に違反する反例を見つけようとします。 多くの場合、これらの仕様とモデルの一貫性を過大評価しています。 数学的な観点から、仕様はネットワークの入力データと出力データの間で維持する必要がある一種の関係です。 上限と下限、またはいくつかの主要な入出力パラメーターの形式をとることができます。
この観察に触発されて、DeepMindのチーム( Dvijotham et al。、2018 ; Gowal et al。、2018 )、競合テストに不変のアルゴリズムに取り組みました。 これは幾何学的に説明することができます-仕様の最悪の違反を制限し( Ehlers 2017 、 Katz et al。2017 、 Mirman et al。、2018 )、入力のセットに基づいて出力スペースを制限できます。 この境界がネットワークパラメータによって微分可能であり、迅速に計算できる場合は、トレーニング中に使用できます。 その後、元の境界はネットワークの各層を介して伝播できます。
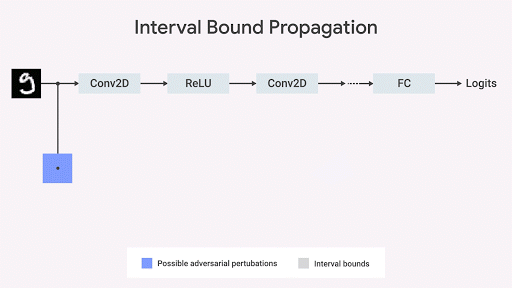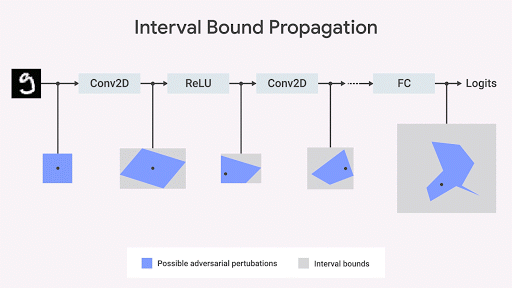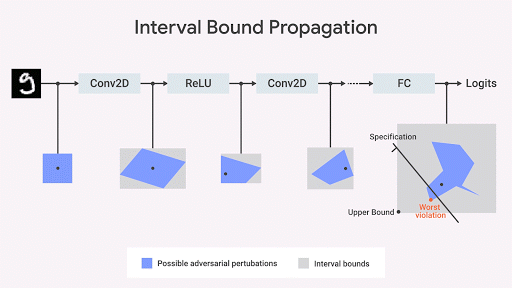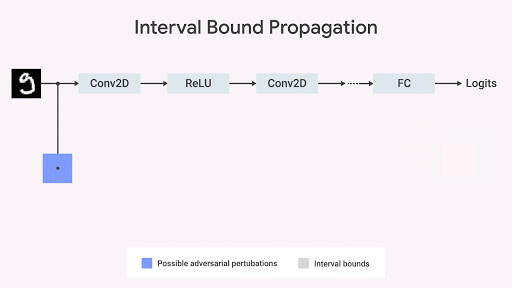
区間の境界の広がりは高速で効率的であり、以前に考えられていたものとは異なり、良好な結果が得られることを示しています( Gowal et al。、2018 )。 特に、MNISTおよびCIFAR-10データベースのセットで最も高度な画像分類器と比較して、エラーの数(つまり、敵が引き起こす可能性のあるエラーの最大数)を確実に削減できることを示します。
次の目標は、出力空間の過剰な近似を計算するために、正しい幾何学的抽象化を研究することです。 また、前述の不変性や物理法則の遵守など、目的の動作を記述するより複雑な仕様で確実に動作するようにネットワークをトレーニングしたいと考えています。
正式な検証
徹底したテストとトレーニングは、信頼できるMOシステムを作成する上で非常に役立ちます。 ただし、形式的に任意に大量のテストを行っても、システムの動作が私たちの望みに一致することを保証することはできません。 大規模モデルでは、天文学的な数の画像変更のため、特定の入力セット(たとえば、画像の小さな変更)のすべての可能な出力オプションを列挙するのは難しいようです。 ただし、トレーニングの場合と同様に、出力データのセットに幾何学的制約を設定するより効果的なアプローチを見つけることができます。 正式な検証は、DeepMindで進行中の研究の主題です。
MOコミュニティは、ネットワーク出力空間の正確な幾何学的境界を計算するためのいくつかの興味深いアイデアを開発しました(Katz et al。2017 、 Weng et al。、2018 ; Singh et al。、2018 )。 最適化と双対性に基づいた私たちのアプローチ( Dvijotham et al。、2018 )は、最適化の観点から検証問題を定式化することで構成されます。 双対性のアイデアが最適化に使用される場合、タスクは計算可能になります。 その結果、いわゆる切断面を使用して区間境界[区間境界伝搬]を移動するときに計算される境界を指定する追加の制約を取得します。 これは信頼できますが、不完全なアプローチです。対象のプロパティが満たされる場合もありますが、このアルゴリズムによって計算される境界は厳密ではないため、このプロパティの存在を正式に証明できます。 ただし、境界線を受け取った場合、このプロパティの違反がないことを正式に保証します。 図 以下に、このアプローチを図で示します。

このアプローチにより、より汎用的なネットワーク(アクティベーター機能、アーキテクチャ)、一般的な仕様、より複雑なGOモデル(生成モデル、ニューラルプロセスなど)、および競合の信頼性( Qin 、2018 )。
見込み
リスクの高い状況でのMOの展開には、独自の課題と困難があり、これには、起こりそうもないエラーを検出することが保証された評価技術の開発が必要です。 仕様に関する一貫したトレーニングは、トレーニングデータから暗黙的に仕様が生じる場合と比較して、パフォーマンスを大幅に改善できると考えています。 継続的な競争評価研究の結果、信頼できるトレーニングモデル、正式な仕様の検証を楽しみにしています。
現実のAIシステムが「すべてを正しく行う」ことを保証する自動化ツールを作成するには、多くの作業が必要になります。 特に、私たちは次の分野で進歩することを非常に喜んでいます。
- 競争力のある評価と検証のためのトレーニング。 AIシステムのスケーリングと複雑化により、AIモデルに十分に適合した競争力のある評価および検証アルゴリズムを設計することがますます困難になっています。 評価と検証にAIのフルパワーを使用できる場合、このプロセスは拡張できます。
- 競争力のある評価と検証のための公的に利用可能なツールの開発:エンジニアや他のAIを使用する人々に、この障害が広範囲に及ぶ負の結果をもたらす前に、AIシステムの考えられる障害モードに光を当てる使いやすいツールを提供することが重要です。 これには、競争力のある評価と検証アルゴリズムの標準化が必要です。
- 競合するサンプルの範囲を拡大します。 これまでのところ、競合例の研究のほとんどは、通常は写真の分野での小さな変化に対するモデルの安定性に焦点を当ててきました。 これは、競争力のある評価、信頼できるトレーニングおよび検証へのアプローチを開発するための優れたテストの場となっています。 私たちは、現実世界に直接関係するプロパティのさまざまな仕様の研究を開始し、この方向での将来の研究の結果を楽しみにしています。
- トレーニング仕様。 AIシステムの「正しい」動作を説明する仕様は、しばしば正確に定式化することが困難です。 複雑な動作が可能なインテリジェントシステムを作成し、非構造化環境で作業するにつれて、部分的に定式化された仕様を使用できるシステムの作成方法を学習し、フィードバックからさらなる仕様を取得する必要があります。
DeepMindは、MOシステムの責任ある開発と展開を通じて、社会に良い影響を与えることを約束しています。 開発者の貢献が確実に前向きであることを保証するために、多くの技術的障害に対処する必要があります。 私たちはこの分野に貢献するつもりであり、これらの問題を解決するためにコミュニティと協力して喜んでいます。