ログはシステムの重要な部分であり、期待どおりに機能する(または機能しない)ことを理解できます。 マイクロサービスアーキテクチャの条件では、ログの操作は特別なオリンピアードの別の分野になります。 すぐに一連の質問を解決する必要があります。
- アプリケーションからログを書き込む方法。
- ログを書き込む場所。
- ストレージおよび処理のためにログを配信する方法。
- ログを処理および保存する方法。
現在普及しているコンテナ化テクノロジーの使用により、問題を解決するためのオプションの分野に熊手の上に砂が追加されます。
ユーリ・ブッシュメレフの報告書の「この収集について」「ログの収集と配信の分野での地図の作成」
猫の下で誰が気にしてください。
私の名前はユーリ・ブッシュメレフです。 ラザダで働いています。 今日は、ログの作成方法、ログの収集方法、ログへの書き込みについて説明します。

どこから来たの? 私たちは誰ですか? Lazadaは、東南アジアの6か国で1番目のオンラインストアです。 これらの国はすべてデータセンターによって配布されています。 現在4つのデータセンターがありますが、なぜこれが重要なのですか? いくつかの決定は、センター間に非常に弱いリンクがあるという事実によるものだったからです。 マイクロサービスアーキテクチャがあります。 すでに80のマイクロサービスがあることを知って驚いた。 ログを使用してタスクを開始したとき、20個しかありませんでした。さらに、かなり大きなPHPレガシーがあります。 これはすべて、現時点でシステム全体で毎分600万を超えるメッセージを生成します。 さらに、私たちがどのようにそれと共に生きようとしているのか、そしてなぜそうなのかを示します。

なんとかしてこれらの600万のメッセージと共に生きなければなりません。 それらで何をすべきでしょうか? 必要な600万のメッセージ:
- アプリケーションから送信
- 配達を受け入れる
- 分析と保管のために提供します。
- 分析する
- どういうわけか店。

300万のメッセージが表示されたとき、私はほぼ同じ外観でした。 何セントから始めたからです。 アプリケーションログがそこに書き込まれていることは明らかです。 たとえば、データベースに接続できず、データベースに接続できましたが、何かを読むことができませんでした。 ただし、これに加えて、各マイクロサービスはアクセスログも書き込みます。 マイクロサービスに到着する各リクエストはログに分類されます。 なぜこれを行うのですか? 開発者はトレースできるようにしたいと考えています。 各アクセスログにはtraceidフィールドがあり、それに沿って特別なインターフェイスがチェーン全体をさらに巻き戻し、トレースを美しく表示します。 トレースは、リクエストがどのように送信されたかを示します。これにより、開発者は未確認のガベージを迅速に処理できます。

それと一緒に暮らすには? ここで、オプションの分野について簡単に説明します。一般にこの問題はどのように解決されますか。 ログの収集、転送、保存の問題を解決する方法。

アプリケーションから書く方法は? さまざまな方法があることは明らかです。 特に、ファッショナブルな仲間たちが言うように、ベストプラクティスがあります。 祖父が言ったように、2つの形式の古い学校があります。 他の方法があります。

ログを収集する状況はほぼ同じです。 この特定の部分を解決するための多くのオプションはありません。 すでに多くありますが、それほど多くはありません。

しかし、配信とその後の分析では、バリエーションの数が爆発的に増え始めます。 ここでは、各オプションについて説明しません。 主な選択肢は、このトピックに興味を持っているすべての人に聞かれると思います。

ラザダでそれをどのように行い、実際にすべてが始まったのかを示します。

1年前、私はLazadaに来て、彼らは私をログに関するプロジェクトに送りました。 こんな感じでした。 アプリケーションからのログは、stdoutおよびstderrに書き込まれました。 すべてがファッショナブルな方法で行われました。 しかし、その後、開発者はそれを標準フローから除外し、インフラストラクチャの専門家がそれを何らかの方法で整理します。 インフラストラクチャの専門家と開発者の間には、「ええと...わかりました。シェルでファイルにラップしてみましょう」と言ったリリース者もいます。 そして、これらはすべてコンテナ内にあるので、彼らはそれをコンテナ自体に包み、カタログをダウンロードしてそこに置いた。 私はそれが誰から来たのかはほぼ明らかだと思います。

もう少し見てみましょう。 これらのログをどのように配信しますか。 誰かがtd-agentを選択しました。これは実際には流fluentですが、それほど流fluentではありません。 私はまだこれら2つのプロジェクトの関係を理解していませんでしたが、それらはほぼ同じもののようです。 そして、この流れるようなRubyで書かれたログファイルを読み取り、一定の期間、JSONで解析しました。 それから彼はカフカにそれらを送りました。 また、各APIのKafkaでは、4つの個別のトピックがありました。 なぜ4? ライブがあるため、ステージングがあり、stdoutとstderrがあるためです。 開発者はそれらを産み、インフラストラクチャエンジニアはそれらをKafkaで作成する必要があります。 さらに、カフカは別の部門によって管理されていました。 したがって、チケットを作成して、各APIに4つのトピックを作成する必要がありました。 誰もがそれを忘れていました。 一般的に、ゴミや廃棄物がありました。
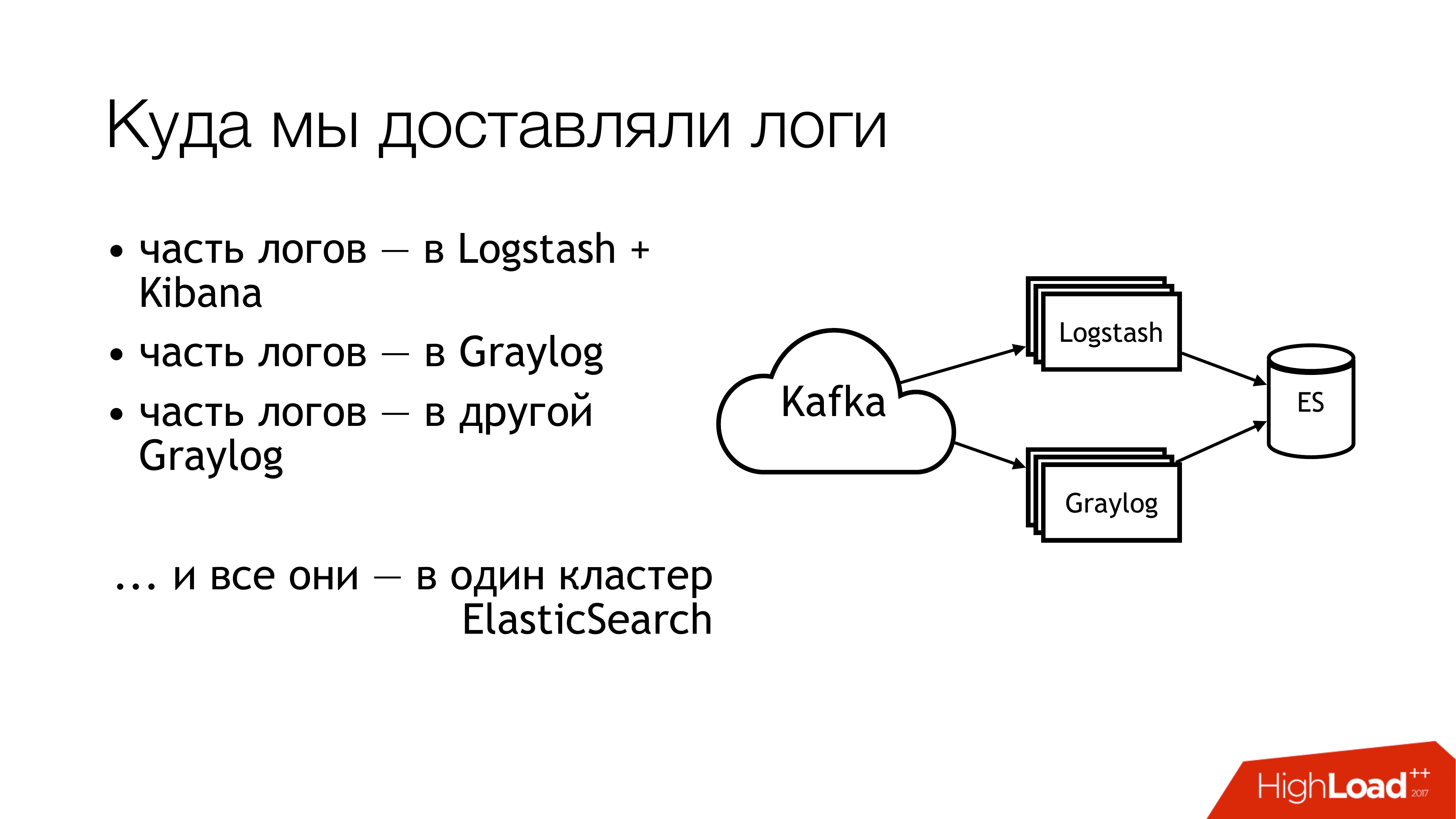
これで次に何をしましたか? それをカフカに送りました。 さらにカフカから、ログの半分がログスタッシュに飛んだ。 ログの残りの半分は共有されました。 一部は1つのGraylogに飛び、一部は別のGraylogに飛びました。 その結果、これらすべてが1つのElasticsearchクラスターに飛び込みました。 つまり、この混乱は最終的にそこに落ちました。 これをする必要はありません!

これは、上から遠くを見るとどのように見えるかです。 これをしないでください! ここで、番号は問題のある領域をすぐに示します。 実際にはもっと多くありますが、6つは非常に問題が多いため、何かを行う必要があります。 それらについて個別に説明します。

ここ(1,2,3)ではファイルを作成しているため、一度に3つのレーキがあります。
最初の(1)は、どこかに書き込む必要があるということです。 APIにファイルに直接書き込む機能を常に与えたいとは思わないでしょう。 APIはコンテナ内で隔離されることが望ましく、読み取り専用であることがさらに望ましいです。 私はシステム管理者であるため、これらのことについて少しだけ別の見方をしています。
2番目のポイント(2,3)-APIには多くのリクエストがあります。 APIは、大量のデータをファイルに書き込みます。 ファイルは成長しています。 それらを回転させる必要があります。 そうしないと、そこにディスクが届かないからです。 シェルを介してディレクトリにリダイレクトされるため、それらを回転させるのは良くありません。 移動することはできません。 記述子を再発見するようにアプリケーションに指示することはできません。 開発者はあなたを愚か者のように見ているからです。「記述子とは何ですか? 通常、stdoutに書き込みます。」 インフラストラクチャエンジニアは、logrotateでcopytruncateを作成しました。これにより、ファイルのコピーが作成され、元のファイルがコピーされます。 したがって、これらのコピープロセスの間に、ディスクスペースは通常終了します。
(4)異なるフォーマットがあり、異なるAPIを使用していました。 それらはわずかに異なっていましたが、正規表現は異なって書かなければなりませんでした。 これらはすべてPuppetによって制御されていたため、ゴキブリとクラスの大規模なバンドルがありました。 さらに、ほとんどの場合、td-agentはメモリを食べ、愚かで、動作しているふりをして、何もしません。 外では、彼が何もしていないことを理解することは不可能でした。 せいぜい、彼は倒れ、誰かが後で彼を拾います。 より正確には、アラートが到着し、誰かが手で確認します。

(6)そして、ほとんどのゴミと廃棄物-それはelasticsearchでした。 古いバージョンだったからです。 なぜなら、当時は専任のマスターがいなかったからです。 フィールドが交差する異種ログがありました。 異なるアプリケーションの異なるログを同じフィールド名で書き込むことができますが、同時に異なるデータが内部に存在する可能性があります。 つまり、1つのログには、フィールド(たとえば、レベル)に整数が含まれています。 別のログには、レベルフィールドに文字列が含まれています。 静的マッピングが存在しない場合、このような素晴らしいものが得られます。 elasticsearchでインデックスをローテーションした後、文字列を含む最初のメッセージが到着した場合、正常に動作しています。 そして、Integerで最初に到着した場合、Stringで到着した後続のメッセージはすべて単に破棄されます。 フィールドタイプが一致しないためです。

私たちはこれらの質問をし始めました。 私たちは有罪を探さないことにしました。

しかし、何かする必要があります! 明白なことは、基準を設定することです。 すでにいくつかの標準がありました。 少し後で入手したものもあります。 幸いなことに、その時点ですべてのAPIの統一されたログ形式が既に承認されていました。 サービスの相互作用の標準に直接書き込まれます。 したがって、ログを受信したい人はこの形式でログを書く必要があります。 誰かがこの形式でログを書き込まない場合、何も保証しません。
さらに、ログの記録、配信、および収集の方法に関する単一の標準を確立したいと思います。 実際に、それらをどこで書き、どのように配信するか。 理想的な状況は、プロジェクトが同じライブラリを使用する場合です。 Go用の個別のロギングライブラリと、PHP用の個別のライブラリがあります。 私たちが持っているすべての人-誰もがそれらを使用する必要があります。 現時点では、私たちはそれを80%獲得していると言えます。 しかし、サボテンを食べ続ける人もいます。
そして、(スライド上)「ログ配信用のSLA」とかろうじて登場しました。 彼はまだそこにいませんが、私たちはそれに取り組んでいます。 なぜなら、あなたがそのような場所にそのような形式で書き込み、1秒あたりNメッセージを超えない場合、そのような場所に配信する可能性が高いとインフラが言うのは非常に便利だからです。 これは頭痛の束を軽減します。 SLAがある場合、これはすばらしいです!

どのようにして問題を解決し始めましたか? 主なレーキはtd-agentでした。 ログの行き先が明確ではありませんでした。 彼らは配達されますか? 彼らは行きますか? どこにいるの? したがって、最初の項目はtd-agentを置き換えることが決定されました。 何に置き換えるかのオプションを簡単にスケッチしました。
流Flu 最初に、私は前の仕事で彼に出くわしました、そして、彼はまた定期的にそこに落ちました。 第二に、これはプロファイルのみで同じです。
Filebeat。 私たちにとってどのように便利でしたか? 彼が囲Goにいるという事実、そして囲weには多くの専門知識があります。 したがって、もしそうなら、どういうわけか自分で追加することができます。 したがって、我々はそれを取らなかった。 そのため、自分で書き直そうという誘惑はありませんでした。
sysadminの明らかな解決策は、この量のすべてのsyslog(syslog-ng / rsyslog / nxlog)です。
または、独自の何かを作成しますが、filebeatのように削除しました。 何かを書く場合は、ビジネスに役立つ何かを書く方が良いでしょう。 ログを配信するには、何かを用意しておくことをお勧めします。
したがって、選択は実際にはsyslog-ngとrsyslogの間の選択になりました。 Puppetにrsyslogのクラスがすでにあるという理由だけで、彼はrsyslogに傾倒しましたが、それらの間に明らかな違いは見当たりませんでした。 syslogとは何か、syslogとは何か。 はい、ドキュメントの質が悪い人、優れた人がいます。 彼はその方法を知っており、彼は別の方法で。

rsyslogについても少し説明します。 まず、モジュールがたくさんあるのでクールです。 人間が読めるRainerScript(最新の構成言語)があります。 素晴らしいボーナスは、通常の手段を使用してtd-agentの動作をエミュレートできることであり、アプリケーションでは何も変わりません。 つまり、td-agentをrsyslogに変更しており、他のすべてに触れているわけではありません。 そしてすぐに私達は働く配達を得ます。 次に、mmnormalizeはrsyslogで素晴らしいことです。 ログを解析できますが、Grokと正規表現は使用できません。 彼女は抽象的な構文ツリーを作成します。 コンパイラがソースコードを解析するときに、ログをおよそ解析します。 これにより、非常に迅速に作業でき、CPUをほとんど消費せず、一般的に非常にクールなことです。 他にもたくさんのボーナスがあります。 私はそれらについてやめません。

Rsyslogにはまだ多くの欠陥があります。 それらはボーナスとほぼ同じです。 主な問題-あなたはそれを調理できるようにする必要があり、あなたはバージョンを選択する必要があります。
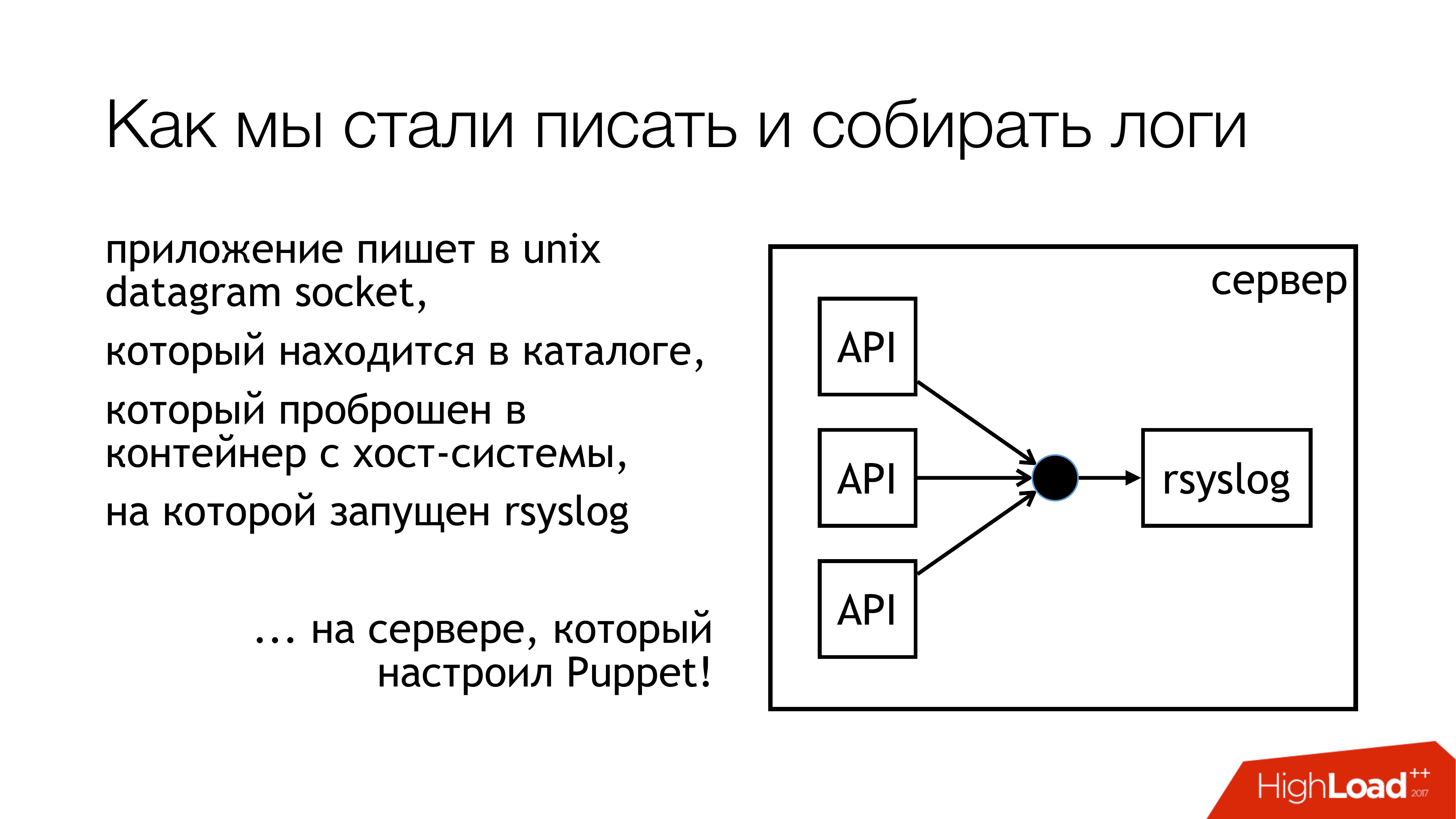
UNIXソケットにログを書き込むことにしました。 / dev / logではなく、システムログからポリッジがあるため、このパイプラインにはジャーナルがあります。 それでは、カスタムソケットに書き込みましょう。 別のルールセットに添付します。 干渉しません。 すべてが透明で明確になります。 だから実際にやった。 これらのソケットのあるディレクトリは標準化されており、すべてのコンテナに転送されます。 コンテナは必要なソケットを確認し、開いて書き込みます。
なぜファイルではないのですか? 誰もがファイルをdockerに転送しようとしたBadushechkaに関する記事を読み、 rsyslogを再起動するとファイル記述子が変更され、dockerがこのファイルを失うことが判明したためです。 彼は他の何かを開いたままにしますが、彼らが書いたのと同じソケットは開きません。 この問題を回避すると同時に、ブロッキングの問題も回避することにしました。

Rsyslogはスライドに示されたアクションを実行し、ログをリレーまたはKafkaに送信します。 カフカは昔のやり方にマッチします。 リレー-ログを配信するために純粋なrsyslogを使用しようとしました。 Message Queueなしで、標準のrsyslogツール。 基本的には機能します。

ただし、後でこの部分に詰め込む方法には微妙な違いがあります(Logstash / Graylog / ES)。 この部分(rsyslog-rsyslog)は、データセンター間で使用されます。 これは圧縮されたtcpリンクです。これにより、帯域幅を節約し、それに応じて、チャネルがいっぱいの状態で別のデータセンターから何らかのログを受信する可能性を高めることができます。 なぜなら、インドネシアにはすべてが悪いからです。 これが、この絶え間ない問題のある場所です。

アプリケーションから記録したログがどの程度の確率で実際に監視されるかを考えました。 メトリックを取得することにしました。 Rsyslogには独自の統計収集モジュールがあり、これには何らかの種類のカウンターがあります。 たとえば、キューのサイズ、またはそのようなアクションで受信したメッセージの数を表示できます。 それらから何かをすでに取ることができます。 さらに、構成可能なカスタムカウンターがあり、たとえば、あるAPIが書き込んだメッセージの数を表示します。 次に、Pythonでrsyslog_exporterを作成し、すべてをPrometheusに送信してプロットしました。 Graylogメトリックは本当に必要でしたが、これまでのところ、構成する時間がありませんでした。

問題は何ですか? ライブAPIが1秒あたり5万件のメッセージを書き込むことを発見した(突然!)という事実に問題が発生しました。 これはステージングのないライブAPIのみです。 また、Graylogでは、1秒あたり12,000件のメッセージしか表示されません。 そして、合理的な疑問が生じましたが、残り物はどこにありますか? これから、Graylogは対応できないと結論付けました。 彼らは見た、そして実際、Elasticsearchを備えたGraylogはこのストリームをマスターしなかった。
さらに、その過程で行った他の発見。
ソケットへの書き込みはブロックされます。 これはどのように起こりましたか? 配信にrsyslogを使用すると、ある時点でデータセンター間のチャネルが壊れました。 配達はある場所で起き、配達は別の場所で起きました。 これらはすべて、rsyslogソケットに書き込むAPIを備えたマシンに到達しました。 キューがありました。 次に、Unixソケットに書き込むためのキューがいっぱいになりました。デフォルトは128パケットです。 そして、アプリケーション内の次の書き込み()はブロックされます。 Goのアプリケーションで使用するライブラリを見ると、非書き込みモードでソケットへの書き込みが発生することが書かれています。 何もブロックしていないと確信していました。 バドゥシェチカについて書いた記事を読んだからです。 しかし、瞬間があります。 この呼び出しの周りには、メッセージをソケットにプッシュしようと絶えず試みられる無限のサイクルがまだありました。 彼には気づかなかった。 ライブラリを書き直す必要がありました。 それ以来、数回変更されましたが、今ではすべてのサブシステムのロックがなくなりました。 したがって、rsyslogを停止でき、何も落ちません。
キューのサイズを監視する必要があります。これは、このレーキを踏まないようにするのに役立ちます。 まず、メッセージが失われ始めるのを監視できます。 第二に、原則として配信の問題があることを監視できます。
そして別の不快な瞬間-マイクロサービスアーキテクチャで10倍の増幅-それは非常に簡単です。 着信リクエストはあまりありませんが、これらのメッセージが実行されるグラフのため、アクセスログのため、ログの負荷は実際に約10倍に増加します。 残念ながら、正確な数値を計算する時間はありませんでしたが、マイクロサービスはそうです。 これに留意する必要があります。 現時点では、ログ収集サブシステムがラザダで最も負荷が高いことが判明しています。

elasticsearchの問題を解決するには? すべてのマシンにまたがってログを収集しないように、ログを1か所ですばやく取得する必要がある場合は、ファイルストレージを使用します。 これは機能することが保証されています。 任意のサーバーから作成されます。 そこにディスクを貼り付けてsyslogを配置するだけです。 その後、すべてのログを1か所に保存することが保証されます。 さらに、Elasticsearch、graylogなどをゆっくり調整することはすでに可能です。 しかし、すでにすべてのログがあり、さらに、十分なディスクアレイまでログを保存できます。

私の報告の時点で、回路はこのように見え始めました。 ファイルへの書き込みを実質的に停止しました。 今、ほとんどの場合、残り物をオフにします。 APIを実行しているローカルマシンでは、ファイルへの書き込みを停止します。 まず、非常にうまく機能するファイルストレージがあります。 第二に、これらのマシン上の場所は絶えず尽きており、絶えず監視する必要があります。
LogstashとGraylogのこの部分は、本当に急上昇しています。 したがって、それを取り除く必要があります。 1つ選択する必要があります。

LogstashとKibanaを投げることにしました。 セキュリティ部門があるからです。 接続とは何ですか? 接続は、X-PackおよびShieldなしのKibanaでは、ログへのアクセス権を区別できないことです。 したがって、彼らはグレイログを取りました。 彼はそれをすべて持っています。 私は彼が好きではありませんが、うまくいきます。 新しい鉄を購入し、そこに新しいGraylogを配置し、厳格な形式のすべてのログを別のGraylogに移動しました。 さまざまなタイプの同一のフィールドを組織的に解決して問題を解決しました。

新しいGraylogに正確に含まれるもの。 Dockerにすべてを記録しました。 サーバーの束を取り、3つのKafkaインスタンス、7つのGraylogサーバーバージョン2.3を展開しました(Elasticsearchバージョン5が必要だったため)。 HDDからの襲撃に関するこれはすべて発生しました。 1秒あたり最大10万メッセージのインデックス作成率を見ました。 週に140テラバイトのデータがあることがわかりました。

そして再び熊手! 2つの販売が来ています。 600万通のメッセージを移動しました。 グレイログには噛む時間がありません。 どういうわけか、私たちは再び生き残る必要があります。

このように生き延びました。 さらにいくつかのサーバーとSSDを追加しました。 現時点では、私たちはこのように生きています。 現在、すでに1秒あたり160kのメッセージを噛んでいます。 私たちはまだ限界に達していないので、どれだけ実際にこれから抜け出せるかはまだ明確ではありません。

これらは将来の計画です。 これらのうち、最も重要なのはおそらく高可用性です。 まだありません。 複数の車が同じように構成されていますが、これまでのところ、すべてが1台の車を通過しています。 それらの間にフェイルオーバーをセットアップするには時間がかかります。
Graylogでメトリックを収集します。
帯域幅やその他すべてを犠牲にしない、クレイジーなAPIが1つあるように、レート制限を設定します。
そして最後に、開発者と何らかのSLAに署名して、それだけのサービスを提供できるようにします。 もっと書くなら、ごめんなさい。
そして、ドキュメントを書きます。

簡単に言えば、私たちが経験したすべての結果です。 まず、標準。 第二に、syslogはケーキです。 第三に、rsyslogはスライドに書かれているとおりに機能します。 そして質問に行きましょう。
質問
質問 :なぜ彼らは服用しないことに決めたのですか...(filebeat?)
回答 :ファイルに書き込む必要があります。 本当にしたくありませんでした APIが1秒間に数千のメッセージを書き込む場合、1時間に1回ローテーションしても、これはまだオプションではありません。 パイプで書くことができます。 開発者が私に尋ねたもの:「私たちが書くプロセスが落ちたらどうなりますか?」 私は彼らに何を答えるべきか見つけられなかったので、「まあ、それはやめましょう」と言いました。
質問 :単純にHDFSでログを書きませんか?
回答 :これは次のステップです。 私たちは最初からそれについて考えましたが、現在これを行うためのリソースがないため、長期的な解決策にかかっています。
質問 :列形式の方が適しています。
回答 :私はすべてを理解しています。 私たちは両手のためです。
質問 :あなたはrsyslogに書いています。 そこでTCPとUDPを使用できます。 しかし、UDPの場合、どのように配信を保証しますか?
回答 :2つのポイントがあります。 最初に、ログの配信を保証しないことをすぐに全員に伝えます。 開発者が来て、「財務データを書き始めましょう。何かが起こった場合に備えて、どこかに置いてください」と言うので、私たちは「素晴らしい! ソケットへの書き込みをブロックし始め、トランザクションでそれを行います。そうすることで、ソケットに確実に挿入し、その側から受信したことを確認できます。 それが必要でない場合、私たちの質問は何ですか? ソケットへの書き込みを保証したくない場合、なぜ配信を保証するのですか? 最善を尽くします。 私たちは、可能な限り最大限に配信するように心がけていますが、100%の保証はいたしません。 したがって、そこに財務データを書き込まないでください。 このためのトランザクションを持つデータベースがあります。
質問 :APIがログにメッセージを生成し、制御をマイクロサービスに転送するときに、異なるマイクロサービスからのメッセージの順序が間違っているという問題が発生しましたか? これにより混乱が生じます。
回答 :順番が違うのは普通です。 このために準備する必要があります。 ネットワーク配信は順序を保証するものではないため、またはこれに特にリソースを費やす必要があるためです。 ファイルストレージを使用する場合、各APIは独自のファイルにログを保存します。 むしろ、rsyslogはそれらをディレクトリに分解します。 各APIには独自のログがあり、そこに行って見ることができ、このログのタイムスタンプを使用してそれらを比較できます。 Graylogを調べに行くと、そこでタイムスタンプでソートされます。 そこはすべてうまくいきます。
質問 :タイムスタンプはミリ秒単位で異なる場合があります。
回答 :タイムスタンプはAPI自体を生成します。 実際、これがすべてです。 NTPがあります。 APIは、メッセージ自体に既にタイムスタンプを生成します。 rsyslogは追加されません。
質問 :データセンター間の相互作用はあまり明確ではありません。 データセンターのフレームワークでは、ログがどのように収集、処理されたかが明確です。 データセンター間の相互作用はどうですか? または、各データセンターは独自の生活を送っていますか?
回答 :ほぼ。 - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. これは歴史的に事実です。 , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . もう1つポイントがあります。 Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
c : Kafka , ? ?
: Kafka, , Data Sience. , , , . . Data Sience. , . Graylog, , Kafka. . API. live, staging . Graylog .
c : ? log- syslog .
: , . docker 1.0 0.9. Docker . -, … , , . API , API , stdout stderr. . , syslog- . Graylog . log- . GELF Graylog. , , . , - , , .
質問:rsyslogでデータセンター間の配信を行います。なぜカフカにいませんか?
回答:私たちは両方を行っているので、実際にはそうです。2つの理由があります。チャネルが完全に停止している場合、圧縮された形式でもすべてのログがクロールされません。また、kafkaを使用すると、プロセスでそれらを単純に失います。このようにして、これらのログを貼り付ける必要がなくなります。この場合、Kafkaを直接使用します。良いチャネルがあり、それを解放したい場合は、rsyslogを使用します。しかし実際には、クロールされなかったものを彼自身が落とすように設定できます。現時点では、rsyslog配信を直接使用している場所、Kafkaを使用しています。