Rでjsonを効果的に使用するには?
これは、 以前の出版物の続きです。
問題文
原則として、json形式のデータの主なソースはREST APIです。 プラットフォームの独立性とデータに対する人間の認識の利便性に加えて、jsonを使用すると、非構造化データシステムを複雑なツリー構造で交換できます。
APIを構築するタスクでは、これは非常に便利です。 通信プロトコルのバージョン管理を簡単に行うことができ、情報交換の柔軟性を提供するのは簡単です。 同時に、データ構造の複雑さ(ネストレベルは5、6、10、またはそれ以上)を恐れることはありません。すべてを考慮に入れた単一レコードの柔軟なパーサーを記述することはそれほど難しくないからです。
データ処理タスクには、外部ソースからのデータの取得も含まれます。 JSON形式。 Rには、jsonをRオブジェクトに変換するように設計されたjsonlite
パッケージセット(特にjsonlite
)があります(データ構造が許可する場合は、 list
またはdata.frame
)。
ただし、実際には、 jsonlite
などの使用が非常に非効率になると、2つのクラスの問題がしばしば発生します。 タスクは次のようになります。
- さまざまな情報システムの運用中に取得した大量のデータ(測定単位-ギガバイト)の処理。
- パラメータ化されたREST APIリクエストのパケット中に受信した多数の可変構造化された応答を、統一された長方形の表現(
data.frame
)にdata.frame
ます。
イラストの同様の構造の例:
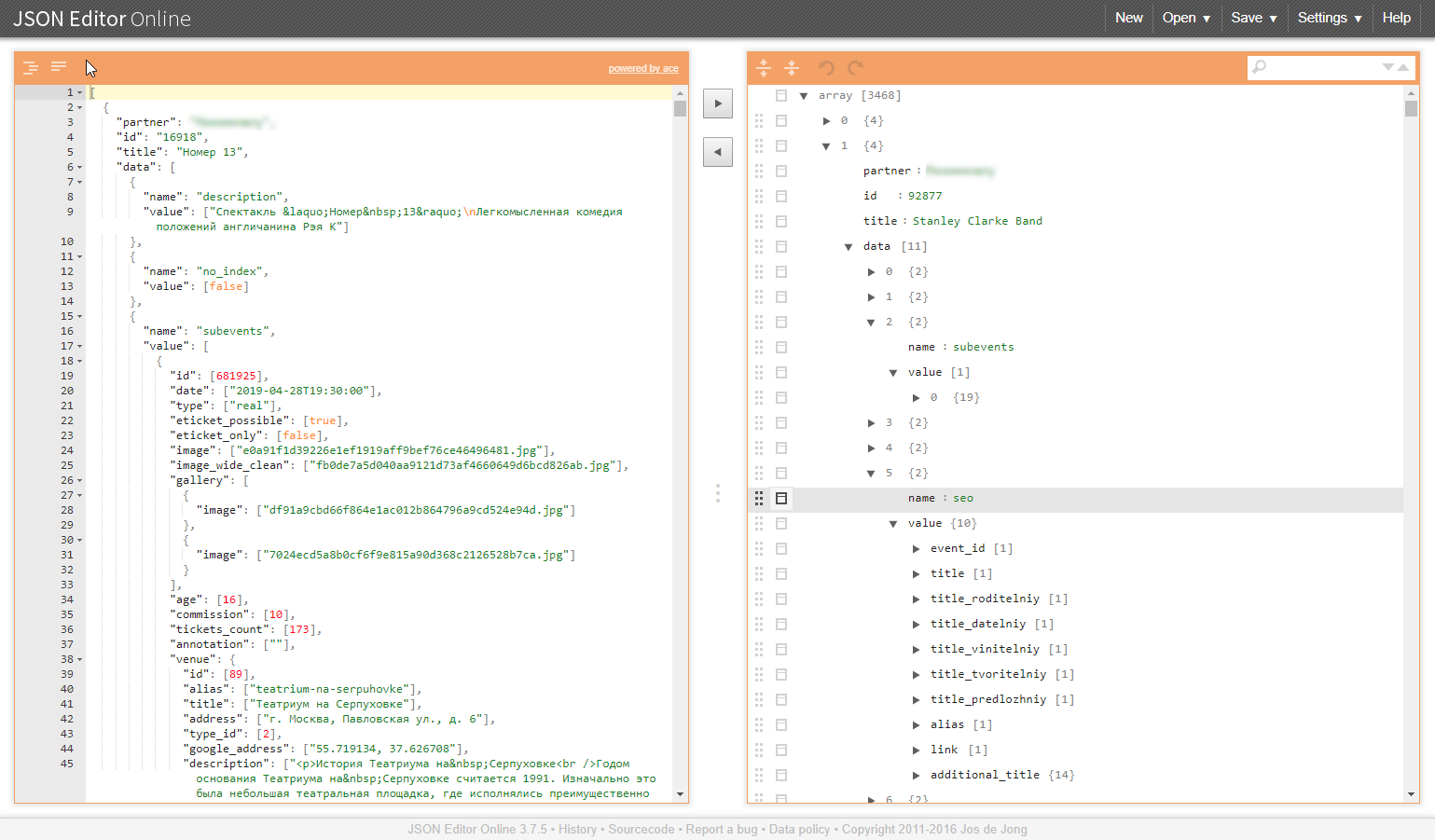
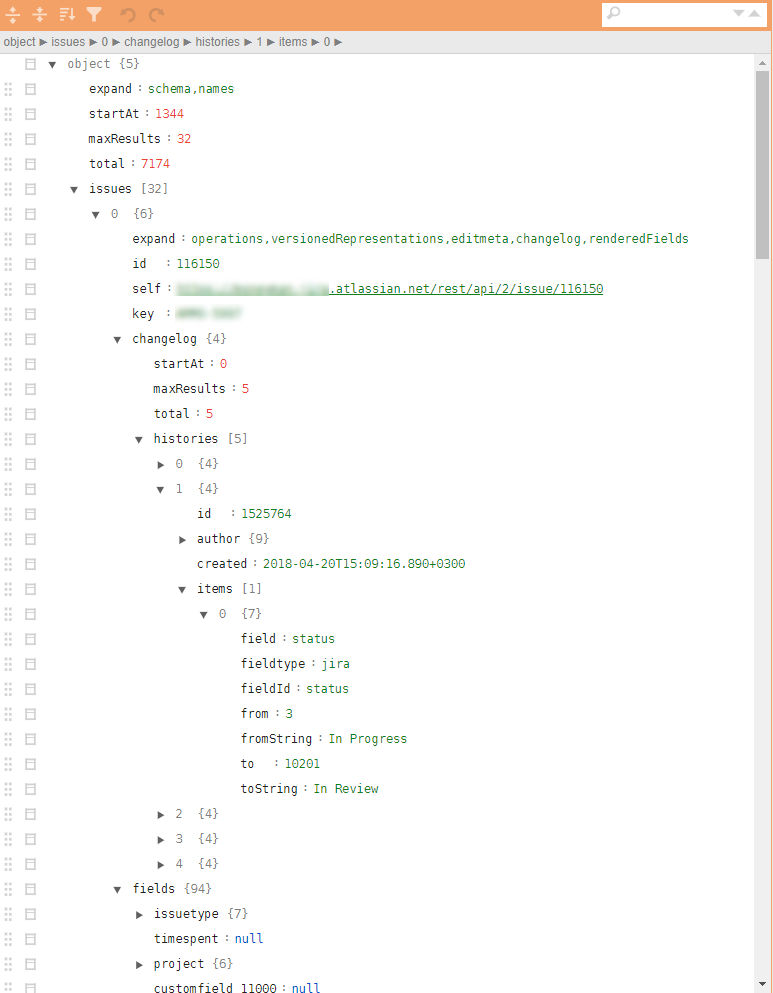
これらのタスククラスに問題があるのはなぜですか?
大量のデータ
原則として、json形式の情報システムからのアンロードは分割できないデータブロックです。 正しく解析するには、すべてを読み、ボリューム全体を調べる必要があります。
誘発された問題:
- 対応する量のRAMとコンピューティングリソースが必要です。
- 解析速度は使用するライブラリの品質に大きく依存します。十分なリソースがある場合でも、変換時間は数十分または数百分にもなります。
- 解析に失敗した場合、出力で結果が得られず、すべてが常にスムーズに進むことを望んで、理由はなく、逆になります。
- 解析されたデータを
data.frame
に変換できれば、非常に成功しdata.frame
。
ツリー構造のマージ
たとえば、ビジネスプロセスがAPIを介したリクエストのパケットで動作するために必要なディレクトリを収集する必要がある場合、同様のタスクが発生します。 さらに、ディレクトリは、分析パイプラインへの組み込みとデータベースへのアップロードの可能性を統一し、準備していることを意味します。 また、これにより、このような要約データをdata.frame
変換するdata.frame
ます。
誘発された問題:
- ツリー構造自体は平坦になりません。 jsonパーサーは入力データをネストされたリストのセットに変換します。このリストは手動で長く苦労してデプロイする必要があります。
- 出力データの属性の自由(表示されない場合があります)は、リストに関連する
NULL
オブジェクトの出現につながりますが、data.frame
「適合」できません。data.frame
(rbindlist
、bind_rows
、 'map_dfr'またはrbind
は関係ありません)。
JQ
特に困難な状況では、上記の理由でjsonlite
パッケージの「すべてをRオブジェクトに変換」する非常に便利なアプローチを使用すると、深刻な誤動作がjsonlite
ます。 まあ、処理の最後に到達した場合。 さらに悪いことに、真ん中に腕を広げてあきらめなければなりません。
このアプローチの代替方法は、jsonデータを直接操作するjsonプリプロセッサーを使用することです。 jq
ライブラリとjqr
ラッパー。 実践では、使用量が少ないだけでなく、聞いたこともまったくないことを示しています。
jq
ライブラリーの利点。
- このライブラリは、R、Python、およびコマンドラインで使用できます。
- すべての変換はJSONレベルで実行され、R / Pythonオブジェクトの表現への変換は行われません。
- 処理はアトミック操作に分割でき、チェーンの原則(パイプ)を使用できます。
- オブジェクトベクトルを処理するためのサイクルはパーサー内に隠され、反復構文は最大限に簡素化されます。
-
data.frame
を使用してバッチ方式でdata.frame
変換されるjson形式を形成するために、json構造の統一、展開、および必要な要素の選択に関するすべての手順を実行するjsonlite
。 - JSONデータの処理を担当するRコードの複数の削減。
- データ構造の量と複雑さに応じて、膨大な処理速度が得られるため、ゲインは1〜3桁になります。
- RAM要件がはるかに少なくなります。
処理コードは画面に合わせて圧縮され、次のようになります。
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
jqは非常にエレガントで高速です! 関連する人に:ダウンロード、設定、理解。 処理を高速化し、自分自身と同僚の生活を簡素化します。
前の投稿- 「エンタープライズでRの適用を開始する方法。 実用的なアプローチの例 。 」