Zendeskでは、Pythonを使用して機械学習製品を作成しています。 機械学習アプリケーションでは、私たちが遭遇した最も一般的な問題の1つは、メモリリークとスパイクです。 Pythonコードは通常、 Hadoop 、 Spark、 AWS Batchなどの分散処理フレームワークを使用してコンテナで実行されます。 各コンテナには、一定量のメモリが割り当てられます。 コードの実行が指定されたメモリ制限を超えるとすぐに、コンテナはメモリ不足のために発生するエラーのために動作を停止します。

さらに多くのメモリを割り当てることにより、問題をすばやく修正できます。 ただし、これはリソースの浪費につながり、予測できないメモリのバーストによりアプリケーションの安定性に影響を与える可能性があります。 メモリリークの原因は次のとおりです。
- 削除されない大きなオブジェクトの長期保存。
- コード内のループバックリンク 。
- Cのベースライブラリ/拡張機能により、メモリリークが発生します。
メモリ使用量をアプリケーションでプロファイリングして、使用するコードスペースとパッケージの効率をよりよく理解することをお勧めします。
この記事では、次の側面について説明します。
- 経時的なアプリケーションメモリ使用量のプロファイリング。
- プログラムの特定の部分のメモリ使用量を確認する方法。
- メモリの問題が原因のエラーをデバッグするためのヒント。
経時的なメモリプロファイリング
memory-profilerパッケージを使用して、Pythonプログラムの実行中の可変メモリ使用量を確認できます。
# install the required packages pip install memory_profiler pip install matplotlib # run the profiler to record the memory usage # sample 0.1s by defaut mprof run --include-children python fantastic_model_building_code.py # plot the recorded memory usage mprof plot --output memory-profile.png
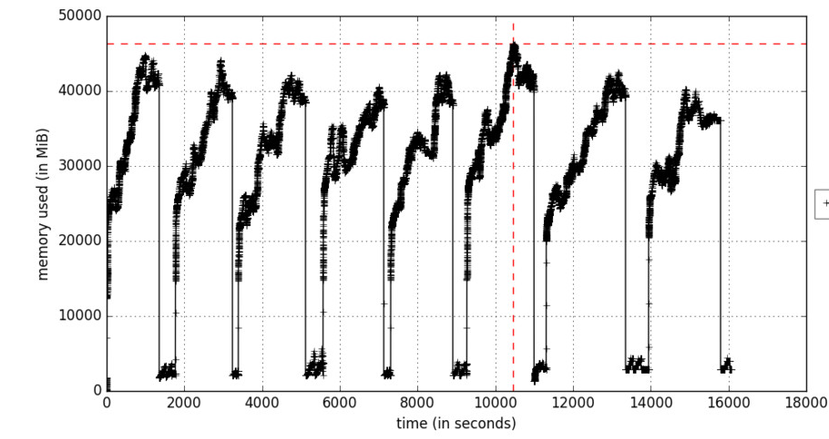
図A.時間の関数としてのメモリプロファイリング
include-childrenオプションは、親プロセスによって生成されたすべての子プロセスによるメモリ使用を有効にします。 図Aは、トレーニングデータパケットが処理される瞬間にメモリをサイクルで増加させる反復学習プロセスを反映しています。 オブジェクトはガベージコレクション中に削除されます。
メモリ使用量が絶えず増加している場合、これはメモリリークの潜在的な脅威と見なされます。 これを反映したサンプルコードを次に示します。
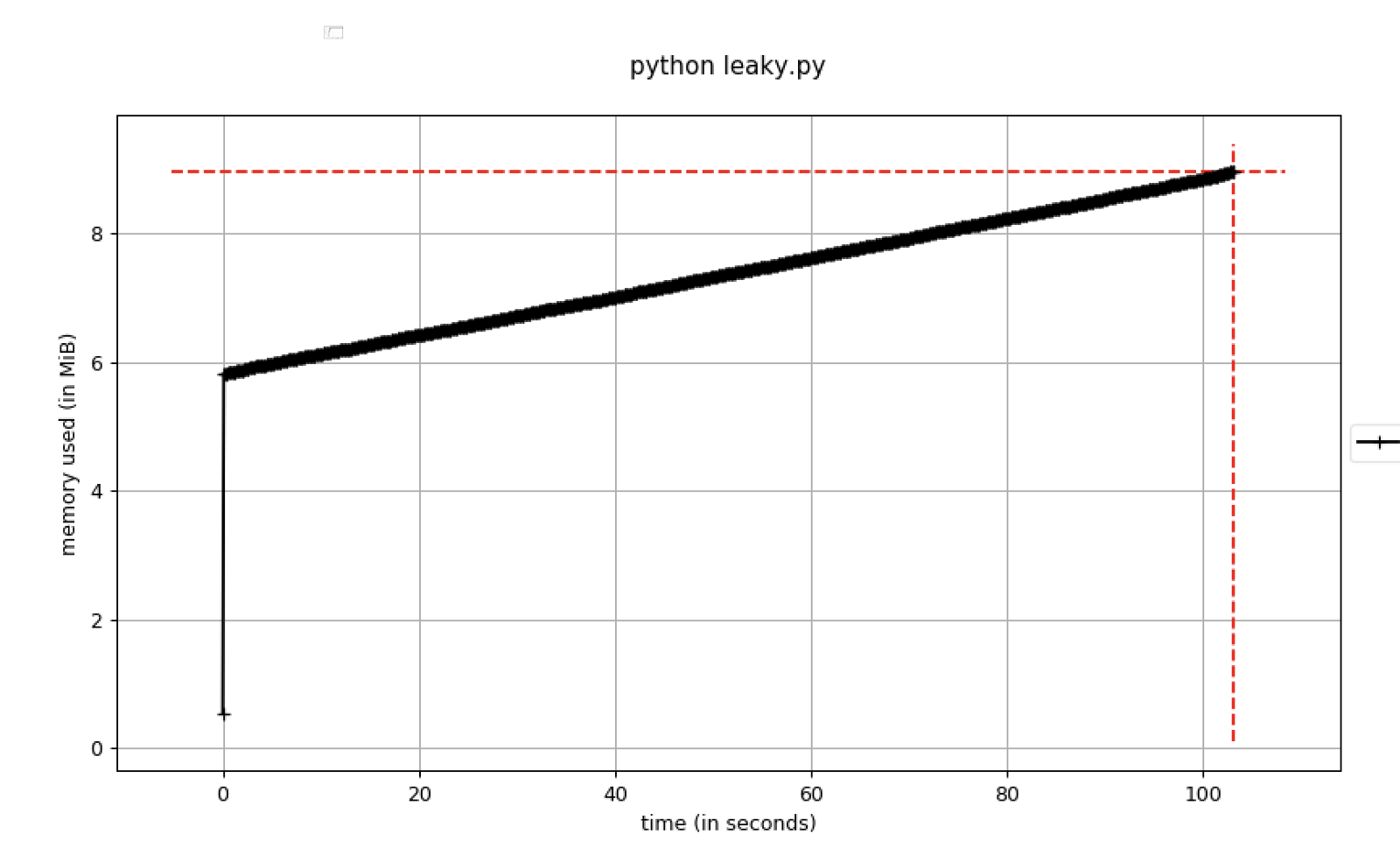
図B.時間とともに増加するメモリ使用量
メモリ使用量が特定のしきい値を超えたらすぐに、デバッガーにブレークポイントを設定する必要があります。 これを行うには、トラブルシューティング中に便利なpdb-mmemパラメーターを使用できます。
特定の時点でのメモリダンプ
プログラム内の大規模なオブジェクトの予想される数を推定し、それらを複製したり、さまざまな形式に変換したりする必要があるかどうかを推定すると便利です。
メモリ内のオブジェクトをさらに分析するために、 muppyを使用してプログラムの特定の行にダンプヒープを作成できます。
# install muppy pip install pympler # Add to leaky code within python_script_being_profiled.py from pympler import muppy, summary all_objects = muppy.get_objects() sum1 = summary.summarize(all_objects) # Prints out a summary of the large objects summary.print_(sum1) # Get references to certain types of objects such as dataframe dataframes = [ao for ao in all_objects if isinstance(ao, pd.DataFrame)] for d in dataframes: print d.columns.values print len(d)
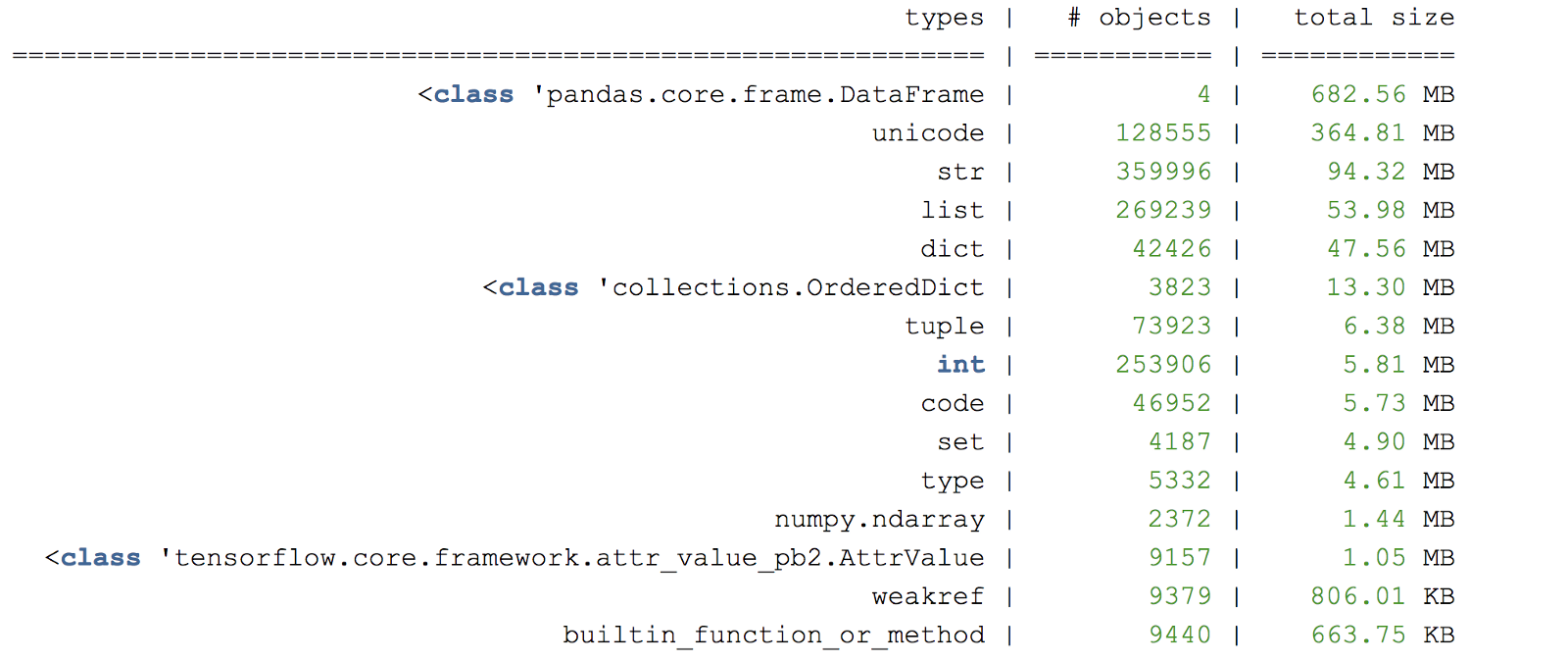
図C.ダンプヒープダンプのサンプル
もう1つの有用なメモリプロファイリングライブラリはobjgraphです 。これにより、オブジェクトの起源を確認するグラフを生成できます。
便利なポインター
有用なアプローチは、メモリリークを引き起こす適切なコードを実行する小さな「テストケース」を作成することです。 本格的な入力の処理に時間がかかる場合は、ランダムに選択したデータのサブセットの使用を検討してください。
別のプロセスでメモリ負荷が高いタスクを実行する
Pythonは、オペレーティングシステムのメモリをすぐに解放する必要はありません。 メモリが解放されたことを確認するには、コードを実行した後に別のプロセスを開始する必要があります。 Pythonのガベージコレクターの詳細については、 こちらをご覧ください 。
デバッガーはオブジェクトへの参照を追加できます。
pdbなどのブレークポイントデバッガーを使用する場合、デバッガーによって手動で参照されるすべての作成済みオブジェクトはメモリに残ります。 これにより、オブジェクトがタイムリーに削除されないため、メモリリークの誤った感覚が生じる可能性があります。
メモリリークを引き起こす可能性のあるパッケージに注意してください。
Pythonの一部のライブラリは潜在的にリークを引き起こす可能性があります。たとえば、
pandas
はいくつかの既知のメモリリークの問題があります。
リークを探しましょう!
便利なリンク:
docs.python.org/3/c-api/memory.html
docs.python.org/3/library/debug.html
この記事がお役に立てばコメントをお書きください。 そして、私たちのコースについてもっと知りたい方は、4月22日に開催されるオープンデーにご招待します。