通常、Nginxは商用製品またはPrometheus + Grafanaなどのオープンソースの代替製品を使用して、Nginxのパフォーマンスを監視および分析します。 これは、監視またはリアルタイム分析に適したオプションですが、履歴分析にはあまり便利ではありません。 一般的なリソースでは、nginxログからのデータ量が急速に増加しているため、大量のデータを分析するために、より特殊なものを使用するのが理にかなっています。
この記事では、例としてNginxを使用してAthenaを使用してログを分析し、オープンソースのcube.jsフレームワークを使用してこのデータから分析ダッシュボードをコンパイルする方法を説明します。 完全なソリューションアーキテクチャは次のとおりです。

TL:DR;
完成したダッシュボードへのリンク 。
Fluentdを使用して情報を収集し、 AWS Kinesis Data FirehoseとAWS Glueを処理に使用し、 AWS S3をストレージに使用します。 このバンドルを使用すると、nginxログだけでなく、他のイベントや他のサービスのログも保存できます。 スタックの一部を類似のパーツに置き換えることができます。たとえば、ngidxから直接kinesisにログを書き込んで、fluentdをバイパスしたり、logstashを使用したりできます。
Nginxログの収集
デフォルトでは、Nginxログは次のようになります。
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
それらは解析できますが、JSONでログを表示するようにNginx構成を修正する方がはるかに簡単です:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
ストレージ用のS3
ログを保存するには、S3を使用します。 これにより、AthenaはS3のデータを直接操作できるため、ログを1か所で保存および分析できます。 記事の後半で、ログを正しく折りたたんで処理する方法を説明しますが、最初にS3にクリーンバケットが必要です。このバケットには他に何も保存されません。 アテナはすべての地域で利用できるわけではないため、バケットを作成する地域を事前に検討する価値があります。
Athenaコンソールで図を作成する
ログ用にAthenaにテーブルを作成します。 Kinesis Firehoseを使用する場合、書き込みと読み取りの両方に必要です。 Athenaコンソールを開き、テーブルを作成します。
CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Kinesis Firehoseストリームを作成する
Kinesis Firehoseは、選択した形式でNginxから受信したデータをS3に書き込み、YYYY / MM / DD / HH形式のディレクトリに分割します。 これは、データを読み取るときに役立ちます。 もちろん、fluentdからS3に直接書き込むこともできますが、この場合はJSONを記述する必要がありますが、これはファイルサイズが大きいため非効率的です。 また、PrestoDBまたはAthenaを使用する場合、JSONは最も遅いデータ形式です。 Kinesis Firehoseコンソールを開き、[配信ストリームの作成]をクリックして、[配信]フィールドで[直接PUT]を選択します。
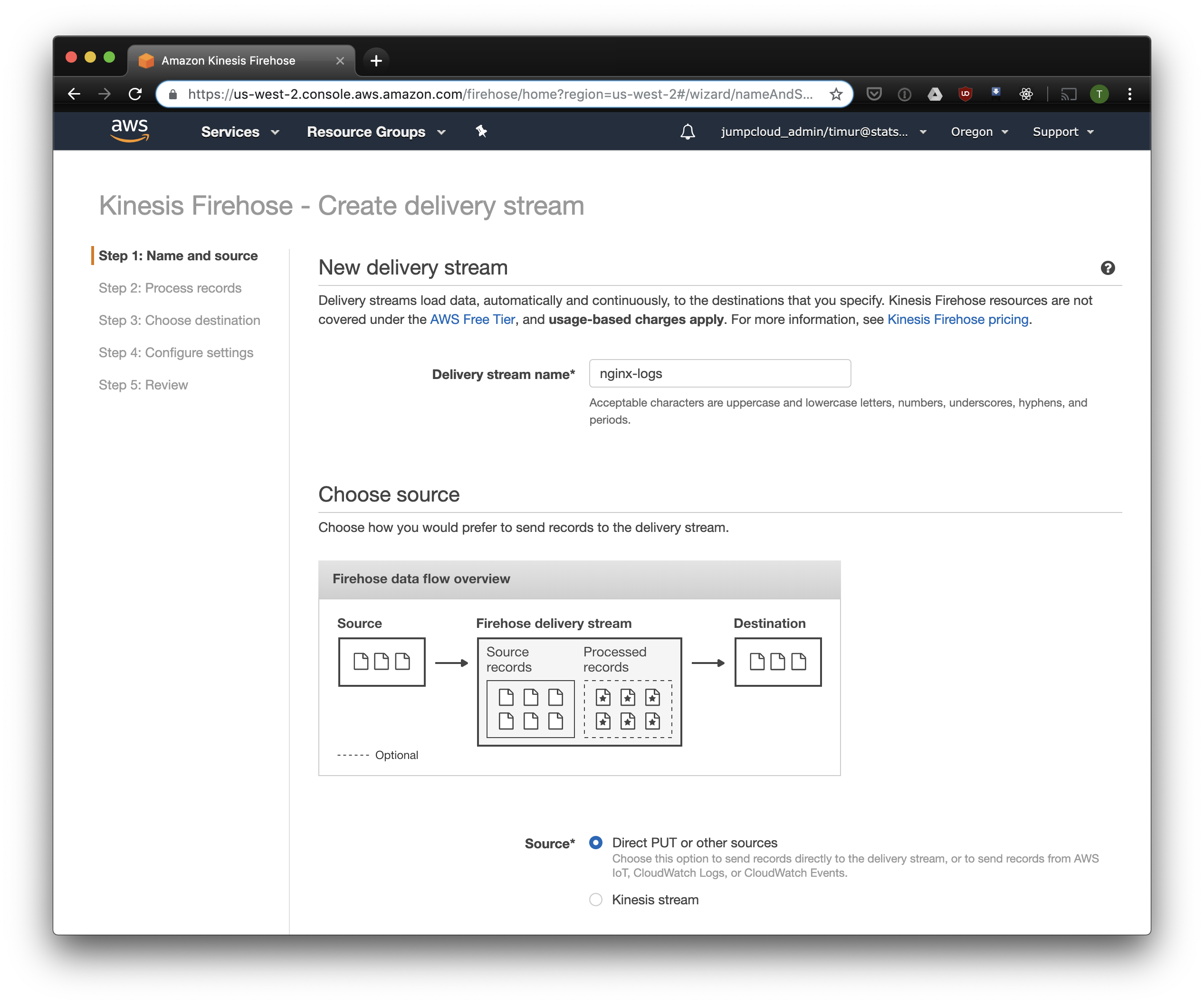
次のタブで、「記録形式の変換」-「有効」を選択し、記録の形式として「Apache ORC」を選択します。 いくつかのOwen O'Malleyによると、これはPrestoDBとAthenaに最適な形式です。 図として、上で作成したテーブルを示します。 kinesisで任意のS3ロケーションを指定できることに注意してください。表のスキームのみが使用されます。 ただし、別のS3ロケーションを指定すると、このテーブルからこれらのレコードの読み取りは失敗します。
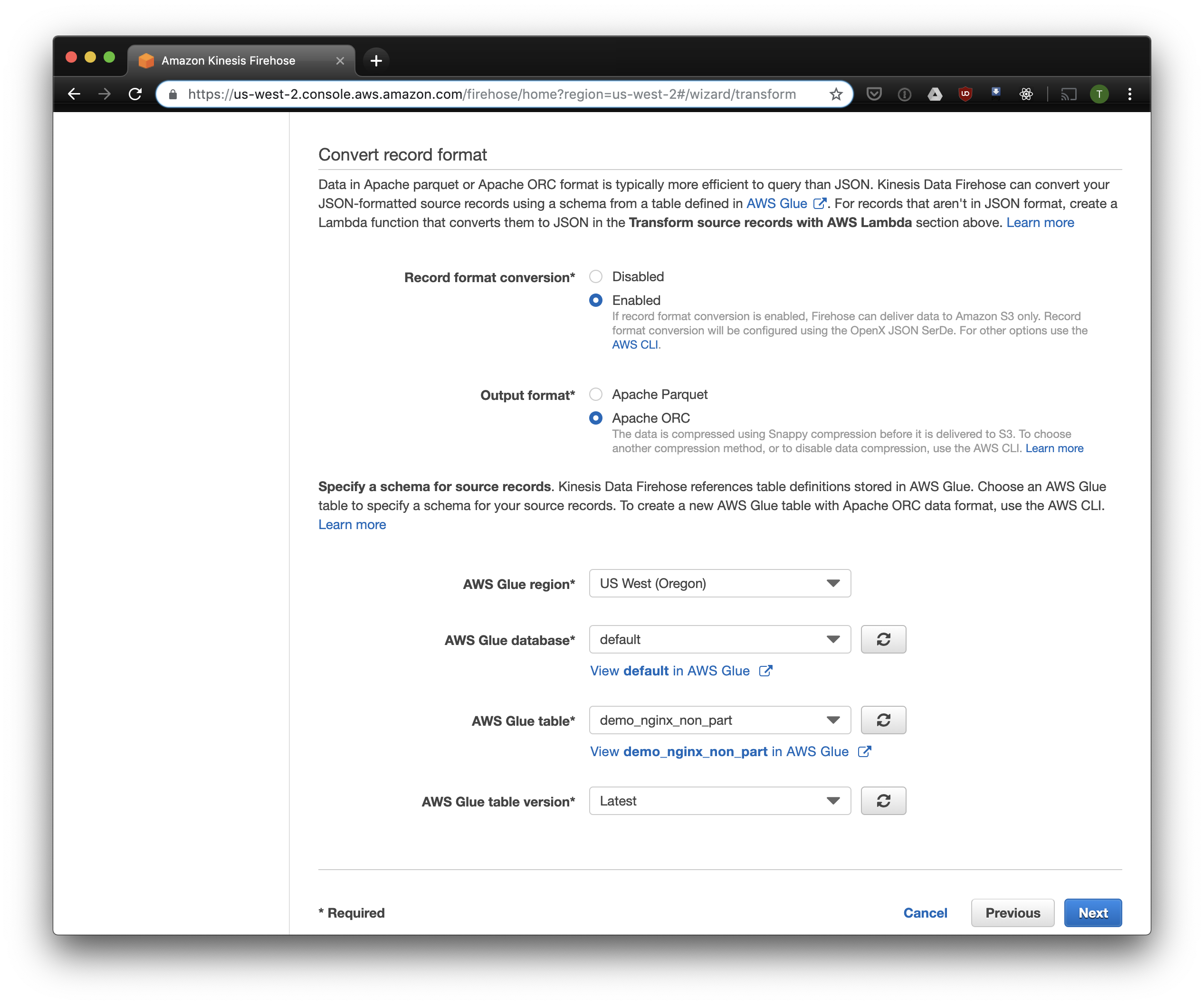
ストレージと以前に作成したバケットにS3を選択します。 Aws Glue Crawlerは、後で説明しますが、S3バケット内のプレフィックスの操作方法がわからないため、空のままにしておくことが重要です。

残りのオプションは負荷に応じて変更できます。通常はデフォルトを使用します。 S3圧縮は使用できませんが、ORCはデフォルトでネイティブ圧縮を使用することに注意してください。
流Flu
ログの保存と受信を設定したので、送信を設定する必要があります。 私はRubyが大好きなのでFluentdを使用しますが、Logstashを使用するか、kinesisにログを直接送信できます。 Fluentdサーバーはいくつかの方法で起動できます。Dockerについて説明します。これはシンプルで便利なためです。
まず、fluent.conf構成ファイルが必要です。 作成してソースを追加します。
フォワードタイプ
ポート24224
バインド0.0.0.0
これでFluentdサーバーを起動できます。 より高度な構成が必要な場合、 Docker Hubにはイメージの組み立て方法などの詳細なガイドがあります。
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
この構成では、 /fluentd/log
パスを使用して、送信前にログをキャッシュし/fluentd/log
。 これなしでも実行できますが、再起動すると、過度の労力によってキャッシュされたものがすべて失われる可能性があります。 どのポートも使用できます。デフォルトのFluentdポートは24224です。
Fluentdが実行されたので、そこでNginxログを送信できます。 通常、NginxはDockerコンテナーで実行します。この場合、DockerにはFluentd用のネイティブログドライバーがあります。
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Nginxを異なる方法で実行する場合、ログファイルを使用できます。Fluentdにはファイルテールプラグインがあります 。
上で構成したログ解析をFluent構成に追加します。
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
また、 kinesis firehoseプラグインを使用してログをKinesisに送信します 。
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
アテナ
すべてを正しく構成したら、しばらくすると(デフォルトでは、Kinesisは受信したデータを10分ごとに書き込みます)、S3にログファイルが表示されます。 Kinesis Firehoseの「監視」メニューでは、S3に書き込まれたデータの量とエラーを確認できます。 KinesisロールのS3バケットへの書き込みアクセスを忘れずに与えてください。 Kinesisが何かを解析できなかった場合、Kinesisは同じバケットにエラーを追加します。
これで、Athenaのデータを確認できます。 エラーが発生した新しいリクエストを見つけましょう。
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
各リクエストのすべてのレコードをスキャンします
これで、ログが処理され、ORCのS3にスタックされ、圧縮され、分析の準備が整います。 Kinesis Firehoseは、それらを1時間ごとにディレクトリに配置します。 ただし、テーブルはパーティション化されていませんが、Athenaはまれな例外を除き、各クエリの常時データをロードします。 これは2つの理由で大きな問題です。
- データ量は絶えず増加しており、クエリの速度が低下しています。
- Athenaは、スキャンされたデータの量に基づいて請求され、リクエストごとに最低10 MBが請求されます。
これを修正するために、AWS Glue Crawlerを使用します。これは、S3のデータをスキャンし、Glue Metastoreにパーティション情報を記録します。 これにより、パーティションをAthenaのリクエストのフィルターとして使用でき、リクエストで指定されたディレクトリのみをスキャンします。
Amazon Glue Crawlerをカスタマイズする
Amazon Glue Crawlerは、S3バケット内のすべてのデータをスキャンし、パーティションテーブルを作成します。 AWS GlueコンソールからGlue Crawlerを作成し、データを保存するバケットを追加します。 1つのクローラーを複数のバケットに使用できます。この場合、指定されたデータベースに、バケットの名前と一致する名前のテーブルが作成されます。 このデータを常に使用する予定がある場合は、ニーズに合わせてクローラーの起動スケジュールを調整してください。 1時間ごとに実行されるすべてのテーブルに対して1つのクローラーを使用します。
パーティションテーブル
クローラーが最初に起動された後、スキャンされた各バケットのデータベースが設定で指定されたデータベースに表示されます。 Athenaコンソールを開き、Nginxログテーブルを見つけます。 何かを読みましょう:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
このクエリは、2019年4月8日の午前6時から午前7時までに受信したすべてのレコードを選択します。 しかし、これはパーティション化されていないテーブルから読み取るよりもはるかに効率的ですか? タイムスタンプでフィルタリングして同じレコードを見つけて選択しましょう:
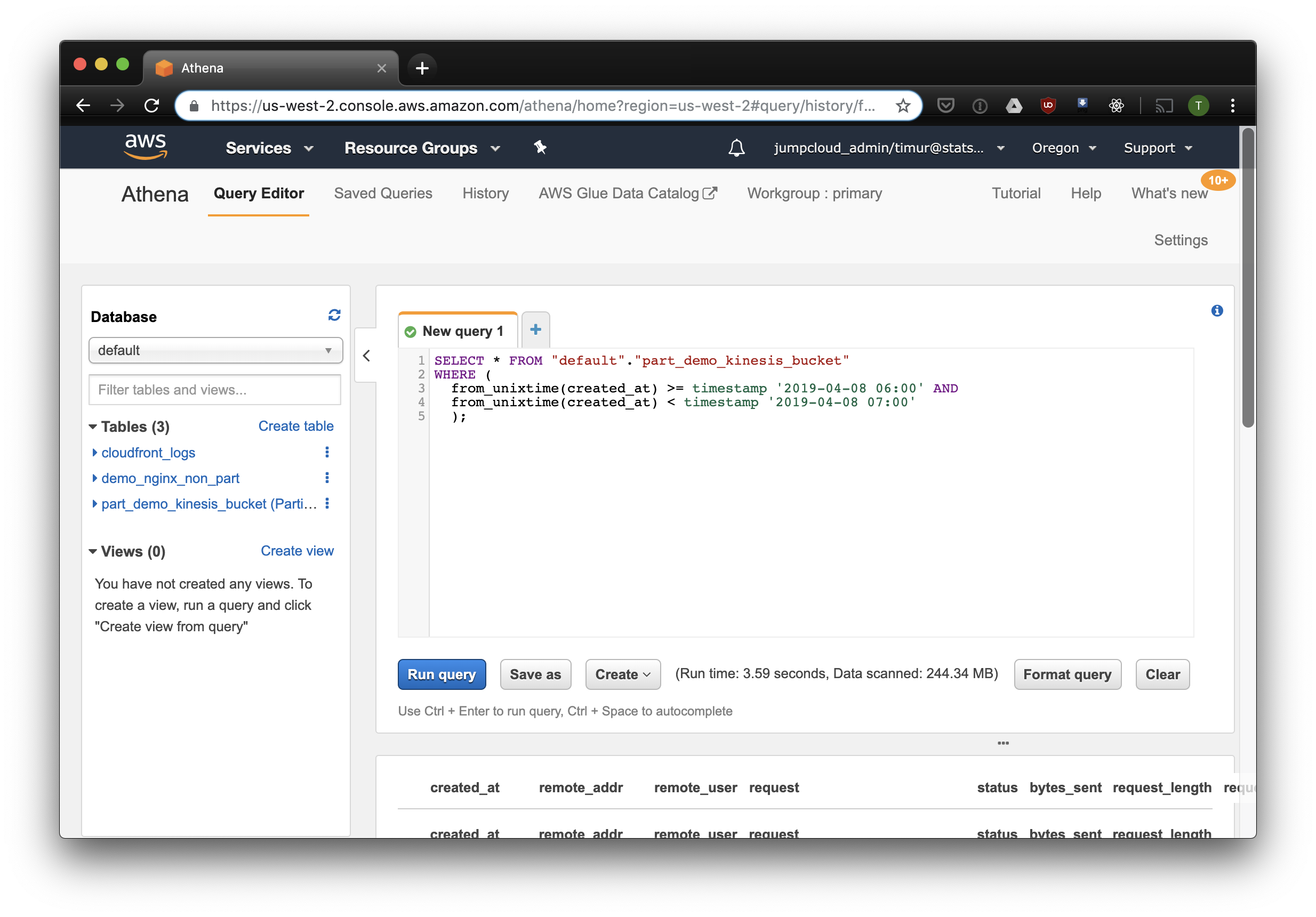
データセット上の3.59秒および244.34メガバイトのデータ。ログは1週間のみです。 パーティションごとにフィルターを試してみましょう。
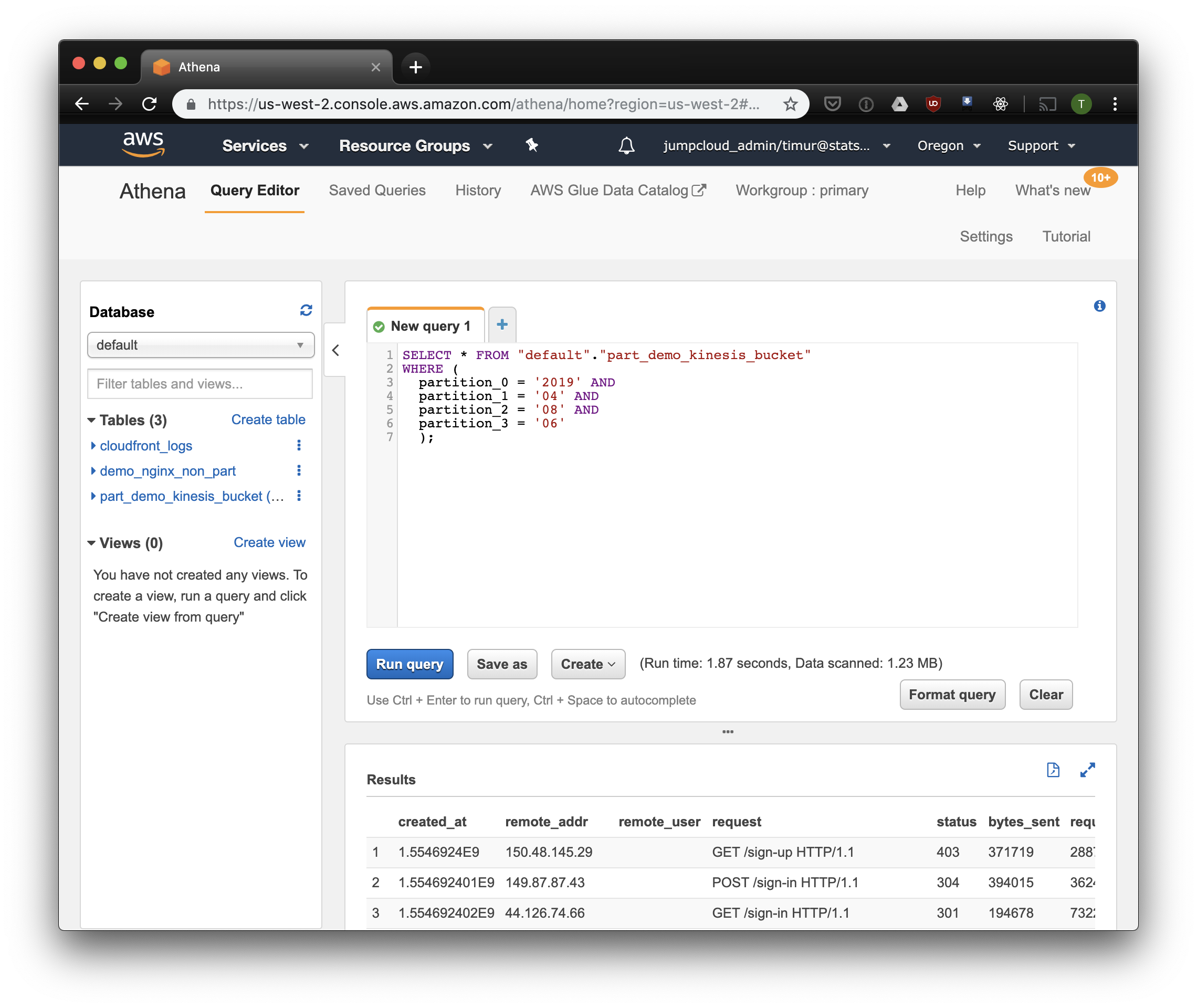
少し高速ですが、最も重要なのは、わずか1.23メガバイトのデータです! 価格設定でリクエストごとに最低10メガバイトがなければ、はるかに安くなります。 しかし、とにかくはるかに優れており、大規模なデータセットでは、違いははるかに印象的です。
Cube.jsを使用してダッシュボードを構築する
ダッシュボードを作成するには、Cube.js分析フレームワークを使用します。 かなりの数の機能がありますが、2つに興味があります。パーティションのフィルターを自動的に使用する機能とデータの事前集計です。 Javascriptで記述されたデータスキーマを使用して、SQLを生成し、データベースクエリを実行します。 必要なのは、データスキーマでパーティションフィルターを使用する方法を示すことだけです。
新しいアプリケーションCube.jsを作成しましょう。 既にAWS-stackを使用しているため、デプロイにLambdaを使用するのが論理的です。 HerokuまたはDockerでCube.jsバックエンドをホストする予定の場合、生成にエクスプレステンプレートを使用できます。 ドキュメントは他のホスティング方法について説明します 。
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
cube.jsでデータベースへのアクセスを構成するには、環境変数が使用されます。 ジェネレーターは、 Athenaのキーを指定できる.envファイルを作成します。
ここで、ログの保存方法を示すデータスキームが必要です。 ここで、ダッシュボードのメトリックの読み取り方法を指定できます。
schema
ディレクトリで、 Logs.js
ファイルを作成します。 nginxのデータモデルの例を次に示します。
const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
ここでは、 FILTER_PARAMS変数を使用して、パーティションフィルターを使用してSQLクエリを生成します。
また、ダッシュボードに表示するメトリックとパラメーターを指定し、事前集計を指定します。 Cube.jsは、事前に集計されたデータを使用して追加のテーブルを作成し、データが利用可能になると自動的に更新します。 これにより、クエリが高速化されるだけでなく、Athenaの使用コストが削減されます。
この情報をデータスキーマファイルに追加します。
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
このモデルでは、使用されるすべてのメトリックのデータを事前に集計し、毎月のパーティション分割を使用する必要があることを示しています。 事前集計をパーティション化すると、データの収集と更新を大幅に高速化できます。
これで、ダッシュボードをまとめることができます!
Cube.jsバックエンドは、一般的なフロントエンドフレームワーク用のREST APIとクライアントライブラリのセットを提供します 。 クライアントのReactバージョンを使用してダッシュボードを構築します。 Cube.jsはデータのみを提供するため、視覚化のためのライブラリが必要です-私はrechartsが好きですが、どれでも使用できます。
Cube.jsサーバーは、必要なメトリックを示すJSON形式のリクエストを受け入れます。 たとえば、Nginxが日ごとに与えるエラーの数を計算するには、次のリクエストを送信する必要があります。
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
NPMを介してCube.jsクライアントとReactコンポーネントライブラリをインストールします。
$ npm i --save @cubejs-client/core @cubejs-client/react
cubejs
およびQueryRendererコンポーネントをインポートしてデータをアンロードし、ダッシュボードを収集します。
import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
ダッシュボードのソースはCodeSandboxで入手できます。