分散システム構成で作業するための興味深いメカニズムをお話ししたいと思います。 構成は、安全な型を使用してコンパイル言語(Scala)で直接提示されます。 この投稿では、このような構成の例を分析し、開発プロセス全体でコンパイルされた構成を実装するさまざまな側面を検討します。
( 英語 )
はじめに
信頼性の高い分散システムを構築するということは、すべてのノードが他のノードと同期した正しい構成を使用することを意味します。 通常、DevOpsテクノロジー(terraform、ansible、またはそのようなもの)を使用して、構成ファイルを自動的に生成します(多くの場合、ノードごとに独自のファイル)。 また、相互作用するすべてのノード(同じバージョンを含む)で同一のプロトコルを使用するようにします。 そうしないと、分散システムに非互換性が埋め込まれます。 JVMの世界では、この要件の1つの結果として、プロトコルメッセージを含む同じバージョンのライブラリをどこでも使用する必要があります。
分散システムのテストはどうですか? もちろん、統合テストに進む前に、すべてのコンポーネントに対して単体テストが提供されていると想定しています。 (テスト結果をランタイムに外挿するには、テスト段階とランタイムで同一のライブラリセットも提供する必要があります。)
統合テストを使用する場合、多くの場合、すべてのノードで単一のクラスパスを使用する方がどこでも簡単です。 実行時に同じクラスパスが含まれていることを確認するだけです。 (異なるクラスパスで異なるノードを実行することは非常に可能ですが、これは構成全体の複雑化と、展開および統合テストの困難につながります。)この投稿の一部として、すべてのノードで同じクラスパスが使用されると想定しています。
構成はアプリケーションとともに進化します。 プログラムの進化のさまざまな段階を識別するために、バージョンを使用します。 構成の異なるバージョンを識別することも論理的に思われます。 また、構成自体をバージョン管理システムに配置する必要があります。 実稼働環境に構成が1つしかない場合は、バージョン番号を使用できます。 複数の実稼働インスタンスが使用されている場合、いくつかのインスタンスが必要です
構成ブランチと、バージョンに加えて追加のラベル(たとえば、ブランチの名前)。 したがって、正確な構成を一意に識別できます。 各構成識別子は、分散ノード、ポート、外部リソース、ライブラリバージョンの特定の組み合わせに一意に対応します。 この投稿のフレームワークでは、ブランチが1つしかないという事実から進み、ドット(1.2.3)で区切られた3つの数字を使用して通常の方法で構成を識別できます。
現代の環境では、構成ファイルが手動で作成されることはほとんどありません。 多くの場合、展開中に生成され、( 何も破損しないように)影響を受けなくなります。 論理的な疑問が生じますが、なぜテキスト形式を使用して構成を保存するのですか? 完全に実行可能な代替手段は、構成に通常のコードを使用し、コンパイル時のチェックから利益を得る機能です。
この投稿では、コンパイルされたアーティファクト内の構成を表すというアイデアを模索しています。
コンパイルされた構成
このセクションでは、静的にコンパイルされた構成の例を説明します。 エコーサービスとエコーサービスクライアントの2つの単純なサービスが実装されています。 これら2つのサービスに基づいて、2つのバージョンのシステムが組み立てられます。 一実施形態では、両方のサービスは同じノードに配置され、他の実施形態では異なるノードに配置される。
通常、分散システムには複数のノードが含まれます。 ノードは、 NodeId
タイプの値を使用して識別できます。
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
または
case class NodeId(hostName: String)
または
object Singleton type NodeId = Singleton.type
ノードはさまざまな役割を果たし、それらでサービスが起動され、それらの間でTCP / HTTP通信を確立できます。
TCP通信を説明するには、少なくともポート番号が必要です。 また、クライアントとサーバーの両方が同じプロトコルを使用することを保証するために、このポートでサポートされているプロトコルを反映したいと思います。 このクラスを使用した接続について説明します。
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
ここで、 Port
は有効な値の範囲を持つ整数の整数です。
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
HTTP(REST)プロトコルの場合、ポート番号に加えて、サービスへのパスも必要になる場合があります。
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
コンパイル段階でプロトコルを識別するために、クラス内で使用されない型パラメーターを使用します。 この解決策は、実行時にプロトコルインスタンスを使用しないという事実によるものですが、コンパイラにプロトコルの互換性をチェックしてもらいたいと考えています。 プロトコルの指示により、不適切なサービスを依存関係として転送することはできません。
一般的なプロトコルの1つは、Jsonシリアル化を使用したREST APIです。
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
ここで、 RequestMessage
は要求のタイプ、 ResponseMessage
はResponseMessage
のタイプです。
もちろん、必要な精度を提供する他のプロトコル記述を使用できます。
この投稿では、プロトコルの簡易バージョンを使用します。
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
ここで、要求はURLに追加された文字列であり、応答はHTTP応答の本文で返された文字列です。
サービス構成は、サービス名、ポート、および依存関係によって記述されます。 これらの要素は、Scalaでいくつかの方法で表現できます(たとえば、 HList
、代数データ型)。 この投稿の目的のために、Cakeパターンを使用し、 trait
を使用してモジュールを表します。 (ケーキパターンは、説明したアプローチの必須要素ではありません。可能な実装の1つにすぎません。)
サービス間の依存関係は、他のノードのEndPoint
ポートを返すメソッドとして表すことができます。
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
エコーサービスを作成するには、ポート番号と、このポートがエコープロトコルをサポートしているという指示だけで十分です。 特定のポートを示すことができませんでした、なぜなら 特性を使用すると、実装なしでメソッドを宣言できます(抽象メソッド)。 この場合、特定の構成を作成するときに、コンパイラーは抽象メソッドの実装とポート番号の提供を要求します。 メソッドを実装したため、特定の構成を作成するときに、別のポートを指定することはできません。 デフォルト値が使用されます。
クライアント構成では、エコーサービスへの依存関係を宣言します。
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
依存関係は、 echoService
エクスポートサービスと同じタイプです。 特に、エコークライアントでは、同じプロトコルが必要です。 したがって、2つのサービスを接続するときに、すべてが正しく機能することを確認できます。
サービスを開始および停止するには、機能が必要です。 (サービスを停止する機能はテストに不可欠です。)繰り返しますが、このような機能を実装するためのオプションがいくつかあります(たとえば、構成タイプに基づいてタイプクラスを使用できます)。 この投稿では、Cake Patternを使用します。 cats.Resource
クラスを使用してサービスを表します。なぜなら、 このクラスでは、問題が発生した場合にリソースを安全に解放する手段がすでに提供されています。 リソースを取得するには、構成と準備が整ったランタイムコンテキストを提供する必要があります。 サービスを開始する関数は次のようになります。
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
どこで
-
Config
-このサービスの構成タイプ -
AddressResolver
他のノードのアドレスを見つけることを可能にするランタイムオブジェクト(下記参照)
およびcats
ライブラリの他のタイプ:
-
F[_]
-効果のタイプ(最も単純な場合、F[A]
は単なる関数() => A
になります() => A
この投稿ではcats.IO
を使用しますcats.IO
) -
Reader[A,B]
-多かれ少なかれ関数A => B
と同義 -
cats.Resource
取得および解放できるリソース -
Timer
-タイマー(しばらく眠りにつくことができ、時間間隔を測定できます) -
ContextShift
-ExecutionContext
類似物 -
Applicative
個々のエフェクト(ほとんどモナド)を組み合わせることができるエフェクトタイプクラス。 より複雑なアプリケーションでは、Monad
/ConcurrentEffect
を使用したほうが良いようです。
この関数シグネチャを使用して、いくつかのサービスを実装できます。 たとえば、何もしないサービス:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(他のサービスのソースコードを参照してください- エコーサービス 、 エコークライアント
および寿命コントローラー 。
ノードは、複数のサービスを開始できるオブジェクトです(リソースチェーンの起動は、Cakeパターンによって保証されます)。
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
このノードに必要な構成の正確なタイプを示していることに注意してください。 別のサービスに必要な構成タイプの1つを指定し忘れると、コンパイルエラーが発生します。 また、適切なタイプのオブジェクトに必要なデータをすべて提供しないと、ノードを起動できません。
リモートホストに接続するには、実際のIPアドレスが必要です。 アドレスは、構成の残りの部分よりも後に認識される可能性があります。 したがって、ノード識別子をアドレスにマップする関数が必要です。
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
このような関数を実装するには、いくつかの方法があります。
- デプロイ前にアドレスがわかった場合、Scalaコードを生成できます。
アドレスし、アセンブリを開始します。 これにより、テストがコンパイルおよび実行されます。
この場合、関数は静的に認識され、マップ表示Map[NodeId, NodeAddress]
としてコードで表すことができます。 - 場合によっては、ノードの起動後にのみ有効なアドレスが認識されます。
この場合、「ディスカバリサービス」(ディスカバリ)を実装できます。これは、他のノードとすべてのノードがこのサービスに登録され、他のノードのアドレスを要求する前に実行されます。 -
/etc/hosts
変更できる場合は、事前定義されたホスト名(my-project-main-node
やecho-backend
)を使用して、これらの名前をバインドできます
展開中にIPアドレスを使用します。
この投稿の枠組みでは、これらのケースをより詳細に検討しません。 私たちのために
おもちゃの例では、すべてのノードに1つのIPアドレス127.0.0.1
ます。
次に、分散システムの2つのオプションを検討します。
- 1つのノード上のすべてのサービスの配置。
- エコーサービスとエコークライアントの異なるノードへの配置。
単一ノード構成:
object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton /** Type safe service port specification. */ override def portNumber: PortNumber = 8088 // configuration of client /** We'll use the service provided by the same host. */ def echoServiceDependency = echoService override def testMessage: UrlPathElement = "hello" def pollInterval: FiniteDuration = 1.second // lifecycle controller configuration def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 requests, not 9. }
オブジェクトは、クライアントとサーバーの両方の構成を実装します。 生涯の構成もlifetime
後にプログラムを終えるために使用されます。 (Ctrl-Cも機能し、すべてのリソースを正しく解放します。)
同じ構成特性と実装のセットを使用して、 2つの別個のノードで構成されるシステムを作成できます。
object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig { // NB! dependency specification def echoServiceDependency = NodeServerConfig.echoService def pollInterval: FiniteDuration = 1.second def lifetime: FiniteDuration = 10500.milliseconds // additional 0.5 seconds so that there are 10 request, not 9. def testMessage: String = "dolly" }
重要! サービスのバインドがどのように実行されるかに注目してください。 別のノードの依存関係メソッドの実装として、1つのノードによって実装されるサービスを示します。 依存関係のタイプはコンパイラーによってチェックされます。 プロトコルのタイプが含まれます。 起動すると、依存関係にターゲットノードの正しい識別子が含まれます。 このスキームのおかげで、ポート番号を一度だけ正確に示し、常に正しいポートを参照することが保証されます。
この構成では、変更せずに同じサービス実装を使用します。 唯一の違いは、異なるサービスセットを実装する2つのオブジェクトがあることです。
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
最初のノードはサーバーを実装し、サーバー構成のみが必要です。 2番目のノードはクライアントを実装し、構成の別の部分を使用します。 また、両方のノードでライフタイムを管理する必要があります。 サーバーノードはSIGTERM
によって停止されるまで無期限に実行され、クライアントノードはしばらくして終了します。 起動アプリケーションを参照してください。
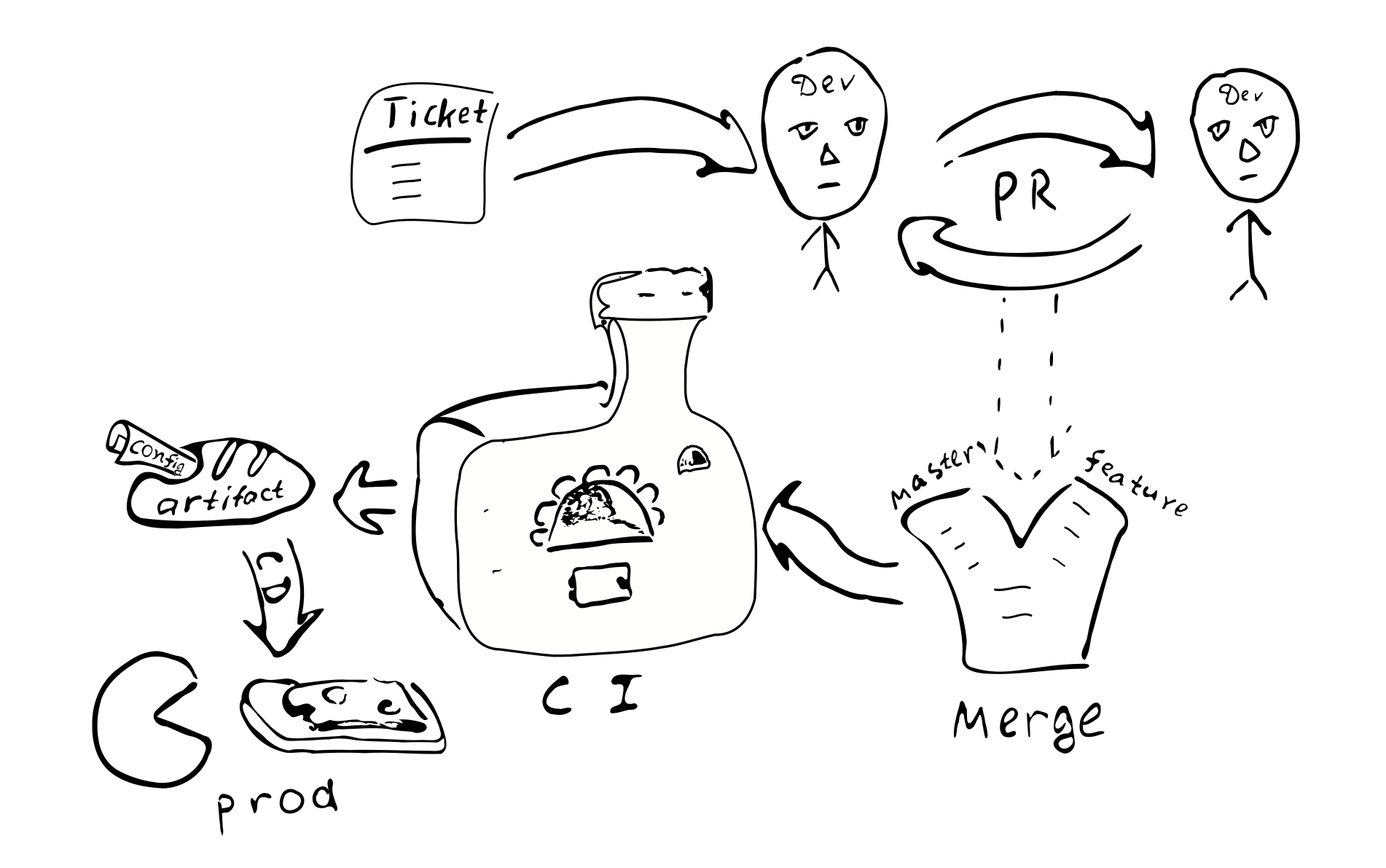
一般的な開発プロセス
この構成アプローチが開発プロセス全体にどのように影響するかを見てみましょう。
構成は残りのコードとともにコンパイルされ、アーティファクト(.jar)が生成されます。 どうやら、構成を別のアーティファクトに入れるのが理にかなっています。 これは、同じコードに基づいて多くの構成を持つことができるためです。 繰り返しますが、さまざまな構成ブランチに対応するアーティファクトを生成できます。 構成とともに、ライブラリの特定のバージョンへの依存関係が保持され、このバージョンの構成を展開することを決定するたびに、これらのバージョンは永久に保持されます。
構成の変更はすべてコードの変更になります。 したがって、そのような各
変更は、通常の品質保証プロセスによってカバーされます。
バグトラッカーのチケット-> PR->レビュー->対応するブランチとマージ->
統合->展開
コンパイルされた構成を実装する主な結果:
構成は、分散システムのすべてのノードで調整されます。 すべてのノードが単一のソースから同じ構成を受け取るという事実のため。
1つのノードのみで構成を変更するのは問題です。 したがって、「構成のドリフト」はほとんどありません。
小さな設定変更を行うことはより難しくなっています。
ほとんどの構成変更は、開発プロセス全体の一部として行われ、レビューされます。
本番構成を保存するために別のリポジトリが必要ですか? このような構成には、パスワードやその他の秘密情報、アクセスを制限したい情報が含まれる場合があります。 これに基づいて、最終構成を別のリポジトリに保存することは理にかなっているようです。 構成を2つの部分に分割できます。1つはパブリック構成設定を含み、もう1つはアクセス制限設定を含みます。 これにより、ほとんどの開発者は共通のパラメーターにアクセスできます。 この分離は、デフォルト値を含む中間特性を使用して簡単に実現できます。
可能なバリエーション
コンパイル済みの構成といくつかの一般的な代替案を比較してみましょう。
- ターゲットマシン上のテキストファイル。
- Key-Value集中ストレージ(
etcd
/etcd
)。 - プロセスを再起動せずに再構成/再起動できるコンポーネントを処理します。
- アーティファクトとバージョン管理外の構成のストレージ。
テキストファイルは、小さな変更の点で非常に柔軟です。 システム管理者は、リモートノードに移動して、対応するファイルを変更し、サービスを再起動できます。 ただし、大規模システムの場合、このような柔軟性は望ましくない場合があります。 加えられた変更から、他のシステムには痕跡はありません。 誰も変更をレビューしません。 誰がどのような理由で変更を行ったかを確定することは困難です。 変更はテストされていません。 システムが分散されている場合、管理者は他のノードで対応する変更を忘れることがあります。
(また、コンパイルされた構成を使用しても、将来テキストファイルを使用する可能性をブロックしないことに注意してください。出力として同じタイプのConfig
を提供するパーサーとバリデータを追加するだけで十分です。テキストファイルには追加のコードが必要なため、テキストファイルを使用するシステムの複雑さよりも低くなります。)
集中化されたキーと値のストレージは、分散アプリケーションのメタパラメーターを分散するための優れたメカニズムです。 構成パラメーターとは何か、そしてデータとは何かを決定する必要があります。 関数C => A => B
があり、パラメーターC
めったに変化せず、データA
が頻繁にあるとします。 この場合、 C
は構成パラメーターであり、 A
はデータであると言えます。 構成パラメーターは、通常、データよりも頻繁に変更されないという点で、データとは異なるようです。 また、通常、データは1つのソース(ユーザー)から取得され、構成パラメーターは別のソース(システム管理者)から取得されます。
プログラムを再起動せずにほとんど変更しないパラメーターを更新する必要がある場合、多くの場合、パラメーターの配信、保存、解析、チェック、不正な値の処理が必要になるため、プログラムの複雑化につながる可能性があります。 したがって、プログラムの複雑さを軽減するという観点からは、プログラム中に変更できるパラメーターの数を減らすこと(または、そのようなパラメーターをまったくサポートしないこと)は理にかなっています。
この投稿の観点から、静的パラメーターと動的パラメーターを区別します。 サービスのロジックでプログラム中にパラメーターを変更する必要がある場合、そのようなパラメーターを動的に呼び出します。 それ以外の場合、パラメーターは静的であり、コンパイル済み構成を使用して構成できます。 動的再構成の場合、オペレーティングシステムのプロセスを再起動する方法と同様に、プログラムの一部を新しいパラメーターで再起動するメカニズムが必要になる場合があります。 (システムの複雑さが増すにつれて、リアルタイムの再構成を回避することをお勧めします。可能であれば、プロセスの再起動には標準のOS機能を使用することをお勧めします。)
人々が動的な再構成を考慮することを強制する静的な構成を使用する重要な側面の1つは、構成の更新後のシステムの再起動にかかる時間(ダウンタイム)です。 実際、静的構成を変更する必要がある場合は、新しい値を有効にするためにシステムを再起動する必要があります。 ダウンタイムの問題は、システムごとに重大度が異なります。 場合によっては、負荷が最小のときに再起動をスケジュールできます。 継続的なサービスを提供する場合は、 「排水接続」(AWS ELB接続の排水)を実装できます。 同時に、システムを再起動する必要がある場合、このシステムの並列インスタンスを起動し、バランサーをそれに切り替えて、古い接続が完了するまで待ちます。 すべての古い接続が完了したら、古いシステムインスタンスをオフにします。
ここで、アーティファクトの内部または外部に構成を保存する問題を検討します。 アーティファクト内に構成を保存する場合、少なくとも、アーティファクトのアセンブリ中に構成が正しいことを確認する機会がありました。 構成が制御された成果物の外側にある場合、このファイルに誰が、なぜ変更を加えたかを追跡することは困難です。 これはどれほど重要ですか? 私たちの意見では、多くの生産システムにとって、安定した高品質の構成が重要です。
アーティファクトのバージョンにより、作成日時、含まれる値、有効化/無効化される機能、構成の変更の責任者を決定できます。 もちろん、アーティファクト内に構成を保存するには多少の労力が必要なので、十分な情報に基づいて決定する必要があります。
長所と短所
提案された技術の長所と短所について詳しく説明したいと思います。
メリット
以下は、コンパイルされた分散システム構成の主な機能のリストです。
- 静的構成チェック。 それを確実にすることができます
. - . . Scala , . ,
trait' , , val', (DRY) . (Seq
,Map
, ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- . mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList
(case class') . - , : (
package
,import
, ;override def
' , ). , DSL. , (, XML), . - .
おわりに
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
謝辞
, .