プロメテウスの輸出業者であるKube Eagleを作成しました。 これは、中小規模のクラスターのリソースをよりよく理解するのに役立つクールなものであることが判明しました。 その結果、適切な種類のマシンを選択し、ワークロードのアプリケーションリソース制限を構成したため、100ドル以上節約できました。
Kube Eagleの利点について説明しますが、まず大騒ぎが起こった理由と、高品質の監視が必要だった理由を説明します。
4〜50ノードのクラスターをいくつか管理しました。 各クラスター-最大200のマイクロサービスとアプリケーション。 利用可能なハードウェアをより有効に活用するために、ほとんどの展開はバースト可能なRAMおよびCPUリソースで構成されました。 そのため、ポッドは必要に応じて利用可能なリソースを取得でき、同時にこのノード上の他のアプリケーションに干渉しません。 まあ、それは素晴らしいことではありませんか?
また、クラスターは比較的少ないCPU(8%)とRAM(40%)を消費しましたが、ノードで利用可能なメモリよりも多くのメモリを割り当てようとすると、ハースが混雑するという問題が絶えず発生していました。 次に、Kubernetesリソースを監視するためのパネルが1つだけありました。 以下がその1つです。
cAdvisorメトリックのみを備えたGrafanaダッシュボード
このようなパネルでは、大量のメモリとCPUを消費するノードは問題になりません。 問題は理由を理解することです。 ポッドを所定の位置に保持するために、もちろん、すべてのポッドに保証されたリソースを構成できます(要求されたリソースは制限に等しくなります)。 しかし、これは鉄の賢い使い方ではありません。 クラスターには数百ギガバイトのメモリがあり、一部のノードは飢star状態にあり、他のノードは4〜10 GBの予備がありました。
Kubernetesスケジューラは、利用可能なリソース全体にワークロードを不均等に分散していることがわかりました。 Kubernetesスケジューラは、さまざまな構成を考慮します:アフィニティ、汚染および許容ルール、使用可能なノードを制限できるノードセレクター。 しかし、私の場合、そのようなものはなく、ポッドは各ノードで要求されたリソースに応じて計画されました。
囲炉裏では、最も空きリソースが多く、要求条件を満たすノードが選択されました。 ノード上の要求されたリソースが実際の使用と一致しないことが判明したため、Kube Eagleとそのリソースを監視する機能が助けになりました。
ほとんどすべてのKubernetesクラスターは、 NodeエクスポーターとKube State Metricsでのみ追跡されています。 Node ExporterはI / Oとディスク、CPUとRAMの統計情報を提供し、Kube State MetricsはリクエストやCPUおよびメモリリソースの制限などのKubernetesオブジェクトメトリックスを表示します。
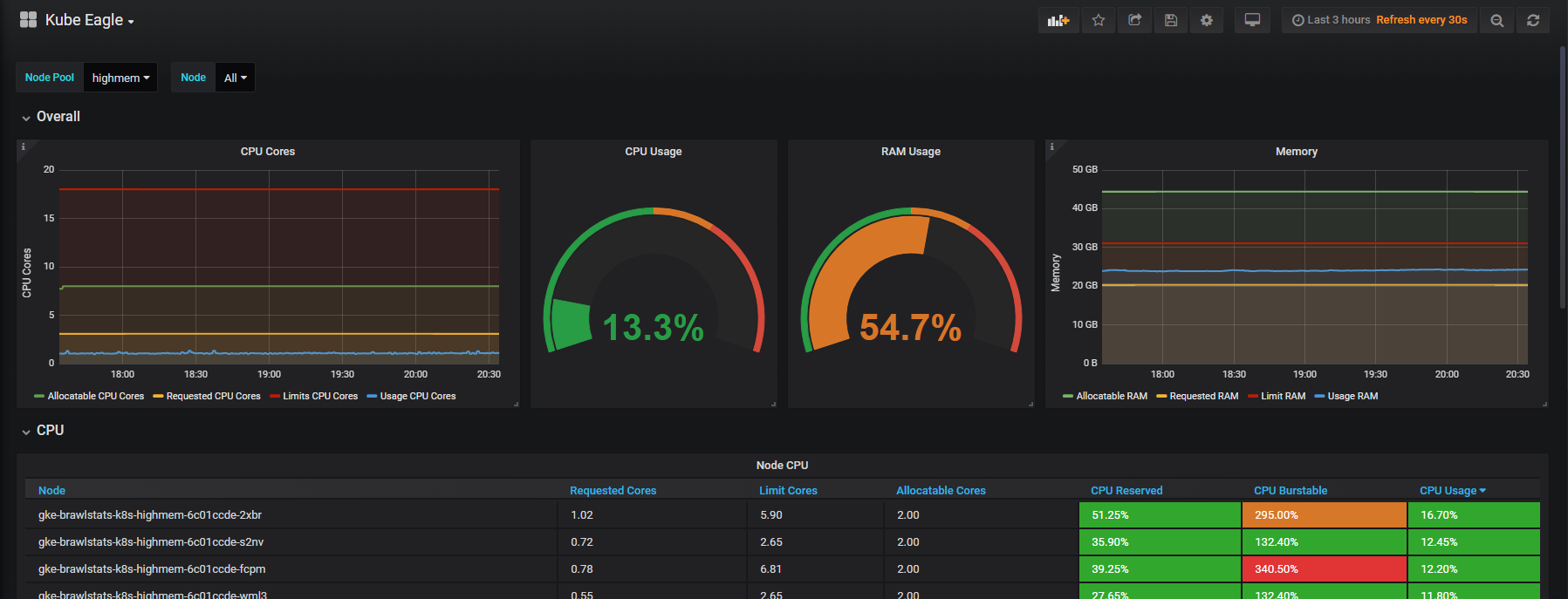
Grafanaで使用メトリックスとクエリおよび制限メトリックスを組み合わせて、問題に関するすべての情報を取得する必要があります。 簡単に聞こえますが、実際、これら2つのツールでは、ラベルの呼び出し方法が異なり、一部のメトリックにはメタデータラベルがまったくありません。 Kube Eagleはそれ自体ですべてを実行し、パネルは次のようになります。
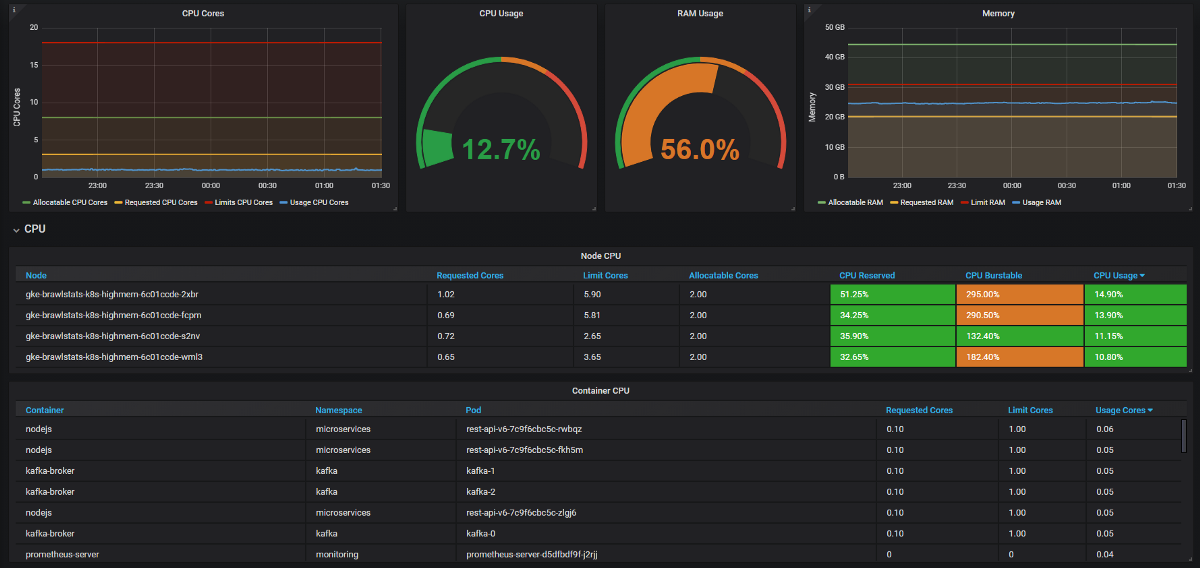
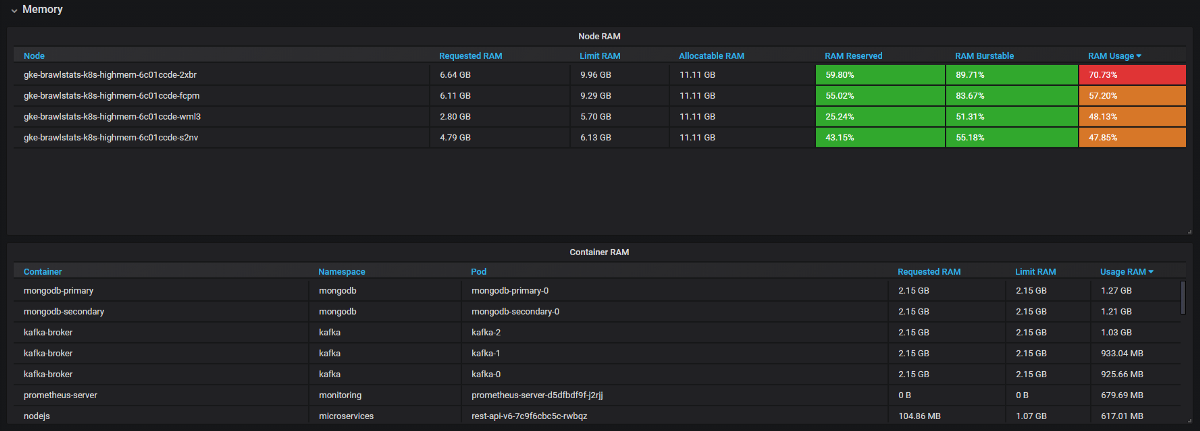
リソースに関する多くの問題を解決し、機器を節約しました。
- 一部の開発者は、マイクロサービスに必要なリソースの数を知りませんでした(または単に気にしませんでした)。 リソースに対する間違ったリクエストを見つけることは何もありませんでした。そのためには、消費とリクエストおよび制限を知る必要があります。 現在、Prometheusメトリックを確認し、実際の使用状況を監視し、クエリと制限を微調整します。
- JVMアプリケーションは、必要な量のRAMを使用します。 ガベージコレクターは、75%を超える場合にのみメモリを解放します。 また、ほとんどのサービスにはバースト可能なメモリがあるため、JVMは常にメモリを占有しています。 したがって、これらのJavaサービスはすべて、予想よりはるかに多くのRAMを消費しました。
- 一部のアプリケーションは大量のメモリを要求し、Kubernetesスケジューラはこれらのノードを他のアプリケーションに提供しませんでしたが、実際には他のノードよりも自由でした。 1人の開発者が誤ってリクエストに余分な数字を追加し、RAMの大きな塊をつかみました。2ではなく20 GBです。誰も気付きませんでした。 アプリケーションには3つのレプリカがあったため、3つのノードが影響を受けました。
- リソース制限を導入し、正しいリクエストでポッドを再計画し、すべてのノードで鉄を使用するという完璧なバランスを取りました。 通常、いくつかのノードを閉じることができます。 そして、間違ったマシン(CPU指向であり、メモリ指向ではない)があることがわかりました。 タイプを変更し、さらにいくつかのノードを削除しました。
まとめ
クラスター内のバースト可能なリソースを使用すると、既存のハードウェアをより効率的に使用できますが、Kubernetesスケジューラーはリソース要求でポッドをスケジュールしますが、これは面倒です。 1石で2羽の鳥を殺すには、問題を回避し、資源を最大限に活用するために、適切な監視が必要です。 Kube Eagle (PrometheusエクスポーターおよびGrafanaダッシュボード)はこれに役立ちます。