
CPU速度の改善は鈍化しており、半導体業界はアクセラレータカードに切り替えて、結果が大幅に改善され続けています。 Nvidiaはこの移行の恩恵を最も受けていますが、ニューラルネットワークアクセラレータ、FPGA、GoogleのTPUなどの製品の研究を促進するのと同じトレンドの一部です。 これらのアクセラレータは近年、電子機器の速度を信じられないほど向上させ、ムーアの法則の減速に関連して、多くの人が新しい開発の道を示すことを期待し始めました。 しかし、新しい科学的研究は、実際にはすべての人が望むほどバラ色ではないことを示唆しています。
GPU、TPU、FPGA、ASICなどの特別なアーキテクチャは、汎用CPUとはまったく異なる動作をする場合でも、x86、ARM、またはPOWERプロセッサーと同じ機能ノードを使用します。 そして、これは、これらのアクセラレータの速度の増加も、ある程度、トランジスタのスケーリングに関連する改善に依存することを意味します。 しかし、これらの改善のどの程度が生産技術の改善とムーアの法則に関連する密度の増加に依存しており、これらのプロセッサが対象とするターゲット領域の改善にどの部分が関係しているのでしょうか? トランジスタのみに関連する改善点は何ですか?
プリンストン大学電気工学の准教授David Wenzlafと彼の大学院生Adi Fuchsは、改善の速度を測定できるモデルを作成しました。 彼らのモデルは、ユニットの改善に伴う利点を数値的に評価するために、さまざまな機能ユニットに基づいて作成された、さまざまな容量の1612 CPUと1001 GPUの特性を使用しています。 WenzlafとFuchsは、CMOS(CMOS-Driven Return、CDR)の進捗に関連するパフォーマンスを改善するためのメトリックを作成しました。
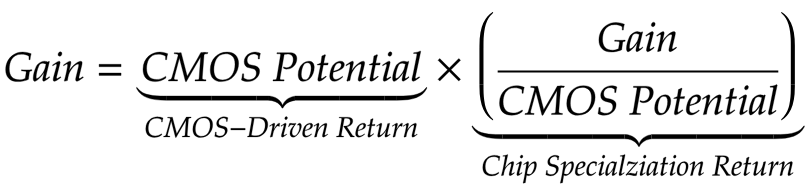
チームは落胆的な結論に達しました。 チップの特殊化によって得られる利点は、基本的に長期的にシリコンのミリメートルに配置されるトランジスタの数、および各新しい機能ユニットに関連するこれらのトランジスタの改善に関連しています。 さらに悪いことに、CMOSのスケールを改善せずにアクセラレータ回路を改善することからどれだけの速度を引き出すことができるかという根本的な制限があります。
上記のすべてが長期的に当てはまることが重要です。 WenzlafとFuchsの研究は、加速器の初期試運転で速度がしばしば急激に上昇することを示しています。 時間が経つにつれて、最適な加速方法が研究され、ベストプラクティスが説明されるようになると、研究者は最も最適なアプローチになります。 さらに、アクセラレーターでは、よく研究された並列化可能な領域(GPU)からの明確に定義されたタスクが十分に解決されます。 ただし、これは、タスクをアクセラレータに適したものにする同じプロパティが、長期的にこのアクセラレーションから得られる利点を制限することも意味します。 チームはこの問題を「デッドロックアクセラレータ」と呼びました。
そして、高性能コンピューティング市場はおそらくこれをしばらくの間感じていたでしょう。 2013年に、元規模のスーパーコンピューターへの困難な道のりについて書きました。 そして、それでも、Top500は、アクセラレータがパフォーマンスレーティングを1回飛躍させると予測しましたが、速度向上の速度を上げることはありませんでした。

ただし、これらの発見の結果は、高性能コンピューティング市場を超えています。 例えば、GPUを研究したWenzlafとFuchsは、改良されたCMOSに起因しない利点は非常に小さいことを発見しました。
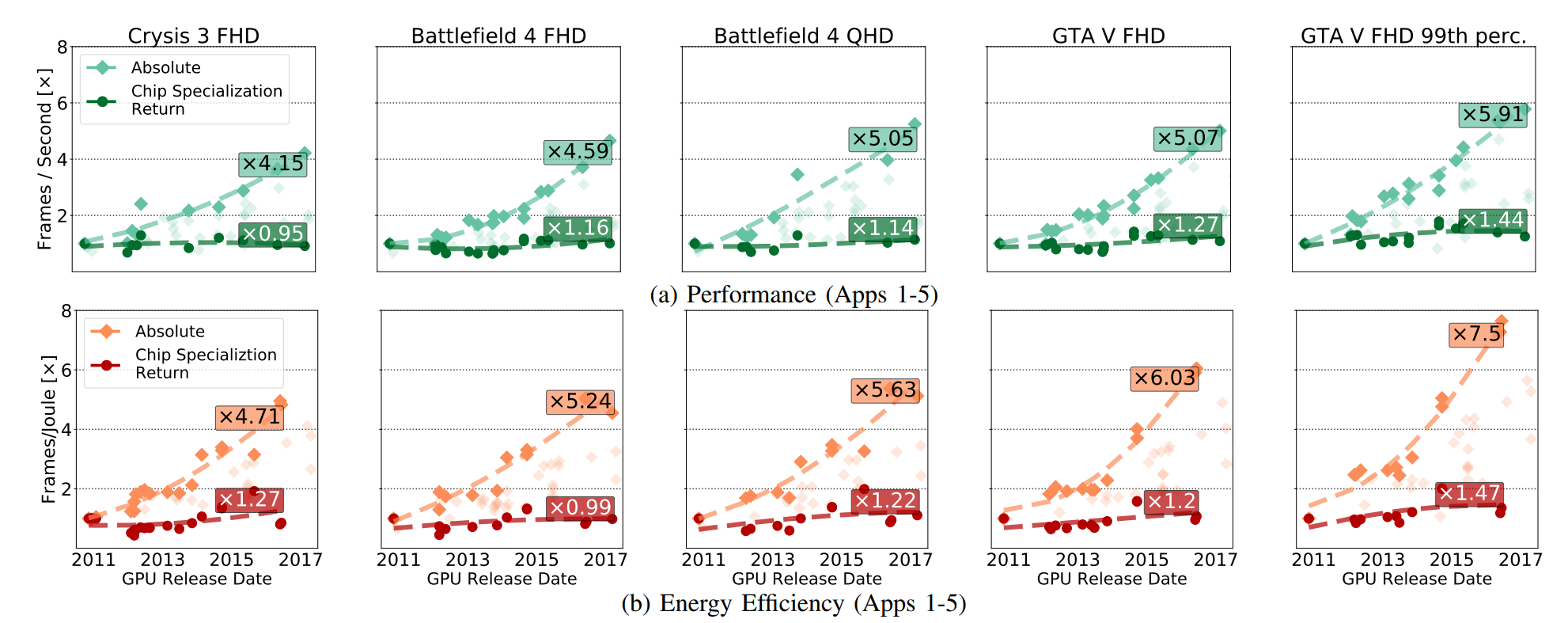
図 GPUの絶対的なパフォーマンスの向上が示されています(CMOSの開発から得られた利点を含む)。これらの利点は、CSRの開発のみによって現れました。 CSRは、GPU回路からCMOSテクノロジーのすべてのブレークスルーを削除した場合に残る改善に関するものです。
次の図は、数量の関係を明らかにしています。
CSRを減らすことは、GPUを絶対数で遅くすることを意味しません。 フックスが書いたように:
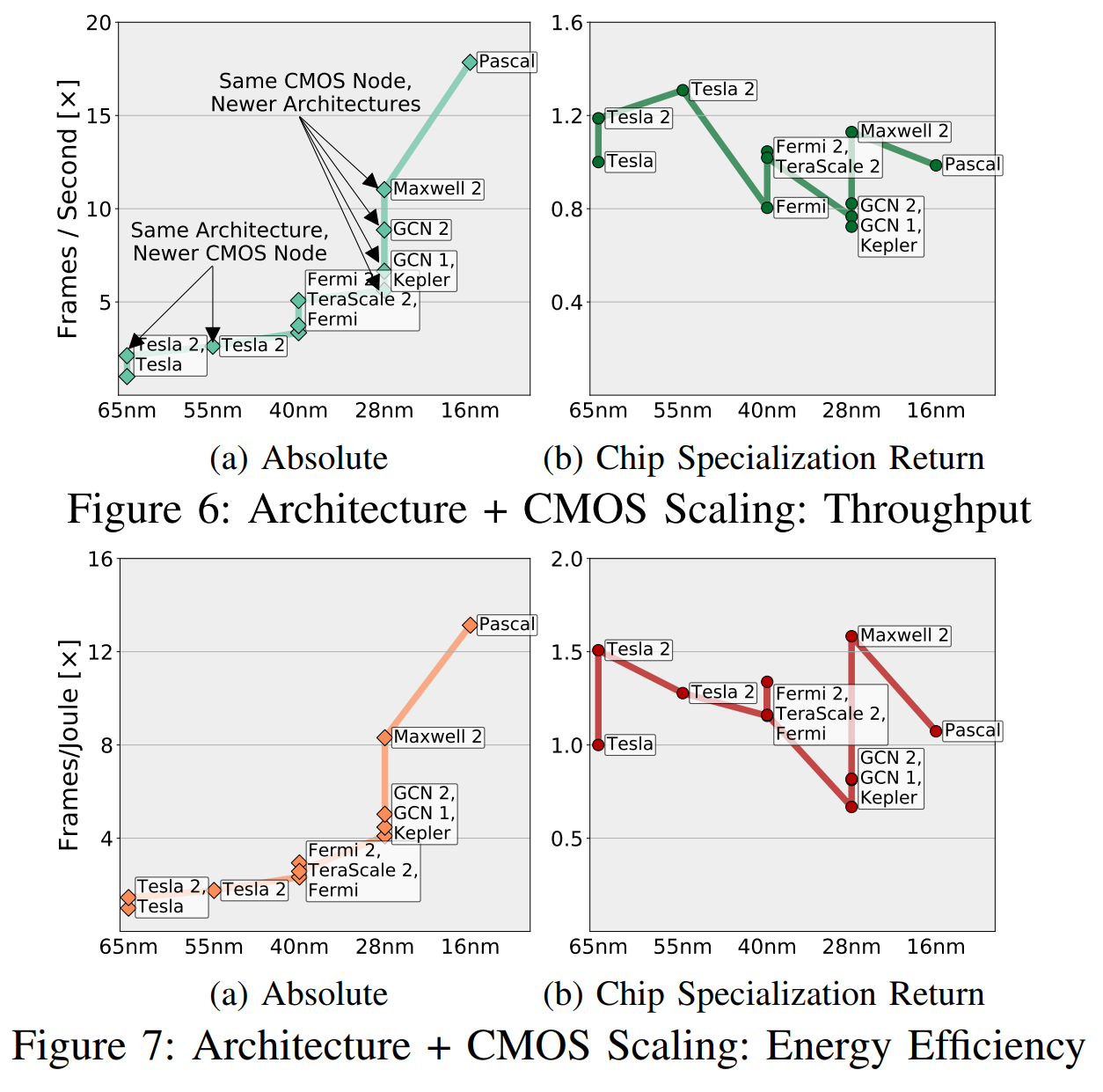
CSRは「CMOSの可能性に基づいて」利益を正規化し、この「ポテンシャル」はトランジスタの数と速度の違い、エネルギーの使用効率、面積などを考慮します。 (異なる世代のCMOS)。 図 6、さまざまな組み合わせですべてのアプリケーションの測定速度を三角測量し、十分な一般的なアプリケーション(5未満)がない組み合わせ間の推移的な関係を使用して、「アーキテクチャ+ CMOSノード」の組み合わせのおおよその比較を行いました。
直感的に、これらのグラフは図のように理解できます。 6aは、「エンジニアとマネージャーが見るもの」を示しています。 6bは「CMOSの可能性を除いて、私たちが見るもの」です。 新しいチップが前のチップよりも優れているかどうかは、トランジスタやスペシャライゼーションが優れているためか、それよりも先に進んでいるかどうかを懸念することをお勧めします。
GPU市場は、明確に定義され、設計され、専門化されており、AMDとNvidiaの両方が、回路を改善するために互いを先取りするあらゆる理由を持っています。 しかし、それにもかかわらず、加速の大部分はCMOSに関連する要因によるものであり、CSRによるものではないことがわかります。
科学者は、市場の成長により時間が経つにつれて相対的な改善が多少なりとも変わったとしても、そのような特性に該当するビデオコーデックを処理するためのFPGAおよび特別なマザーボードも研究しました。 加速に積極的に応答できるのと同じ特性により、最終的に加速器の効率を改善する能力が制限されます。 FuchsとWenzlafはGPUについて次のように書いています。「GPUグラフィックスのフレームレートは16倍に増加していますが、速度とエネルギー効率のさらなる改善はそれぞれ1.4〜2.4倍と1.4〜1.7倍になると考えています。」 。 AMDとNvidiaには、CMOSを改善して速度を上げることができる特別な操作スペースがありません。
この作業の意味は重要です。 彼女は、ムーアの法律が機能しなくなったときに、建築分野に固有の速度が大幅に向上することはもはやないと言います。 また、チップ設計者が固定数のトランジスタで性能の改善に集中できたとしても、よく研究されたプロセスにはほとんど改善の余地がないという事実により、これらの改善は制限されます。
この研究は、コンピューティングに対する根本的に新しいアプローチを開発する必要性を示しています。 1つの潜在的な選択肢は、 Intel Mesoアーキテクチャです。 FuchsとWenzlafは、不揮発性メモリをアクセラレータとして使用する可能性の研究を含め、CMOSの範囲を超える代替材料や他のソリューションを使用することも提案しました。