
ディスクリートエントリレベルグラフィックスカードIntel Graphics Xe、公式発表はGDC 2019ゲームカンファレンスで3月20日に開催されました
Intelは、Gen11 GPUのドキュメントを公開し、前世代との違いを説明しています。 Intel Gen11アーキテクチャは、ディスクリートXeグラフィックカードの将来のアーキテクチャの基盤になると予想されるため、ここで説明するテクノロジは、これらのグラフィックカードに実装されている機能の少なくとも一部のプレビューとして見ることができます。 これまでのところ、Intelは将来のグラフィックスカードについては何も言っておらず、数枚の写真(またはレンダリング)のみを示した。

Intel Coreプロセッサ、システムオンチップ(SoC)、および内部接続のリングシステム(Ring Interconnect)のアーキテクチャ
歴史的に、デスクトップコンピューターおよび一部のモバイルチップ用のIntelミッドレンジグラフィックプロセッサーGT2は、AMDチップよりもパフォーマンスが劣っていました。 そのような比較において、Intelは歴史的に、AMD Bulldozerマイクロアーキテクチャーから派生したAPUと比較して、より強力なプロセッサーで優位性を獲得しています。 今、状況は変わりました。 Ryzenははるかに効率的なプロセッサコアを備えており、AMD RyzenモバイルプロセッサはIntelとの競争力がはるかに優れています。 したがって、後者はGPUのパフォーマンスの問題を解決するなど、何かを行う必要があります。

詳細なGen11ブロック図
技術文書により、Gen11のパフォーマンスを判断することは困難です。 しかし、一部の専門家は 、Intelがより効果的にAMDと競合できると信じています。 少なくともこれまで以上に効果的です。
新しいIntel GT2アーキテクチャは、Skylakeクラスのプロセッサの24ユニットと比較して、64 EU実行ユニットを提供します。 このチップ上のリソースの大幅な拡張により、前世代と比較して全体的なパフォーマンスが向上します。 次の表は、グラフィックスサブシステムGen9とGen11の比較特性を示しています。
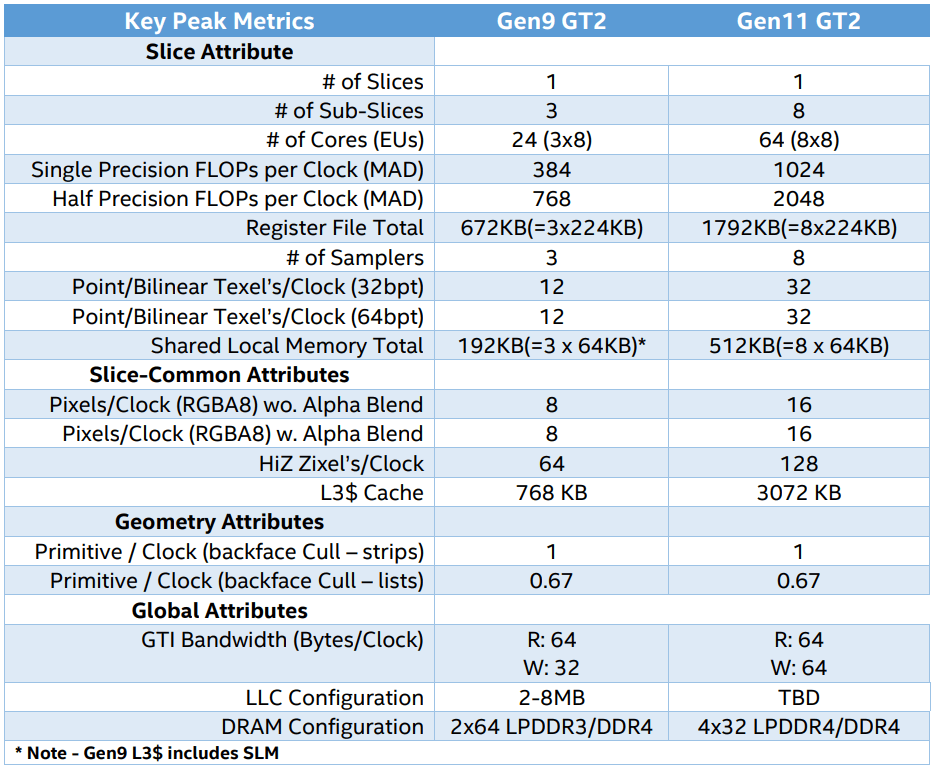
主要な指標Gen9およびGen11
技術的な特性に基づいて、Gen11の計算性能は約2.67倍に向上し、テクスチャのスループット(テクスチャサンプリング)も向上します。 ラスター演算ユニット(ROP)の帯域幅は2倍になり、サイクルごとの高Zテストの数も増えました。
L3キャッシュは4倍になり、GPUの書き込みスループットはクロックあたり64バイトに倍増しました。 DDR4の使用中のメモリ帯域幅は同じままである必要がありますが、LPDDR4サポートは理論的にはより高速のクロック速度を可能にします。
最終レベルのキャッシュは、データトラフィックを削減するためにGPUとCPUの間で共有されます。 ビデオデコーダーブロックが改善され、ビットレートが削減されました。 4Kおよび8Kの複数のストリームを同時にデコードできます。 HDビデオの適応同期と改善されたデコードのサポートが追加されました。
GPUには共有ローカルメモリがあり、読み取り時にL3キャッシュへのアクセスをブロックしません。 Intelは、これにより待ち時間が短縮され、アトミック操作の効率が向上すると主張しています。
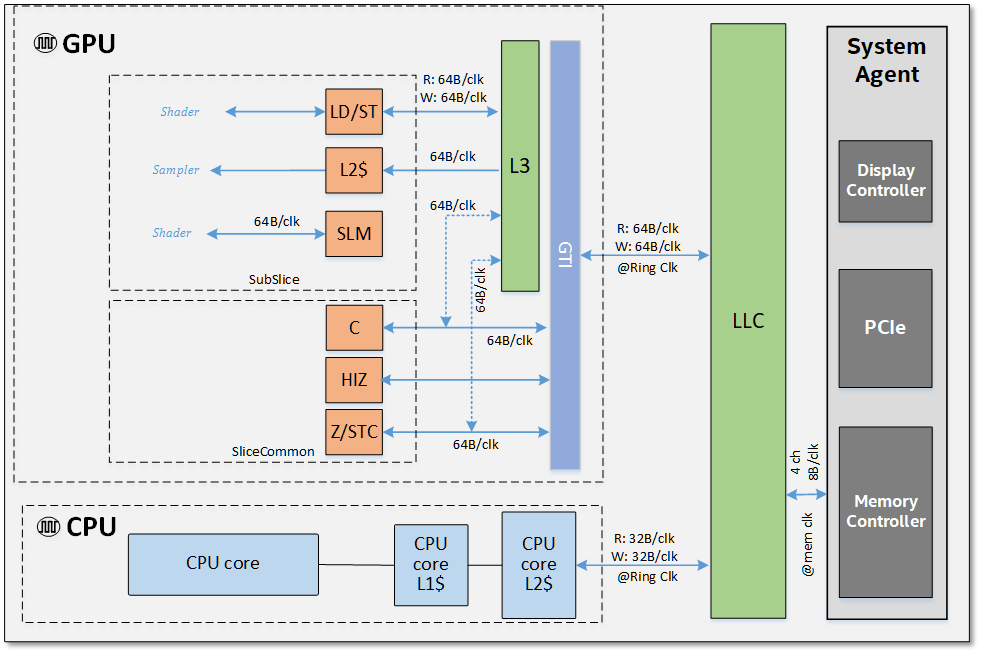
SoCチップレベルのメモリ階層とその最大理論スループット
Intelは、Gen11の全体的なメモリ帯域幅を大幅に改善したと主張しています。
このドキュメントでは、Intelがグラフィックアクセラレータに実装した2つの新しいテクノロジーについて説明しています。
- 粗いピクセルシェーディング(粗いピクセルシェーディング、CPS)。
- 位置によるシェーディング(位置のみのシェーディング、POSH)。
粗いピクセルシェーディングはGPUの負荷を軽減し、画像のレンダリングに使用されるカラーサンプルの数を減らします。 スクリーンショットは、CPSがレンダリング品質にほとんど影響を与えないことを示しています。

2560×1440の解像度でのゲームCitadel 1からのショット(左のピクセルレート1×1と右の2×2)。 粗いピクセルシェーディングはシェーダーコールの回数を減らしますが、高ピクセル密度のディスプレイでは実質的に顕著な違いはありません。 比較のため、解像度1280×720のアンチエイリアスなしのスケーリングされた画像も表示されます
ピクセルシェーダーの呼び出し回数を減らすと、エネルギーが節約され、パフォーマンス、つまりフレームレートが20〜40%向上します。

この画像では、赤いフレーム内のオブジェクトはカメラからかなり離れており、全体的な画質にとってほとんど重要でないと識別されているため、画質に目立った影響を与えることなくディテールを減らすことができ、その後フレームレートが増加します
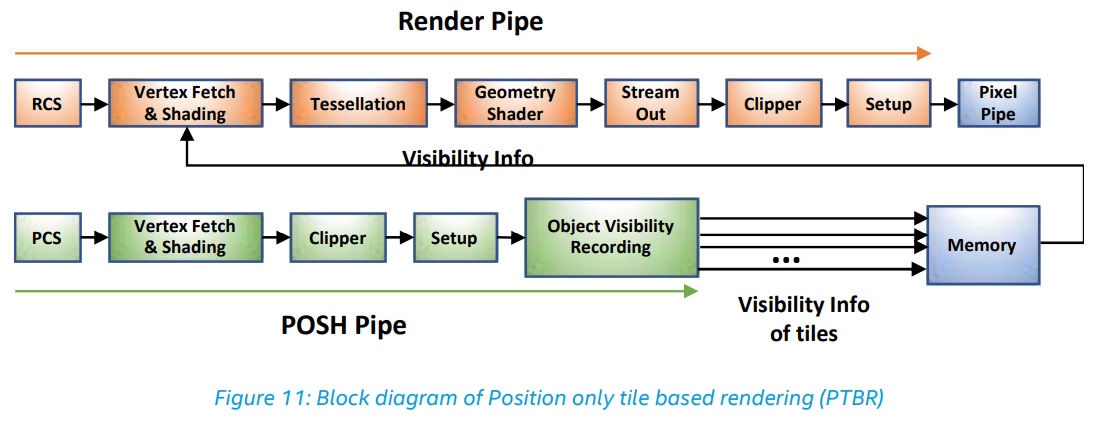
POSHパイプラインは、メインアプリケーションと並行してポジションシェーダーを実行します。これにより、通常、結果をより高速に生成できます、とドキュメントには書かれています。 これは、位置のみのタイルベースのレンダリング(PTBR)レンダリングシステムの一部です。
一般的に、Gen11はIntelプロセッサの重要なアップデートです。 AMD Ryzen Mobileの最初の2世代は、Skylakeの弱いグラフィックと競合していました。 ExtremeTech は 、第3世代のRyzen Mobile APUが発表されるたびに、はるかに強力なIntelチップと競合する必要があると述べ ています 。