UPD:コメントに記載されているように、例は完全ではありません。 著者はこの問題に対する最善の解決策を探しているのではなく、アルゴリズムの複雑さを「指で」説明することを目標としています。
アルゴリズムの複雑さを説明するには、Big O表記が必要です。 このために、時間の概念が使用されます。 このトピックは多くの人にとって恐ろしいものであり、プログラマは「順序Nの時間」について話すことを避けるのが一般的です。
Big Oの観点からコードを評価できる場合、おそらく「賢い人」と見なされます。 そして、おそらくあなたはあなたの次のインタビューを受けます。 コードの複雑さをn ^ 2に対してn log nに減らすことができるかどうかという質問にとどまりません。
データ構造
データ構造の選択は、特定のタスク、つまりデータのタイプとその処理のアルゴリズムに依存します。 さまざまなデータ構造(.NETまたはJavaまたはElixir)が特定のタイプのアルゴリズム用に作成されました。
多くの場合、特定の構造を選択して、一般に受け入れられているソリューションを単純にコピーします。 ほとんどの場合、これで十分です。 しかし、実際には、アルゴリズムの複雑さを理解しないと、情報に基づいた選択をすることはできません。 データ構造のトピックは、アルゴリズムが複雑になった後にのみ渡すことができます。
ここでは、数字の配列のみを使用します(インタビューのように)。 JavaScriptの例。
最も単純なものから始めましょう:O(1)
5つの数字の配列を取得します。
const nums = [1,2,3,4,5];
最初の要素を取得する必要があるとします。 これにはインデックスを使用します。
const nums = [1,2,3,4,5]; const firstNumber = nums[0];
このアルゴリズムはどのくらい複雑ですか? 「まったく複雑ではありません-配列の最初の要素を取得するだけです」と言うことができます。 これは事実ですが、入力に応じて、結果を達成するために実行される操作の数を通じて複雑さを記述する方がより正確です(入力操作 )。
つまり、入力パラメーターの数が増えると、操作がいくつ増えるかということです。
この例では、配列に5つの要素があるため、5つの入力パラメーターがあります。 結果を取得するには、1つの操作を実行する必要があります(インデックスで要素を取得します)。 配列に100個の要素がある場合、いくつの操作が必要ですか? それとも1000? それとも100,000? すべて同じですが、必要な操作は1つだけです。
つまり、「可能なすべての入力データに対して1つの操作」-O(1)。
O(1)は、「次数1の複雑さ」(次数1)、または「アルゴリズムが一定/一定時間で実行される」(一定時間)として読み取ることができます。
O(1)アルゴリズムが最も効率的であると既に推測しました。
反復と「順序nの時間」:O(n)
次に、配列の要素の合計を見つけましょう。
const nums = [1,2,3,4,5]; let sum = 0; for(let num of nums){ sum += num; }
繰り返しますが、入力操作はいくつ必要ですか? ここでは、すべての要素をソートする必要があります。 各要素の操作。 配列が大きいほど、操作が多くなります。
Big O表記の使用:O(n)、または「次数nの複雑さ(次数n)」。 また、このタイプのアルゴリズムは「線形」と呼ばれるか、アルゴリズムが「線形にスケーリングされます」。
分析
集計をより効率的にできますか? 一般にそうではありません。 そして、配列が1から始まることが保証されていることがわかっている場合、ソートされ、ギャップはありませんか? 次に、式S = n(n + 1)/ 2(nは配列の最後の要素)を適用できます。
const sumContiguousArray = function(ary){ //get the last item const lastItem = ary[ary.length - 1]; //Gauss's trick return lastItem * (lastItem + 1) / 2; } const nums = [1,2,3,4,5]; const sumOfArray = sumContiguousArray(nums);
このようなアルゴリズムは、O(n)よりもはるかに効率的です。さらに、「一定/一定時間」で実行されます。 O(1)です。
実際、複数の操作があります。配列の長さを取得し、最後の要素を取得し、乗算と除算を実行する必要があります。 それはO(3)または何かではありませんか? Big O表記では、実際のステップ数は重要ではありません。アルゴリズムを一定の時間で実行することが重要です。
一定時間アルゴリズムは常にO(1)です。 線形アルゴリズムでも同じです。実際、演算はO(n + 5)であり、Big Oでは表記はO(n)です。
最良の解決策ではない:O(n ^ 2)
配列の重複をチェックする関数を書きましょう。 入れ子ループソリューション:
const hasDuplicates = function (num) { //loop the list, our O(n) op for (let i = 0; i < nums.length; i++) { const thisNum = nums[i]; //loop the list again, the O(n^2) op for (let j = 0; j < nums.length; j++) { //make sure we're not checking same number if (j !== i) { const otherNum = nums[j]; //if there's an equal value, return if (otherNum === thisNum) return true; } } } //if we're here, no dups return false; } const nums = [1, 2, 3, 4, 5, 5]; hasDuplicates(nums);//true
配列の繰り返しがO(n)であることは既にわかっています。 入れ子になったループがあり、要素ごとに繰り返します-つまり O(n ^ 2)または「次数n平方の複雑さ」。
同じコレクションにネストされたループを使用するアルゴリズムは、常にO(n ^ 2)です。
「ログnの順序の複雑さ」:O(log n)
上記の例では、ネストされたループ自体(ネストされていることを考慮しない場合)の複雑さはO(n)です。 それは配列要素の列挙です。 このサイクルは、目的の要素が見つかるとすぐに終了します。 実際、すべての要素が列挙されるわけではありません。 しかし、Big O表記は常に最悪のシナリオを考慮します。探しているアイテムは最後のアイテムかもしれません。
ここでは、ネストされたループを使用して、配列内の特定の要素を検索します。 配列内の要素の検索は、特定の条件下で最適化できます-線形O(n)よりも優れています。
配列をソートします。 その後、バイナリ検索アルゴリズムを使用できます。配列を2つに分割し、不要なものを破棄し、残りを再び2つの部分に分割し、目的の値が見つかるまで繰り返します。 このタイプのアルゴリズムは、分割と征服と呼ばれます分割と征服。
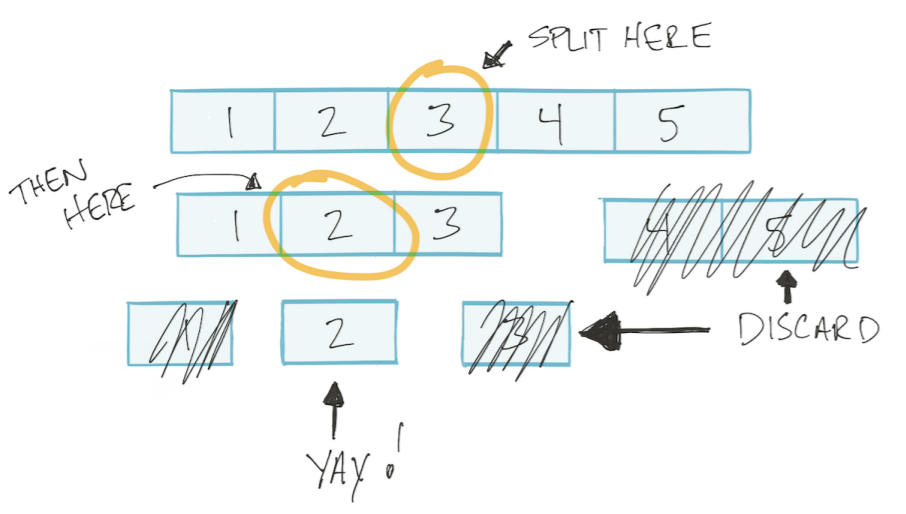
このアルゴリズムは対数に基づいています。
対数の簡単な概要
例について考えてみましょう。xはどうなりますか?
x ^ 3 = 8
8の立方根を取る必要があります-これは2になります。
2 ^ x = 512
対数を使用すると、問題は次のように記述できます。
log2(512)= x
「512の2を底とする対数はxです。」 「ベース2」、つまり 2つで考える-512を得るために2を掛ける必要がある回数。
バイナリ検索アルゴリズムでは、各ステップで配列を2つの部分に分割します。
私の追加。 つまり 最悪の場合、配列を2つの部分に分割できる限り多くの操作を行います。 たとえば、4つの要素の配列を2つの部分に何回分割できますか? 2回。 そして、8つの要素の配列? 3回。 つまり 分割数/操作= log2(n)(nは配列要素の数)。
操作の数の入力要素の数への依存性は、log2(n)として記述されることがわかります
したがって、Big O表記を使用すると、バイナリ検索アルゴリズムの複雑度はO(log n)になります。
O(n ^ 2)をO(n log n)に改善
配列の重複をチェックするタスクに戻りましょう。 配列のすべての要素を反復処理し、各要素について再度反復処理を行いました。 O(n)の内部でO(n)を実行しました。 O(n * n)またはO(n ^ 2)。
ネストされたループをバイナリ検索*に置き換えることができます。 つまり O(n)のすべての要素を調べる必要があり、O(log n)の内部で行う必要があります。 O(n * log n)またはO(n log n)になります。
const nums = [1, 2, 3, 4, 5]; const searchFor = function (items, num) { //use binary search! //if found, return the number. Otherwise... //return null. We'll do this in a later chapter. } const hasDuplicates = function (nums) { for (let num of nums) { //let's go through the list again and have a look //at all the other numbers so we can compare if (searchFor(nums, num)) { return true; } } //only arrive here if there are no dups return false; }
* インプリントを避けるために注意してください。 配列の重複をチェックするためにバイナリ検索を使用するのは悪い解決策です。 上記のコードリストに示されているアルゴリズムの複雑さをBig Oの用語で評価する方法のみを示しています。 良いアルゴリズムでも悪いアルゴリズムでも、この記事では重要ではありません;可視性は重要です。
Big Oの観点から考える
- コレクションアイテムの取得はO(1)です。 配列のインデックスで取得する場合でも、Big O表記の辞書のキーで取得する場合でも、O(1)になります。
- コレクションの繰り返しはO(n)です
- 同じコレクションのネストされたループはO(n ^ 2)です
- 常に分割して征服するO(log n)
- 分割と征服を使用する反復はO(n log n)です