
まえがき
このようなシンプルで非常に便利なユーティリティが世界にあります-BDelta 、そしてそれは私たちの生産プロセスに長い間根付いていました(そのバージョンはインストールできませんでしたが、それは間違いなく最後に利用できませんでした)。 バイナリパッチの構築という目的のために使用します。 リポジトリにあるものを見ると、少し悲しくなります。実際、かなり前に放棄されていて、多くのものがそこで非常に時代遅れでした(かつて私の前の同僚がそこにいくつかの修正を加えたが、それはずっと前でした)。 一般に、私はこのビジネスを復活させることにしました:私はフォークし、使用する予定のないものを捨て、 cmakeでプロジェクトを追い越し、「ホット」マイクロファンクションをインライン化し、スタックから大きな配列を削除しました、もう一度プロファイラーを運転しました-そして、時間の約40%がfwriteに費やされていることがわかりました...
それでは、fwriteはどうなっていますか?
このコードでは、fwrite(私の特定のテストケース:300 MB近いファイル間でパッチを構築し、入力データは完全にメモリ内にあります)は、小さなバッファーで何百万回と呼ばれます。 明らかに、このことは遅くなります。したがって、どういうわけかこの不名誉に影響を与えたいと思います。 さまざまな種類のデータソース、非同期入出力を実装する必要はありません。簡単に解決策を見つけたいと思いました。 最初に思いついたのは、バッファのサイズを増やすことでした
setvbuf(file, nullptr, _IOFBF, 64* 1024)
しかし、結果に大きな改善はありませんでした(現在、fwriteが約37%の時間を占めています)。これは、ディスクへのデータの頻繁な記録にまだ問題がないことを意味します。 「内部」のfwriteを確認すると、内部で次のようにFILE構造のロック/ロック解除が行われていることがわかります(疑似コード、分析全体はVisual Studio 2017で行われました)。
size_t fwrite (const void *buffer, size_t size, size_t count, FILE *stream) { size_t retval = 0; _lock_str(stream); /* lock stream */ __try { retval = _fwrite_nolock(buffer, size, count, stream); } __finally { _unlock_str(stream); /* unlock stream */ } return retval; }
プロファイラーによると、_fwrite_nolockは時間の6%しか占めておらず、残りはオーバーヘッドです。 私の特定のケースでは、スレッドセーフティは明らかに過剰です。fwrite呼び出しを_fwrite_nolockに置き換えることで犠牲にします-引数がスマートでなくてもかまいません。 合計:この簡単な操作により、結果を記録するコストが削減され、元のバージョンでは時間コストのほぼ半分になりました。 ところで、POSIXの世界には、同様の関数fwrite_unlockedがあります。 一般的に言えば、同じことが恐怖についても言えます。 したがって、#defineペアの助けを借りれば、不必要なロックが不要なクロスプラットフォームソリューションを手に入れることができます(これは頻繁に発生します)。
fwrite、_fwrite_nolock、setvbuf
元のプロジェクトから抽象化し、特定のケースのテストを開始しましょう。1バイトという非常に小さな部分に大きなファイル(512 MB)を記録します。 テストシステム:AMD Ryzen 7 1700、16 GB RAM、HDD 3.5 "7200 rpm 64 MBキャッシュ、Windows 10 1809、32ビットで構築されたbinar、最適化が含まれ、ライブラリは静的にリンクされています。
実験のサンプル:
#include <chrono> #include <cstdio> #include <inttypes.h> #include <memory> #ifdef _MSC_VER #define fwrite_unlocked _fwrite_nolock #endif using namespace std::chrono; int main() { std::unique_ptr<FILE, int(*)(FILE*)> file(fopen("test.bin", "wb"), fclose); if (!file) return 1; constexpr size_t TEST_BUFFER_SIZE = 256 * 1024; if (setvbuf(file.get(), nullptr, _IOFBF, TEST_BUFFER_SIZE) != 0) return 2; auto start = steady_clock::now(); const uint8_t b = 77; constexpr size_t TEST_FILE_SIZE = 512 * 1024 * 1024; for (size_t i = 0; i < TEST_FILE_SIZE; ++i) fwrite_unlocked(&b, sizeof(b), 1, file.get()); auto end = steady_clock::now(); auto interval = duration_cast<microseconds>(end - start); printf("Time: %lld\n", interval.count()); return 0; }
変数はTEST_BUFFER_SIZEになり、いくつかのケースでは、fwrite_unlockedをfwriteに置き換えます。 バッファサイズを明示的に設定せずにfwriteの場合から始めましょう(setvbufと関連コードをコメントアウト):時間27048906μs、書き込み速度-18.93 Mb / s。 バッファサイズを64 Kbに設定します。時間-25037111μs、速度-20.44 Mb / s。 次に、setvbufを呼び出さずに_fwrite_nolockの動作をテストします:7262221 ms、速度は70.5 Mb / sです!
次に、バッファーのサイズ(setvbuf)を試してください。
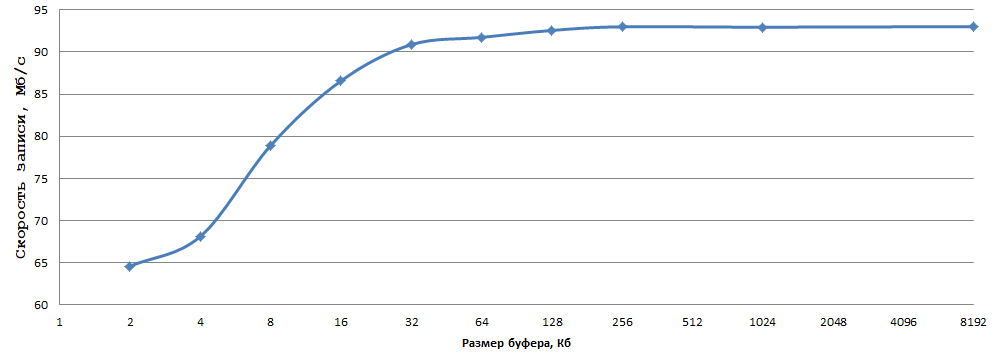
データは5回の実験を平均して得られたもので、エラーを考慮するには遅すぎました。 私に関しては、1バイトを通常のHDDに書き込むときの93 Mb / sは非常に良い結果です、最適なバッファサイズ(私の場合は256 KB-ちょうどいい)を選択し、fwriteを_fwrite_nolock / fwrite_unlocked(inもちろん、スレッドセーフが必要ない場合)。
同様に、同様の条件での恐怖。 Linuxの状況を見てみましょう。テスト構成は次のとおりです。AMDRyzen 7 1700X、16 GB RAM、HDD 3.5 "7200 rpm 64 MBキャッシュ、OS OpenSUSE 15、GCC 8.3.1、x86-64 binar、ファイルシステムをテストしますext4テストセクションでは、このテストでバッファーサイズを明示的に設定しない場合のfwriteの結果は67.6 Mb / sです。バッファーを256 Kbに設定すると、速度は69.7 Mb / sに増加しました。バッファーサイズを1 KBから8 MBに変更すると、次の結論に至りました。バッファーを増やすと書き込み速度が向上し、 しかし、私の場合の違いは3 Mb / sだけであり、64 Kbと8 Mbのバッファーの速度にまったく違いはありませんでした。このLinuxマシンで受信したデータから、次の結論を導き出すことができます。
- fwrite_unlockedはfwriteより高速ですが、書き込み速度の違いはWindowsほど大きくありません
- Linuxのバッファサイズは、Windowsの場合のようにfwrite / fwrite_unlockedによる書き込み速度に大きな影響を与えません。
全体として、提案された方法は、WindowsとLinuxの両方で効果的です(程度は低いですが)。
あとがき
この記事の目的は、多くの場合にシンプルで効果的な手法を説明することでした(以前に_fwrite_nolock / fwrite_unlocked関数に出会ったことはありません。あまり一般的ではありませんが、無駄です)。 私はこの資料に新しいふりをするつもりはありませんが、この記事がコミュニティに役立つことを願っています。