しかし、この称賛に値する欲求はしばしば問題に突き当たります。 合理的なフレームワークで誤検知の数を維持しようとすると、真の陽性の数は印象的ではありません。 その結果、多くの場合、分析の結果では適切な経営判断を下すことができません。 適切な予測を行うには、チャネル上のユーザータッチの短いチェーンよりも多くのデータが必要です。 しかし、これはタスクが終了することを意味するものではありません。

この記事では、コンバージョン予測アルゴリズムを開発するための一連の実験について少し説明します。 この記事は、同様のトピックに関する前の2つの続きです。 ここが最初です 、 ここが2番目です。
問題の声明
予測のコンテキストで機械学習を扱った人は誰でも、 LSTM ( RNN Neural Networks)に精通しています。 しかし、私たちの「予測」はさらに簡単なタスクに帰着します。 変換の予測とは、チェーンを「将来の変換」のクラスに属するものとして分類することを意味します。LSTMには、 時系列の意味と単語の文字を予測するシステムの作成に関する膨大な量の優れた資料があります 。 私たちの場合、タスクは一見するとさらにシンプルでした。
- チャネルの相互作用を分析することにより、アルファベットのように見えるものを作成できます。文字は別々のチャネルです。 例-「(channel)1」、「(channel)2」、...
- 文字から、チェーンの形で膨大な数の「単語」を取得します。これは、ユーザーとチャンネル間の相互作用のあらゆる種類の組み合わせです。 たとえば、chain = "1"、 "2"、 "1"、 "3"; chain = "2"、 "4"、 "4"、 "1"; ...

図1 粗いデータを処理して、短すぎるチェーンと長すぎるチェーンを削除します。
私たちの目標は、選択した長さのチェーンの顧客ベース全体でコンバージョンの可能性を最大化するタッチの組み合わせを識別することです。 これを行うには、サンプル全体から必要な長さの単語(チェーン)を選択します。 チェーンが指定されたチェーンよりも長い場合、目的の長さの複数のチェーンに分割されます。 たとえば-(1,2,3,4)->(1,2,3)、(2,3,4)。 処理プロセスを図1に示します。
簡単な解決策を見つける最初の試み。
この試みでは、同じ長さの「ほぼ生の」チェーンでLSTMネットワークをトレーニングし、約0.5のRUC AUC値を取得しました。 おっと うまくいきませんでした。 しかし、それを鈍くしようとすることは価値がありましたか? 突然乗る。 しかし、ありません。 少し考えなければなりませんでした。何が起こっているかの分析
重要な観察1この研究の同質なチェーンは価値がありません。 それらの変換はチェーンの長さとチャネル番号のみに依存し、 それらの分類器は2つの要因によるロジスティック多重回帰によって構築されます。 カテゴリ係数はチャネル番号であり、数値係数はチェーンの長さです。 いずれにせよ十分な長さのチェーンが変換を疑っているので、それは役に立たないが、かなり透明になります。 したがって、それらはまったく考慮できません。 ここでは、通常、すべてのチェーンの約80%が均一であるため、サンプルサイズが大幅に削減されることに注意する必要があります。
重要な観察2
すべての(基本的に)非アクティブなチャネルを破棄して、データ量を制限できます。
重要な観察3
どのチェーンにも、 ワンホットコーディングを適用できます。 これにより、チャネルを数値シーケンスとしてマークする場合に発生する可能性のある問題がなくなります。 たとえば、数値がチャネル番号の場合、式3-1 = 2は意味がありません(図2)。
とりわけ、チェーンの性質に関するさまざまな仮定に基づいた、より奇妙な方法でチェーンをエンコードしようとしました。 しかし、これは何の助けにもならなかったので、それについてはお話ししません。

図2。 2番目のデータ変換。 同種のチェーンをすべて削除し、ワンホットコーディングを適用します。
簡単な解決策の2回目の試み
さまざまなチェーンエンコーディングオプションに対して、次の分類ツールが試行されました。- Lstm
- 複数のLSTM
- 多層パーセプトロン(2、3、4、レイヤー)
- ランダムフォレスト
- 勾配ブースティング分類器 (GBC)
- SVM
- Deep Convolutional Network ( 念のために 2層で)
すべてのモデルのパラメーターは、 Basin-hoppingアルゴリズムを使用して最適化されました。 結果は楽観的ではありませんでした。 AUC ROCは0.6に上昇しましたが、私たちの場合、これは明らかに十分ではありませんでした。
3番目の試み:簡単な解決策。
自然に発生するすべてのことが、チェーンの長さが同じであれば、最も重要なのはチェーンのチャネルの構成とチャネルの実際の構成の多様性であるという考えにつながりました。 一般に順序は依然として重要であると考えられているため、これは一般的な考えではありません。 しかし、LSTMを使用した以前の実験では、たとえそうだとしても、あまり役に立たないことが示されています。 したがって、可能な限りチェーンの構成に集中する必要があります。たとえば、チェーンからすべての重複を削除し、結果のリストを並べ替えることができます。 これは、次の単純なpythonコードのようなもので実行できます。
後でパターン辞書のキーとしてこのチェーンを使用するには、タプルへの変換が必要です。 その後、発生したチェーンの数と数をカウントできます。 図3のようになります。sorted_chain = tuple(sorted(list(set(chain))))
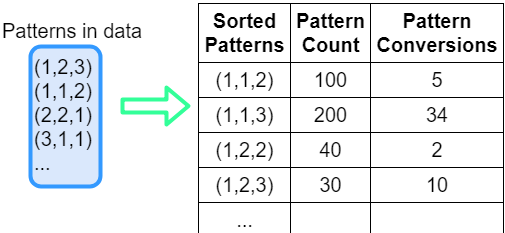
図3 チェーンテンプレートの並べ替えとカウント
最初のパスでは、データ内の各「テンプレート」チェーンの平均コンバージョン率を計算できます。
次に、結果のリストを変換の降順でソートし、「変換カットオフ」パラメーターを持つ分類子を取得します。 上記の方法で変換されたテストチェーンを、指定されたものよりも大きな変換を持つリストのパターンの1つが存在するかどうかをチェックすることで、変換を生成するものまたは役に立たないものとして分類します。 これで、この変換レベル分類子を使用してすべての着信チェーンをテストし、結果を予測できます。 何が起こったかに基づいて、この記事でこのアプローチの利点を示す唯一のグラフを作成しました。 このアプローチのROC曲線。ここでは、パターンチェックと呼ばれます。
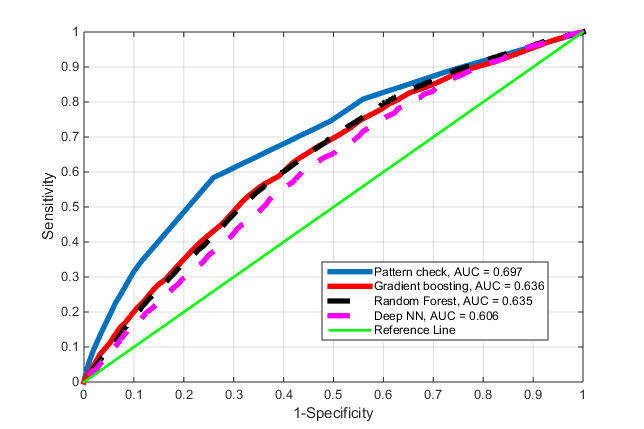
図4 さまざまな分類子のROC曲線。
新しいメソッドでは、AUC = 0.7です。 これはすでに何かです。 直接的な勝利ではなく、コインを投げることにはほど遠い。 発言。 明確にするためにここで説明するように、このメソッドはワンホットを使用せずに実装できますが、成功を収めたい場合は、すでに必要な場合があります。
結論
「パターン」という言葉では、機械学習に精通している人々はすぐに「畳み込みニューラルネットワーク」と考えます。 これはそうですが、私たちは今それについて書きません。 チェーンの変換方法と思われる良い方法をここにもたらしました。これにより、額に最先端のテクノロジーを使用するよりも優れた分類器(予測子)をすぐに取得できます。 すでに何千もの誤検知を恐れずに、コンバージョンの可能性が高いユーザーのグループを強調するために使用できます。 データの場合、0.25変換アルゴリズムでカットオフを選択すると、テストサンプルが6万7千人である場合、テストサンプルの変換が5112、真陽性が523、偽陽性が1123になりました。
PS Maxilectの会社のニュースに遅れずについて行き、すべての出版物について最初に知るには、 VK 、 FBまたはTelegram-channelのページを購読してください。