
現在、 Apache Sparkは、大量のデータを分析するための最も人気のあるプラットフォームです。 その人気に大きく貢献しているのは、Pythonで使用できることです。 同時に、標準APIのフレームワーク内では、PythonとScala / Javaコードのパフォーマンスは同等ですが、ユーザー定義関数(ユーザー定義関数、UDF)に関する単一の視点は存在しないことに全員が同意します。 SNA Hackathon 2019ソリューションを確認するタスクの例を使用して、この場合のオーバーヘッドがどのように増加するかを把握してみましょう。
競争の一環として、参加者はソーシャルネットワークのニュースフィードをソートする問題を解決し、ソートされたリストの形式でソリューションをアップロードします。 得られたソリューションの品質を確認するには、まず、ロードされたリストごとにROC AUCが計算され、次に平均値が表示されます。 1つの一般的なROC AUCではなく、ユーザーごとに個人的なROC AUCを計算する必要があることに注意してください。 実際に2つのアプローチを比較する正当な理由。
比較プラットフォームとして、4つのコアを備えたクラウドコンテナーを使用し、Sparkをローカルモードで起動し、 Apache Zeppelinを使用して作業します。 機能を比較するために、PySparkとScala Sparkで同じコードをミラーリングします。 [ここ]データの読み込みから始めましょう。
data = sqlContext.read.csv("sna2019/modelCappedSubmit") trueData = sqlContext.read.csv("sna2019/collabGt") toValidate = data.withColumnRenamed("_c1", "submit") \ .join(trueData.withColumnRenamed("_c1", "real"), "_c0") \ .withColumnRenamed("_c0", "user") \ .repartition(4).cache() toValidate.count()
val data = sqlContext.read.csv("sna2019/modelCappedSubmit") val trueData = sqlContext.read.csv("sna2019/collabGt") val toValidate = data.withColumnRenamed("_c1", "submit") .join(trueData.withColumnRenamed("_c1", "real"), "_c0") .withColumnRenamed("_c0", "user") .repartition(4).cache() toValidate.count()
標準APIを使用する場合、 val
キーワードまで、コードのほぼ完全なIDが注目に値します。 稼働時間に大きな違いはありません。 次に、必要なUDFを決定してみましょう。
parse = sqlContext.udf.register("parse", lambda x: [int(s.strip()) for s in x[1:-1].split(",")], ArrayType(IntegerType())) def auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores)) auc_udf = sqlContext.udf.register("auc", auc, DoubleType())
val parse = sqlContext.udf.register("parse", (x : String) => x.slice(1,x.size - 1).split(",").map(_.trim.toInt)) case class AucAccumulator(height: Int, area: Int, negatives: Int) val auc_udf = sqlContext.udf.register("auc", (byScore: Seq[Int], gt: Seq[Int]) => { val byLabel = gt.toSet val accumulator = byScore.foldLeft(AucAccumulator(0, 0, 0))((accumulated, current) => { if (byLabel.contains(current)) { accumulated.copy(height = accumulated.height + 1) } else { accumulated.copy(area = accumulated.area + accumulated.height, negatives = accumulated.negatives + 1) } }) (accumulator.area).toDouble / (accumulator.negatives * accumulator.height) })
特定の関数を実装する場合、主に組み込みのscikit-learn関数を使用できるため、Pythonがより簡潔であることは明らかです。 ただし、不快な瞬間があります-Scalaでは自動的に決定されるのに対して、戻り値の型を明示的に指定する必要があります。 操作を実行しましょう:
toValidate.select(auc_udf(parse("submit"), parse("real"))).groupBy().avg().show()
toValidate.select(auc_udf(parse($"submit"), parse($"real"))).groupBy().avg().show()
コードはほとんど同じように見えますが、結果は落胆しています。

PySparkでの実装は、Scalaでの2秒ではなく1分半で完了しました。つまり、 Pythonは45倍遅くなりました 。 実行中、topはフルキャパシティで実行されている4つのアクティブなPythonプロセスを示しています。これは、 グローバルインタープリターロックがここで問題を引き起こさないことを示しています。 しかし! おそらく問題は内部のscikit-learnの実装にあるのでしょう-標準ライブラリに頼らずに文字通りPythonコードを再現してみましょう。
def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) auc_udf_modified = sqlContext.udf.register("auc_modified", auc, DoubleType()) toValidate.select(auc_udf_modified(parse("submit"), parse("real"))).groupBy().avg().show()

この実験は興味深い結果を示しています。 一方では、このアプローチでは生産性は平準化されましたが、他方では、簡潔さはなくなりました。 得られた結果は、追加のC ++モジュールを使用してPythonで作業する場合、コンテキストの切り替えに大きなオーバーヘッドが現れることを示している可能性があります。 もちろん、Java / ScalaでJNIを使用する場合も同様のオーバーヘッドがありますが、それらを使用するときに45回の劣化の例に対処する必要はありませんでした。
より詳細な分析のために、2つの追加実験を実行します。Sparkなしの純粋なPythonを使用してパッケージ呼び出しからの寄与を測定し、Sparkのデータサイズを増やしてオーバーヘッドを償却し、より正確な比較を取得します。
def parse(x): return [int(s.strip()) for s in x[1:-1].split(",")] def auc(submit, real): trueSet = set(real) height = 0 area = 0 negatives = 0 for candidate in submit: if candidate in trueSet: height = height + 1 else: area = area + height negatives = negatives + 1 return float(area) / (negatives * height) def sklearn_auc(submit, real): trueSet = set(real) scores = [1.0 / (i + 1) for i,x in enumerate(submit)] labels = [1.0 if x in trueSet else 0.0 for x in submit] return float(roc_auc_score(labels, scores))
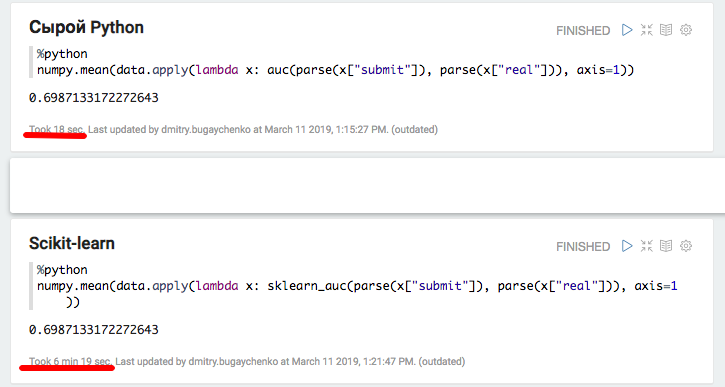
ローカルPythonおよびPandasを使用した実験により、追加パッケージを使用する場合の大きなオーバーヘッドの仮定が確認されました-scikit-learnを使用する場合、速度は20倍以上低下します。 ただし、20は45ではありません。データを「膨張」させて、Sparkのパフォーマンスを再度比較してみましょう。
k4 = toValidate.union(toValidate) k8 = k4.union(k4) m1 = k8.union(k8) m2 = m1.union(m1) m4 = m2.union(m2).repartition(4).cache() m4.count()

新しい比較は、Pythonに対するScala実装の速度の優位性を7〜8倍(7秒に対して7秒)示しています。最後に、配列の合計を計算するnumpyを試してみましょう。
import numpy numpy_sum = sqlContext.udf.register("numpy_sum", lambda x: float(numpy.sum(x)), DoubleType())
val my_sum = sqlContext.udf.register("my_sum", (x: Seq[Int]) => x.map(_.toDouble).sum)
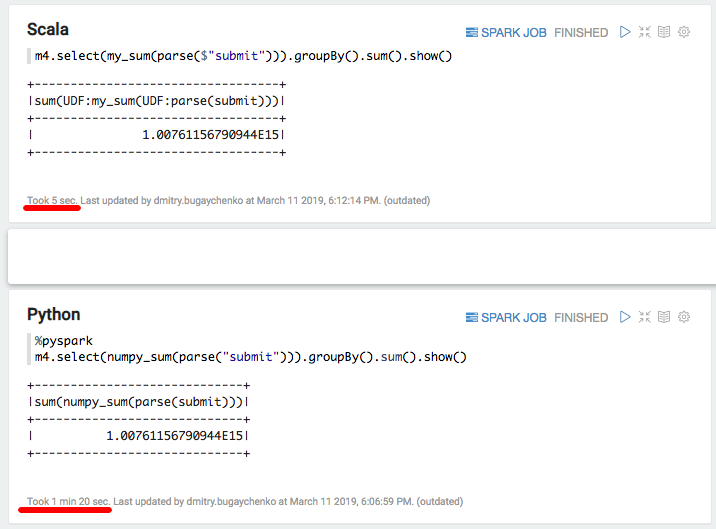
再び大幅な減速-5秒のScala対80秒のPython。 まとめると、次の結論を導き出すことができます。
- PySparkは標準APIのフレームワーク内で動作しますが、速度の点では実際にScalaと比較できます。
- 特定のロジックがユーザー定義関数の形式で表示されると、PySparkのパフォーマンスが著しく低下します。 十分な情報があれば、データブロックの処理時間が数秒を超えると、プロセス間でデータを移動し、Pythonの解釈にリソースを浪費する必要があるため、Pythonの実装は5〜10遅くなります。
- C ++モジュールで実装された追加の関数の使用が表示される場合、追加の呼び出しコストが発生し、PythonとScalaの差は最大10〜50倍に増加します。
その結果、Pythonのすべての魅力にもかかわらず、Sparkと組み合わせたPythonの使用は必ずしも正当化されるとは限りません。 Pythonのオーバーヘッドを大きくするデータがあまりない場合、ここでSparkが必要かどうかを検討する必要がありますか? 大量のデータがあるが、標準のSpark SQL APIのフレームワーク内で処理が発生する場合、ここでPythonが必要ですか?
大量のデータがあり、多くの場合、SQL APIの制限を超えるタスクを処理する必要がある場合、PySparkを使用して同じ量の作業を実行するには、クラスターを数倍増やす必要があります。 たとえば、Odnoklassnikiの場合、Sparkクラスターの資本支出のコストは数億ルーブル増加します。 また、Pythonエコシステムライブラリの高度な機能を利用しようとすると、スローダウンのリスクは時々起こるだけでなく、桁違いに大きくなります。
ベクトル化された関数の比較的新しい機能を使用すると、ある程度の加速が得られます。 この場合、単一の行がUDF入力に送られるのではなく、Pandas Dataframeの形式のいくつかの行のパケットが送られます。 ただし、この機能の開発はまだ完了しておらず 、この場合でも違いは顕著です。
別の方法として、データエンジニアの大規模なチームを維持し、追加の機能を使用してデータサイエンティストのニーズに迅速に対応することができます。 または、Scalaの世界に没頭するには、それほど難しくないため、必要なツールの多くが既に存在するため 、PySparkを超えるトレーニングプログラムが登場します。