
こんにちは、おかえりなさい! これは、ベアメタルでのKubernetesクラスターのセットアップに関する記事の第2部です。 以前は、外部etcd、マスター/マスタースキーム、および負荷分散を使用してKubernetes HAクラスターを構成しました。 さて、今度は追加の環境とユーティリティを構成して、クラスターをより便利にし、可能な限り稼働状態に近づけます。
記事のこの部分では、クラスターサービスの内部ロードバランサーの構成に焦点を当てます-これはMetalLBです。 また、作業ノード間に分散ファイルストレージをインストールして構成します。 Kubernetesで利用可能な永続ボリュームにはGlusterFSを使用します。
すべての手順を完了すると、クラスター図は次のようになります。
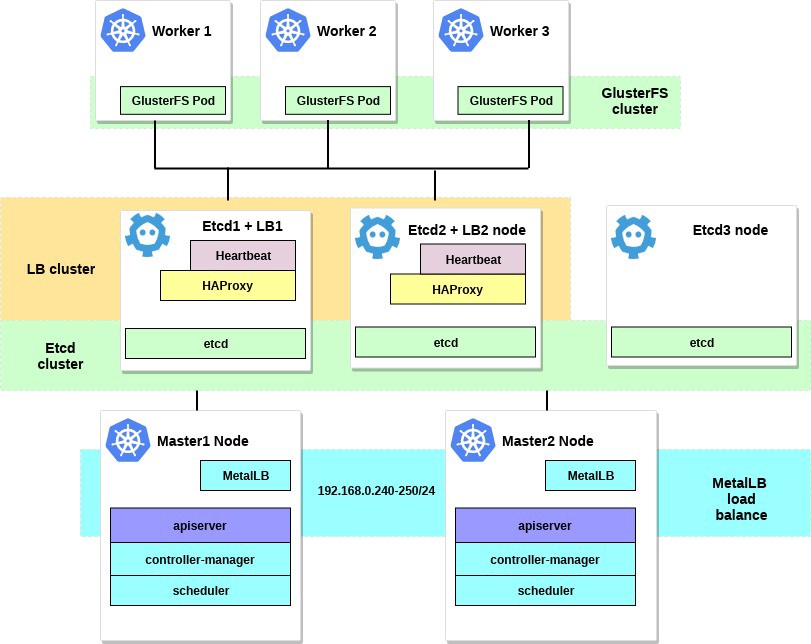
1. MetalLBを内部ロードバランサーとして設定します。
ドキュメントページから直接MetalLBについてのいくつかの言葉:
MetalLBは、標準ルーティングプロトコルを使用したKubernetesベアメタルクラスター用のロードバランサー実装です。
Kubernetesは、ベアメタル用のネットワークロードバランサー( LoadBalancerなどのサービス )の実装を提供していません。 Kubernetesに付属するすべてのNetwork LB実装オプションはミドルウェアであり、さまざまなIaaSプラットフォーム(GCP、AWS、Azureなど)にアクセスします。 IaaSがサポートするプラットフォーム(GCP、AWS、Azureなど)で作業していない場合、LoadBalancerは作成時に無期限に「スタンバイ」状態のままになります。
BMサーバーオペレーターには、クラスターにユーザートラフィックを入力するための、NodePortサービスとexternalIPsサービスという2つの効果の低いツールがあります。 これらのオプションにはどちらも生産上の重大な欠陥があり、これによりBMクラスターはKubernetesエコシステムの二流市民になります。
MetalLBは、BMクラスターの外部サービスも最大速度で「機能する」ように、標準ネットワーク機器と統合するNetwork LB実装を提供することにより、この不均衡を修正しようとしています。
したがって、このツールを使用して、ロードバランサーを使用してKubernetesクラスターでサービスを起動します。これはMetalLBチームのおかげです。 設定プロセスは本当にシンプルで簡単です。
前の例では、クラスターのニーズに合わせて192.168.0.0/24サブネットを選択しました。 次に、将来のロードバランサー用にこのサブネットの一部を取得します。
設定済みのkubectlユーティリティを使用してマシンシステムに入り、次を実行します。
control# kubectl apply -f https://raw.githubusercontent.com/google/metallb/v0.7.3/manifests/metallb.yaml
これにより、 metallb-system
クラスターにMetalLBがデプロイされmetallb-system
。 すべてのMetalLBコンポーネントが適切に機能していることを確認します。
control# kubectl get pod --namespace=metallb-system NAME READY STATUS RESTARTS AGE controller-7cc9c87cfb-ctg7p 1/1 Running 0 5d3h speaker-82qb5 1/1 Running 0 5d3h speaker-h5jw7 1/1 Running 0 5d3h speaker-r2fcg 1/1 Running 0 5d3h
次に、configmapを使用してMetalLBを構成します。 この例では、レイヤー2のカスタマイズを使用していますが、その他のカスタマイズオプションについては、MetalLBのドキュメントを参照してください。
クラスターのサブネットの選択したIP範囲内の任意のディレクトリにmetallb-config.yamlファイルを作成します。
control# vi metallb-config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb-system name: config data: config: | address-pools: - name: default protocol: layer2 addresses: - 192.168.0.240-192.168.0.250
そして、この設定を適用します:
control# kubectl apply -f metallb-config.yaml
必要に応じて、後でconfigmapを確認して変更します。
control# kubectl describe configmaps -n metallb-system control# kubectl edit configmap config -n metallb-system
これで、独自のローカルロードバランサーが構成されました。 例としてNginxサービスを使用して、その仕組みを見てみましょう。
control# vi nginx-deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: selector: matchLabels: app: nginx replicas: 3 template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:latest ports: - containerPort: 80 control# vi nginx-service.yaml apiVersion: v1 kind: Service metadata: name: nginx spec: type: LoadBalancer selector: app: nginx ports: - port: 80 name: http
次に、テストデプロイとNginxサービスを作成します。
control# kubectl apply -f nginx-deployment.yaml control# kubectl apply -f nginx-service.yaml
そして今-結果を確認してください:
control# kubectl get po NAME READY STATUS RESTARTS AGE nginx-deployment-6574bd76c-fxgxr 1/1 Running 0 19s nginx-deployment-6574bd76c-rp857 1/1 Running 0 19s nginx-deployment-6574bd76c-wgt9n 1/1 Running 0 19s control# kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE nginx LoadBalancer 10.100.226.110 192.168.0.240 80:31604/TCP 107s
以前の展開で示したように、3つのNginxポッドを作成しました。 Nginxサービスは、サイクリックバランシングスキームに従って、これらすべてのポッドにトラフィックを誘導します。 また、MetalLBロードバランサーから受信した外部IPも確認できます。
IPアドレス192.168.0.240に折りたたむと、Nginx index.htmlページが表示されます。 テスト展開とNginxサービスを忘れずに削除してください。
control# kubectl delete svc nginx service "nginx" deleted control# kubectl delete deployment nginx-deployment deployment.extensions "nginx-deployment" deleted
さて、それはMetalLBですべてです。先に進みましょう-Kubernetesボリューム用にGlusterFSを構成します。
2.稼働中のノードでHeketiを使用してGlusterFSを構成します。
実際、Kubernetesクラスターは、内部にボリュームがないと使用できません。 ご存知のように、囲炉裏ははかないものです。 いつでも作成および削除できます。 それらの中のすべてのデータは失われます。 したがって、実際のクラスターでは、ノードとその内部のアプリケーション間で設定とデータの交換を保証するために、分散ストレージが必要です。
Kubernetesでは、ボリュームはさまざまな方法で使用できますので、必要なボリュームを選択してください。 この例では、永続アプリケーションのような内部アプリケーション用のGlusterFSストレージを作成する方法を示します。 以前、このためにすべてのKubernetes作業ノードにGlusterFSの「システム」インストールを使用し、次にGlusterFSディレクトリにhostPathなどのボリュームを作成しました。
これで、新しい便利なヘケティツールができました 。
ヘケティのドキュメントからの一言:
GlusterFS用のRESTfulボリューム管理インフラストラクチャ。
Heketiは、GlusterFSボリュームのライフサイクルを管理するために使用できるRESTful管理インターフェイスを提供します。 Heketiのおかげで、OpenStack Manila、Kubernetes、OpenShiftなどのクラウドサービスは、GlusterFSボリュームにあらゆるタイプの信頼性を動的に提供できます。 Heketiは、クラスター内のブロックの場所を自動的に決定し、さまざまな障害領域でのブロックとそのレプリカの場所を提供します。 Heketiは任意の数のGlusterFSクラスターもサポートしているため、クラウドサービスは単一のGlusterFSクラスターだけでなく、オンラインファイルストレージを提供できます。
それは良さそうですが、さらに、このツールはVMクラスターをKubernetesの大規模なクラウドクラスターに近づけます。 最後に、自動的に生成されるPersistentVolumeClaimsなどを作成できます。
追加のシステムハードドライブを使用してGlusterFSを構成したり、ダミーブロックデバイスを作成したりできます。 この例では、2番目の方法を使用します。
3つの作業ノードすべてにダミーブロックデバイスを作成します。
worker1-3# dd if=/dev/zero of=/home/gluster/image bs=1M count=10000
サイズが約10 GBのファイルを取得します。 次に、 losetupを使用して、ループバックデバイスとしてこれらのノードに追加します。
worker1-3# losetup /dev/loop0 /home/gluster/image
注:ループバックデバイス0がある場合は、他の番号を選択する必要があります。
時間をかけて、ヘケティが適切に機能したくない理由を見つけました。 したがって、将来の構成で問題が発生しないように、まずdm_thin_poolカーネルモジュールをロードし、すべての作業ノードにglusterfs-clientパッケージをインストールしたことを確認してください。
worker1-3# modprobe dm_thin_pool worker1-3# apt-get update && apt-get -y install glusterfs-client
さて、すべての作業ノードにファイル/ home / gluster / imageとdevice / dev / loop0が存在する必要があります。 これらのサーバーが起動するたびにlosetupとmodprobeを自動的に開始するsystemdサービスを作成することを忘れないでください。
worker1-3# vi /etc/systemd/system/loop_gluster.service [Unit] Description=Create the loopback device for GlusterFS DefaultDependencies=false Before=local-fs.target After=systemd-udev-settle.service Requires=systemd-udev-settle.service [Service] Type=oneshot ExecStart=/bin/bash -c "modprobe dm_thin_pool && [ -b /dev/loop0 ] || losetup /dev/loop0 /home/gluster/image" [Install] WantedBy=local-fs.target
オンにします:
worker1-3# systemctl enable /etc/systemd/system/loop_gluster.service Created symlink /etc/systemd/system/local-fs.target.wants/loop_gluster.service → /etc/systemd/system/loop_gluster.service.
準備作業が完了し、GlusterFSとHeketiをクラスターに展開する準備が整いました。 このために、このクールなガイドを使用します 。 ほとんどのコマンドは外部制御コンピューターから起動され、非常に小さなコマンドはクラスター内のマスターノードから起動されます。
まず、リポジトリをコピーし、DaemonSet GlusterFSを作成します。
control# git clone https://github.com/heketi/heketi control# cd heketi/extras/kubernetes control# kubectl create -f glusterfs-daemonset.json
それでは、GlusterFSの3つの作業ノードをマークしましょう。 それらにラベルを付けると、GlusterFSポッドが作成されます:
control# kubectl label node worker1 storagenode=glusterfs control# kubectl label node worker2 storagenode=glusterfs control# kubectl label node worker3 storagenode=glusterfs control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 1m6s glusterfs-hzdll 1/1 Running 0 1m9s glusterfs-p8r59 1/1 Running 0 2m1s
次に、Heketiサービスアカウントを作成します。
control# kubectl create -f heketi-service-account.json
このサービスアカウントには、Glusterポッドを管理する機能が用意されています。 これを行うには、新しく作成したサービスアカウントに必要なクラスター関数を作成します。
control# kubectl create clusterrolebinding heketi-gluster-admin --clusterrole=edit --serviceaccount=default:heketi-service-account
次に、Heketiインスタンスの構成をブロックするKubernetes秘密鍵を作成しましょう。
control# kubectl create secret generic heketi-config-secret --from-file=./heketi.json
最初のセットアップ操作に使用するHeketiの下に最初のソースを作成し、その後削除します。
control# kubectl create -f heketi-bootstrap.json service "deploy-heketi" created deployment "deploy-heketi" created control# kubectl get pod NAME READY STATUS RESTARTS AGE deploy-heketi-1211581626-2jotm 1/1 Running 0 2m glusterfs-5dtdj 1/1 Running 0 6m6s glusterfs-hzdll 1/1 Running 0 6m9s glusterfs-p8r59 1/1 Running 0 7m1s
Bootstrap Heketiサービスを作成して開始した後、マスターノードの1つに切り替える必要があります。外部コントロールノードはクラスター内にないため、いくつかのコマンドを実行します。したがって、作業ポッドとクラスターの内部ネットワークにアクセスできません。
まず、heketi-clientユーティリティをダウンロードして、binシステムフォルダーにコピーします。
master1# wget https://github.com/heketi/heketi/releases/download/v8.0.0/heketi-client-v8.0.0.linux.amd64.tar.gz master1# tar -xzvf ./heketi-client-v8.0.0.linux.amd64.tar.gz master1# cp ./heketi-client/bin/heketi-cli /usr/local/bin/ master1# heketi-cli heketi-cli v8.0.0
次に、ヘケティポッドのIPアドレスを見つけて、システム変数としてエクスポートします。
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf describe pod deploy-heketi-1211581626-2jotm For me this pod have a 10.42.0.1 ip master1# curl http://10.42.0.1:57598/hello Handling connection for 57598 Hello from Heketi master1# export HEKETI_CLI_SERVER=http://10.42.0.1:57598
次に、Heketiに管理するGlusterFSクラスターに関する情報を提供しましょう。 トポロジファイルを通じて提供します。 トポロジは、GlusterFSが使用するすべてのノード、ディスク、クラスターのリストを持つJSONマニフェストです。
注kubectl get node
セクションのように、hostnames/manage
が正確な名前を指していること、およびhostnames/storage
がストレージノードのIPアドレスであることを確認してください。
master1:~/heketi-client# vi topology.json { "clusters": [ { "nodes": [ { "node": { "hostnames": { "manage": [ "worker1" ], "storage": [ "192.168.0.7" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker2" ], "storage": [ "192.168.0.8" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] }, { "node": { "hostnames": { "manage": [ "worker3" ], "storage": [ "192.168.0.9" ] }, "zone": 1 }, "devices": [ "/dev/loop0" ] } ] } ] }
次に、このファイルをダウンロードします。
master1:~/heketi-client# heketi-cli topology load --json=topology.json Creating cluster ... ID: e83467d0074414e3f59d3350a93901ef Allowing file volumes on cluster. Allowing block volumes on cluster. Creating node worker1 ... ID: eea131d392b579a688a1c7e5a85e139c Adding device /dev/loop0 ... OK Creating node worker2 ... ID: 300ad5ff2e9476c3ba4ff69260afb234 Adding device /dev/loop0 ... OK Creating node worker3 ... ID: 94ca798385c1099c531c8ba3fcc9f061 Adding device /dev/loop0 ... OK
次に、Heketiを使用して、データベースを保存するためのボリュームを提供します。 チームの名前は少し奇妙ですが、すべてが順調です。 また、heketiリポジトリを作成します。
master1:~/heketi-client# heketi-cli setup-openshift-heketi-storage master1:~/heketi-client# kubectl --kubeconfig /etc/kubernetes/admin.conf create -f heketi-storage.json secret/heketi-storage-secret created endpoints/heketi-storage-endpoints created service/heketi-storage-endpoints created job.batch/heketi-storage-copy-job created
これらはすべて、マスターノードから実行する必要があるコマンドです。 制御ノードに戻り、そこから続行しましょう。 まず、最後に実行したコマンドが正常に実行されたことを確認します。
control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-storage-copy-job-txkql 0/1 Completed 0 69s
そして、heketi-storage-copy-jobジョブが完了しました。
現在、作業ノードにglusterfs-clientパッケージがインストールされていない場合、エラーが発生します。
Heketi Bootstrapのインストールファイルを削除して、少しクリーンアップを行います。
control# kubectl delete all,service,jobs,deployment,secret --selector="deploy-heketi"
最後の段階で、ヘケティの長期コピーを作成する必要があります。
control# cd ./heketi/extras/kubernetes control:~/heketi/extras/kubernetes# kubectl create -f heketi-deployment.json secret/heketi-db-backup created service/heketi created deployment.extensions/heketi created control# kubectl get pod NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 39h glusterfs-hzdll 1/1 Running 0 39h glusterfs-p8r59 1/1 Running 0 39h heketi-b8c5f6554-knp7t 1/1 Running 0 22m
現在、作業ノードにglusterfs-clientパッケージがインストールされていない場合、エラーが発生します。 そして、ほぼ完了しました。現在、HeketiデータベースはGlusterFSボリュームに保存されており、Heketiの炉床が再起動されるたびにリセットされることはありません。
動的リソース割り当てでGlusterFSクラスターの使用を開始するには、StorageClassを作成する必要があります。
まず、Glusterストレージエンドポイントを見つけましょう。これは、パラメーター(heketi-storage-endpoints)としてStorageClassに渡されます。
control# kubectl get endpoints NAME ENDPOINTS AGE heketi 10.42.0.2:8080 2d16h ....... ... ..
次に、いくつかのファイルを作成します。
control# vi storage-class.yml apiVersion: storage.k8s.io/v1beta1 kind: StorageClass metadata: name: slow provisioner: kubernetes.io/glusterfs parameters: resturl: "http://10.42.0.2:8080" control# vi test-pvc.yml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: gluster1 annotations: volume.beta.kubernetes.io/storage-class: "slow" spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi
これらのファイルを使用して、クラスとpvcを作成します。
control# kubectl create -f storage-class.yaml storageclass "slow" created control# kubectl get storageclass NAME PROVISIONER AGE slow kubernetes.io/glusterfs 2d8h control# kubectl create -f test-pvc.yaml persistentvolumeclaim "gluster1" created control# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE gluster1 Bound pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO slow 2d8h
PVボリュームも表示できます。
control# kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-27f733cd-1c77-11e9-bb07-7efe6b0e6fa5 1Gi RWO Delete Bound default/gluster1 slow 2d8h
PersistentVolumeClaimに関連付けられたGlusterFSボリュームが動的に作成されました。このステートメントを任意のサブプロットで使用できます。
Nginxの下に単純なものを作成してテストします。
control# vi nginx-test.yml apiVersion: v1 kind: Pod metadata: name: nginx-pod1 labels: name: nginx-pod1 spec: containers: - name: nginx-pod1 image: gcr.io/google_containers/nginx-slim:0.8 ports: - name: web containerPort: 80 volumeMounts: - name: gluster-vol1 mountPath: /usr/share/nginx/html volumes: - name: gluster-vol1 persistentVolumeClaim: claimName: gluster1 control# kubectl create -f nginx-test.yaml pod "nginx-pod1" created
下を参照します(数分待ってください。まだ存在しない場合は、ダウンロードする必要があります)。
control# kubectl get pods NAME READY STATUS RESTARTS AGE glusterfs-5dtdj 1/1 Running 0 4d10h glusterfs-hzdll 1/1 Running 0 4d10h glusterfs-p8r59 1/1 Running 0 4d10h heketi-b8c5f6554-knp7t 1/1 Running 0 2d18h nginx-pod1 1/1 Running 0 47h
コンテナに移動して、index.htmlファイルを作成します。
control# kubectl exec -ti nginx-pod1 /bin/sh # cd /usr/share/nginx/html # echo 'Hello there from GlusterFS pod !!!' > index.html # ls index.html # exit
囲炉裏の内部IPアドレスを見つけて、マスターノードからそこにカールする必要があります。
master1# curl 10.40.0.1 Hello there from GlusterFS pod !!!
その際、新しい永続ボリュームをテストするだけです。
新しいGlusterFSクラスターをチェックアウトするための便利なコマンドは、heketi-cli cluster list
およびheketi-cli volume list
です。 heketi-cliがインストールされていれば、コンピューターで実行できます。 この例では、これはmaster1ノードです。
master1# heketi-cli cluster list Clusters: Id:e83467d0074414e3f59d3350a93901ef [file][block] master1# heketi-cli volume list Id:6fdb7fef361c82154a94736c8f9aa53e Cluster:e83467d0074414e3f59d3350a93901ef Name:vol_6fdb7fef361c82154a94736c8f9aa53e Id:c6b69bd991b960f314f679afa4ad9644 Cluster:e83467d0074414e3f59d3350a93901ef Name:heketidbstorage
この時点で、ファイルストレージを備えた内部ロードバランサーのセットアップに成功し、クラスターは運用状態に近づいています。
記事の次の部分では、クラスター監視システムの作成に焦点を当て、構成したすべてのリソースを使用するためのテストプロジェクトを起動します。
連絡を取り合って、最高の状態にしましょう!