Linuxカーネルは、パフォーマンスに影響を与える可能性のある幅広い構成オプションを提供します。 主なことは、アプリケーションとワークロードに適した構成を選択することです。 他のデータベースと同様に、PostgreSQLにはLinuxカーネルの最適なチューニングが必要です。 設定が正しくないと、パフォーマンスが低下する可能性があります。 各チューニングセッションの後に、データベースパフォーマンスの比較分析を実施することが重要です。 「PostgreSQL最適化のためのLinuxカーネルパラメーターのチューニング」というタイトルの以前の投稿の1つで、最も有用なLinuxカーネルパラメーターのいくつかと、それらがデータベースのパフォーマンスを向上させる方法について説明しました。 次に、さまざまなPostgreSQLの負荷の下でLinuxでHugePagesを構成した後の比較テストの結果を共有します。 異なる数の同時クライアントを使用して、多くの異なるPostgreSQLワークロードの下で完全なテストスイートを実施しました。

テストが実行されたPC
- Supermicroサーバー:
- インテル®Xeon®CPU E5-2683 v3 @ 2.00 GHz
- 2ソケット/ 28コア/ 56スレッド
- メモリー:256 GB RAM
- ストレージ:SAMSUNG SM863 1.9 TBエンタープライズSSD
- ファイルシステム:ext4 / xfs
- OS:Ubuntu 16.04.4、カーネル4.13.0-36-generic
- PostgreSQL:バージョン11
Linuxカーネル設定
最適化/チューニングなしでデフォルトのカーネルパラメーターを使用し、Transparent HugePagesのみを無効にしました。 このテクノロジーはデフォルトで有効になっており、データベースでの使用が推奨されていないサイズのページを割り当てます。 一般に、データベースには固定サイズのHugePagesが必要ですが、Transparent HugePagesはそれらを提供できません。 したがって、この機能を無効にし、デフォルトで従来のHugePagesをインストールすることを常にお勧めします。
PostgreSQLの設定
すべてのテストに同じPostgreSQL設定を使用して、異なるLinux HugePages設定で異なるPostgreSQLワークロードを記録しました。 すべてのテストで、次のPostgreSQL設定が適用されました。
shared_buffers = '64GB' work_mem = '1GB' random_page_cost = '1' maintenance_work_mem = '2GB' synchronous_commit = 'on' seq_page_cost = '1' max_wal_size = '100GB' checkpoint_timeout = '10min' synchronous_commit = 'on' checkpoint_completion_target = '0.9' autovacuum_vacuum_scale_factor = '0.4' effective_cache_size = '200GB' min_wal_size = '1GB' wal_compression = 'ON'
テストスキーム
テストスキームは重要な役割を果たします。 すべてのテストは3回実行され、各実行時間は30分です。 これら3つのテストの結果に基づいて、平均値を推定しました。 テストはPostgreSQL pgbenchツールを使用して実行され、約16 MBの負荷のスケーリングファクターで動作します。
巨大ページ
デフォルトでは、Linuxは4KメモリページとHugePagesテクノロジーを使用します。 BSDはスーパーページテクノロジーを使用し、Windowsはラージページを使用します。 PostgreSQLは、HugePages(Linux)テクノロジーのみをサポートしています。 使用されるメモリの量が多い場合、ページを小さくするとパフォーマンスが低下します。 HugePagesを使用すると、アプリケーションに割り当てられたメモリが増加するため、割り当て/スワッピングプロセス中に発生する「オーバーヘッド」が削減されます。 したがって、HugePagesは生産性を向上させます。
1GB HugePagesの設定は次のとおりです。 この情報は、/ procを使用していつでも利用できます。
AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 100 HugePages_Free: 97 HugePages_Rsvd: 63 HugePages_Surp: 0 Hugepagesize: 1048576 kB
以前の投稿でHugePagesについて詳しく書いた。
https://www.percona.com/blog/2018/08/29/tune-linux-kernel-parameters-for-postgresql-optimization/
一般に、HugePagesのサイズは2 MBと1 GBであるため、1 GBを使用するのが理にかなっています。
https://kerneltalks.com/services/what-is-huge-pages-in-linux/
試験結果
このテストは、さまざまなサイズのHugePagesを使用した場合の全体的な効果を示しています。 最初のテストスイートは、Linuxでデフォルトで使用される4Kページサイズで作成され、HugePagesアクティベーションなしで作成されました。 思い出させてください:テストの全期間にわたってTransparent HugePagesオプションを無効にしました。
次に、2 MBのサイズのHugePagesに対して2番目のテストセットが実行されました。 最後に、1GB HugePagesに対して3番目のテストセットが実行されました。
すべての比較テストにはPostgreSQL DBMS 11が使用され、キットにはさまざまなサイズのデータベースとさまざまなクライアントの組み合わせが含まれています。 以下のグラフは、これらのテストを使用したパフォーマンス比較の結果を示しています。TPS(1秒あたりのトランザクション数)-Y軸に沿って、特定のサイズのデータベースのデータベースサイズとクライアント数-X軸に沿って。
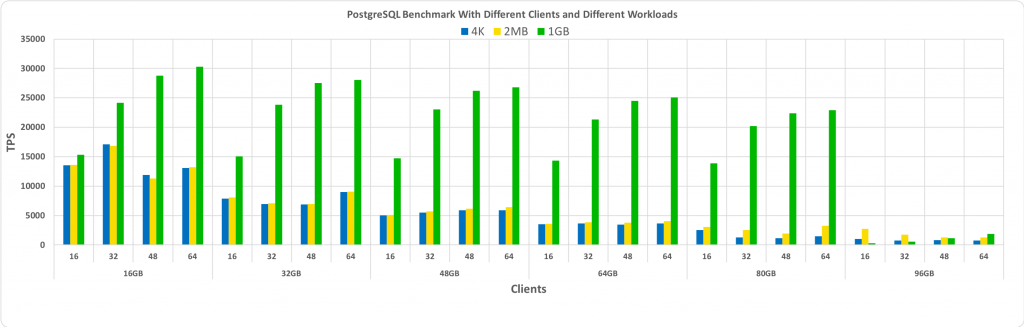
上記のグラフからわかるように、HugePagesを使用すると、顧客数とデータベースのサイズが増加するにつれて、このサイズが事前に割り当てられた共有バッファー内にある限り、ゲインが増加します。
このテストでは、TPSと顧客数を比較しました。 この場合、データベースサイズは48 GBです。 Y軸はTPSを示し、X軸は接続されたクライアントの数を示します。 データベースは、64 GBの固定サイズの共有バッファーに収まるほど小さいです。
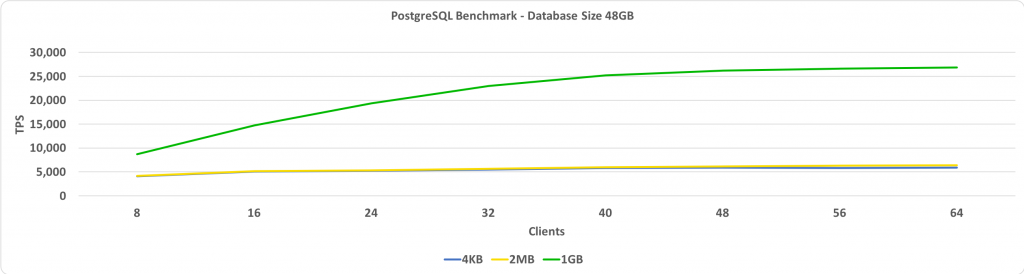
HugePagesのサイズが1 GBの場合、比較パフォーマンスの向上は顧客の数とともに増加します。
次のグラフは前のグラフと同じですが、データベースサイズは96 GBです。 これは、指定された64 GBの合計バッファサイズよりも大きくなります。
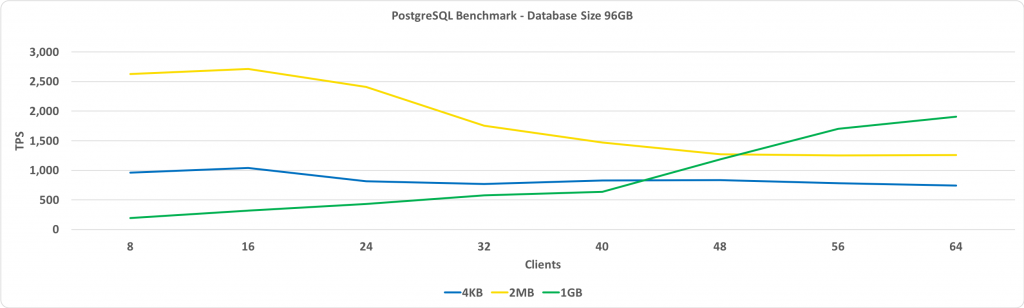
ここで注意すべき主な点は、1 GBのHugePagesのパフォーマンスは顧客数の増加に伴い増加し、最終的に2 MBのHugePagesまたは標準の4 KBページを使用する場合よりもパフォーマンスが向上することです。
このテストは、データベースサイズに対するTPSの比率を示します。 この場合、接続されているクライアントの数は32です。Y軸にはTPSが表示され、X軸にはデータベースサイズが表示されます。
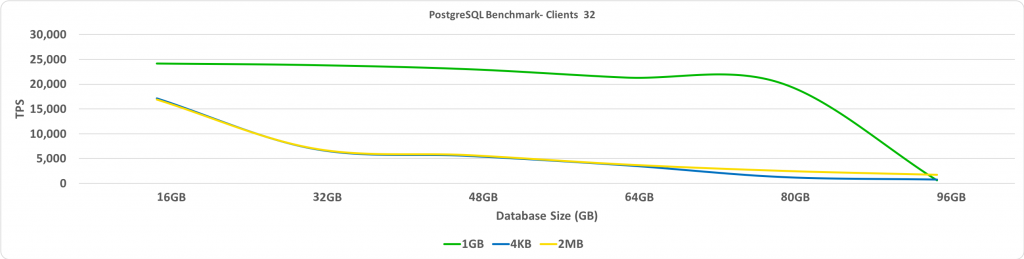
予想どおり、データベースのサイズが事前に割り当てられたHugePagesのサイズを超えると、パフォーマンスが大幅に低下します。
おわりに
私の主な推奨事項の1つは、Transparent HugePagesを無効にすることです。 HugePagesが有効になっているデータベースを共有バッファーに配置すると、パフォーマンスが大幅に向上します。 HugePagesの最適なサイズは試行錯誤によって決定されますが、データベースサイズが十分に大きい場合、このアプローチによりTPSが大幅に向上する可能性がありますが、同時に共通のバッファーに収まります。