ピボットテーブルを例として使用して、Javascriptパフォーマンスの戦いを続けています。 前回 、いくつかの最適化を実装し、計算を高速化する最後の本当の機会がありました-マルチスレッド計算への切り替え。 Javascriptには、実装に欠陥がないわけではないワーカーが長い間存在しますが、実際のオペレーティングシステムスレッドを使用すると言われています。 予想外に、単純なアルゴリズムを並列化するには、集計式の構文を書き直す必要がありました。古い式には加法性プロパティがなかったためです(猫の詳細)が、結局はすべてうまくいきました
100万のファクトの処理は、2つのデバイスでテストされました。
- Netbook Linux 4.15、2 x Intel Celeron CPU N2830 @ 2.16 GHz
- Androidフォン7.0、4 x ARM Cortex-A53 @ 1.44 GHz
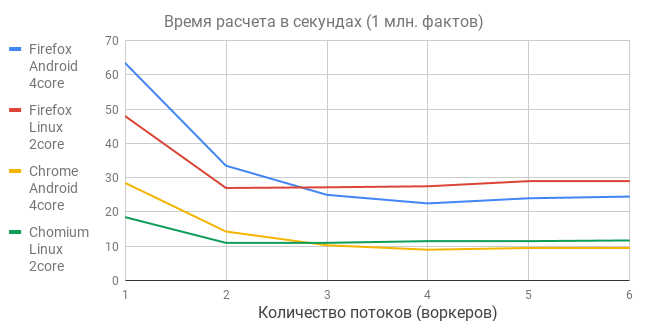
グラフから、いくつかの結論が続きます。
- マルチスレッドによる利益は、奇跡がないため、非常に控えめで、予想よりはるかに少ないことが判明しました。ソフトウェアマルチスレッドにはハードウェアマルチプロセッシングが必要であり、デバイスにはコアがほとんどありません。
- ワーカープールの最適なサイズは、コアの数と同じです。 そのため、すべてのシングルスレッドテストを安定して再生した電話機が突然急いで進み、最高の結果、9秒で100万の事実を示しました。
- ワンパスアルゴリズムは線形にスケーリングします-初期データのボリュームが1桁増加すると、計算時間は同じオーダで増加します。 電話でチェック-1000秒で1000万の事実が80秒、1億の事実で計算されました。 何もハングして落ちませんでした。 約15年前、Oracleは通常このサイズのテーブル用に購入されました。
- ビジネスアプリケーションはWEBおよび携帯電話に積極的に移行しているため、マルチコアの個人用デバイスは絶対に正当化され、フロントエンドであってもマルチスレッドプログラミングは必須です。
テストを自分で試すことができます- アプリケーションはこちら 、テストデータジェネレーターが含まれ、計算時間が表示されます。
アルゴリズム機能
私たちのアルゴリズムが何であるかを思い出させてください。 ファクトの非構造化リポジトリはソースデータとして使用され、データスキーマは作成されません。 入力はJSONで、操作とディレクトリが混在しています。 2つのレベルで計算を定義します-個々のファクト(本質的には計算された属性)のレベルでの式と、ピボットテーブルの行レベルでの集約式。 次に、フィルターを適用し、ファクトの配列を1回通過してピボットテーブルを作成します。 この単一サイクルでは、グループ化が実行され、集計が計算され、参照データが抽出され、列の幅が決定されます。
データはIndexedDBブロックに保存され、各ワーカーには一定範囲のブロックが割り当てられ、メインスレッドはワーカーを開始し、定期的にワーカーからステータス(処理済みレコードの数)を受け取り、すべてが停止するのを待ってから結果を要約します。 制御の例では、結果を減らすための時間はごくわずかですが、他のデータにはもちろんオプションがあります。 結果を正しく減らすには、すべての集計式に加算性が必要です。つまり、単一のファクトとすでに計算されたブロックの両方に適用できます。
集計式
Excel、アダルトOLAPシステム、およびRDBMSでスクリプト言語で独自の集計関数を記述できないが、sum()、avg()などの定義済みタイプのセットのみが含まれている理由を理解できませんでした。 たとえば、長い間、Excelにはcount_distinct関数さえありませんでしたが、現在でもすべてのDBMSにあるわけではありません。 ユーザーが集計関数を定義できるようにすると、すべての関数が加算的になるわけではないことがわかります。つまり、計算を並列化できず、産業システムにとって致命的です。 これを、3つの配列集約関数の例で示します。
console.log([1, 2, 3, 4].reduce( (accumulator, currentValue) => accumulator + currentValue )); console.log([1, 2, 3, 4].reduce( (accumulator, currentValue) => (accumulator + currentValue) ** 2 )); console.log([1, 2, 3, 4].reduce( (accumulator, currentValue) => accumulator + currentValue ** 2 ));
最初の関数は、それ自体に適用できるため、加算的です。
アキュムレーター+(アキュムレーター+ currentValue) 。
2番目の関数はまったく並列化できません。3番目の関数を使用する必要があります。額にブロックを適用するためです。
accumulator +(accumulator + currentValue ** 2)** 2-誤った結果が得られますが、式を解析して、これが単なる二乗和であると理解すると、加法性が達成されます。 このアルゴリズムでは、アキュムレーターは単なるスカラーではなく、ピボットテーブルの現在の行を表す配列であり、currentValueはそれぞれ、現在のファクト(計算されたものを含む)の属性の値の配列です。その結果、相加性を破るリスクが増加します。
アプリケーションの最初のバージョンでは 、集計式でファクト(colname)および行(colname)関数が使用され(最初は現在のファクトの属性を返し、2番目はピボットテーブルの列の中間計算値を返します)、合計、数量カウント式はそれらから既に構成されていたこと、など ただし、ユーザーは、たとえば、1つの集計式でファクトのいくつかの属性を使用したがるので、マルチスレッドが必要な場合は受け入れられません。 私は式を解析するのが面倒でした-ユーザーが何を考えることができるか決してわかりません-そして私は集約式でファクト属性の使用を禁止することを最も簡単な決定をしましたが、事前定義された集約プリミティブでそれらをラップすることによってのみ、したがって、サマリーテーブルはそのような式で記述されます:
"quantity-sum": "sum('quantity')", "amount-sum": "round(sum('amount'), 2)", "price-max": "max('price')", "price-min": "min('price')", "price-last": "last('price')", "price-avg": "round(sum('price') / count(), 2)", "price-weight": "round(sum('amount') / sum('quantity'), 2)", "EAN-code": "selectlast('EAN-code', \"fact('product') == row('product')\")"
繰り返し計算は行われません-集約プリミティブの計算結果はキャッシュされます。 プリミティブsum()、count()、mul()、min()、max()、last()、first()が使用可能です。 最後の関数selectlast()は、別の事実からディレクトリの参照を取得します。つまり、実際には結合リポジトリをそれ自体に実装しますが、共通のサイクルで、つまりパフォーマンスを損なうことなく計算されます。 関数mode() 、 median() 、count_distinct()に関しては、これらは加算的ではなく、計算の終わりまですべての値を別の構造(メモリ消費)に保存する必要があるため、線形にスケーリングしないため、後で実装されます。
まとめ
おそらく、これでJavascriptをオーバークロックしようとする試みを終わらせることができ、Excelに追いつくことはできませんでした。 理論的には、GPUコンピューティングの方向を引き続き見ることができます。このため、アルゴリズムを完全に書き直す必要があります( 前例があります )が、原則として、かなりうまくいきました。 楽しいプログラミングと新鮮なアイデアをお祈りします!