
本日公開する翻訳の資料では、Node.jsのメモリを使用した効果的な作業に焦点を当てます。 特に、ストリーム、バッファ、
pipe()
ストリームメソッドなどの概念について説明します。 Node.js v8.12.0が実験で使用されます。 サンプルコードのリポジトリはこちらにあります 。
タスク:巨大なファイルをコピーする
Node.jsでファイルをコピーするためのプログラムを作成するように求められた場合、ほとんどの場合、すぐに次のようなものを作成します。 このコードを含むファイルに
basic_copy.js
という名前を付けます。
const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; fs.readFile(fileName, (err, data) => { if (err) throw err; fs.writeFile(destPath || 'output', data, (err) => { if (err) throw err; }); console.log('New file has been created!'); });
このプログラムは、指定された名前のファイルを読み書きするためのハンドラーを作成し、読み取り後にファイルデータの書き込みを試みます。 小さなファイルの場合、このアプローチは機能しています。
データバックアッププロセス中にアプリケーションで巨大なファイル(4 GBを超える「巨大な」ファイルを考慮する)をコピーする必要があるとします。 たとえば、7.4 GBのビデオファイルがあり、上記のプログラムを使用して、現在のディレクトリから
Documents
ディレクトリにコピーしようとします。 コピーを開始するコマンドは次のとおりです。
$ node basic_copy.js cartoonMovie.mkv ~/Documents/bigMovie.mkv
Ubuntuでは、このコマンドを実行した後、バッファーオーバーフローに関連するエラーメッセージが表示されました。
/home/shobarani/Workspace/basic_copy.js:7 if (err) throw err; ^ RangeError: File size is greater than possible Buffer: 0x7fffffff bytes at FSReqWrap.readFileAfterStat [as oncomplete] (fs.js:453:11)
ご覧のとおり、Node.jsでは2 GBのデータのみをバッファーに読み込むことができるため、ファイルの読み取り操作は失敗しました。 この制限を克服する方法は? I / Oサブシステムを集中的に使用する操作(ファイルのコピー、処理、圧縮)を実行する場合、システムの機能とメモリに関連する制限を考慮する必要があります。
Node.jsのストリームとバッファー
上記の問題を回避するには、大量のデータを小さな断片に分割できるメカニズムが必要です。 また、これらのフラグメントを保存して操作できるデータ構造も必要です。 バッファは、バイナリデータを格納できるデータ構造です。 次に、ディスクからデータの一部を読み取り、ディスクに書き込むことができる必要があります。 この機会は私たちにフローを与えることができます。 バッファとスレッドについて話しましょう。
▍バッファ
Buffer
オブジェクトを初期化することにより、
Buffer
作成できます。
let buffer = new Buffer(10); // 10 - console.log(buffer); // <Buffer 00 00 00 00 00 00 00 00 00 00>
8日以降のNode.jsのバージョンでは、次の構成を使用してバッファーを作成するのが最適です。
let buffer = new Buffer.alloc(10); console.log(buffer); // <Buffer 00 00 00 00 00 00 00 00 00 00>
配列などのデータが既にある場合は、このデータに基づいてバッファーを作成できます。
let name = 'Node JS DEV'; let buffer = Buffer.from(name); console.log(buffer) // <Buffer 4e 6f 64 65 20 4a 53 20 44 45 5>
バッファには、「覗き見」してそこにあるデータを見つけることができるメソッドがあります。これらは
toString()
および
toJSON()
メソッドです。
コードを最適化する過程で、自分でバッファを作成することはありません。 Node.jsは、ストリームまたはネットワークソケットを操作するときにこれらのデータ構造を自動的に作成します。
▍ストリーム
SFの言語に目を向けると、ストリームは他の世界へのポータルと比較できます。 ストリームには4つのタイプがあります。
- 読み取り用のストリーム(そこからデータを読み取ることができます)。
- 記録用のストリーム(データを送信できます)。
- デュプレックスストリーム(データの読み取りとデータの送信の両方で開かれています)。
- 変換ストリーム(データを処理したり、圧縮したり、正当性を確認したりできる特別な二重ストリーム)。
Node.jsのストリームAPI、特に
stream.pipe()
メソッドの重要な目標は、データバッファリングを許容可能なレベルに制限することであるため、ストリームが必要です。 これは、異なる処理速度で異なるデータのソースとレシーバーを操作しても、使用可能なメモリがオーバーフローしないようにするためです。
言い換えると、大きなファイルをコピーする問題を解決するには、システムに過負荷をかけないようにする何らかのメカニズムが必要です。
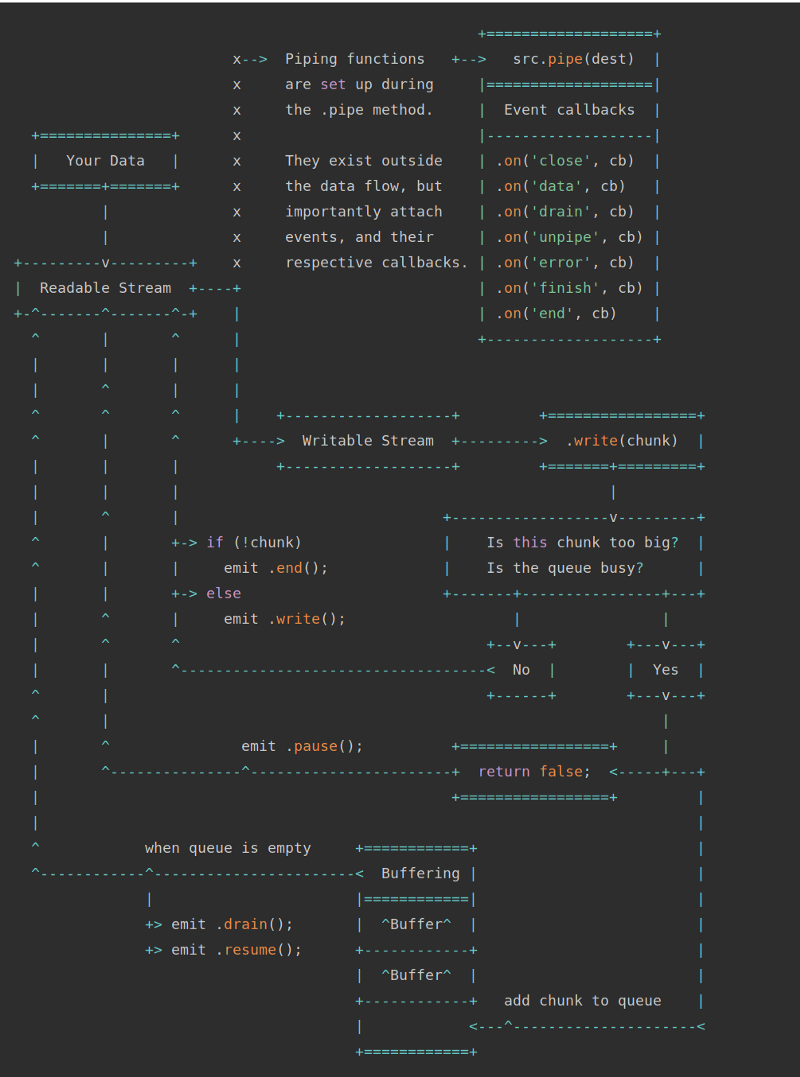
ストリームとバッファ(Node.jsドキュメントに基づく)
前の図は、読み取り可能なストリームと書き込み可能なストリームの2種類のストリームを示しています。
pipe()
メソッドは、書き込み用のストリームに読み取り用のストリームを接続できる非常に単純なメカニズムです。 上記のスキームが特に明確でない場合は、大丈夫です。 次の例を分析した後、簡単に対処できます。 特に、今度は
pipe()
メソッドを使用したデータ処理の例を検討します。
解決策1.ストリームを使用してファイルをコピーする
上で説明した巨大なファイルをコピーする問題の解決策を検討してください。 このソリューションは2つのスレッドに基づいており、次のようになります。
- 次のデータが読み取り用にストリームに表示されることを期待しています。
- 受信したデータを書き込み用のストリームに書き込みます。
- コピー操作の進行状況を監視します。
このアイデアを実装するプログラムを
streams_copy_basic.js
と呼びます。 彼女のコードは次のとおりです。
/* . : Naren Arya */ const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readable = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readable.on('data', (chunk)=> { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); writeable.write(chunk); this.counter += 1; }); readable.on('end', (e) => { process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write("Successfully finished the operation"); return; }); readable.on('error', (e) => { console.log("Some error occurred: ", e); }); writeable.on('finish', () => { console.log("Successfully created the file copy!"); }); });
ユーザーがこのプログラムを実行して2つのファイル名を提供することを期待しています。 1つ目はソースファイル、2つ目は将来のコピーの名前です。 読み取り用のストリームと書き込み用のストリームの2つのストリームを作成し、最初のデータを2番目に転送します。 いくつかの補助的なメカニズムもあります。 これらは、コピープロセスを監視し、対応する情報をコンソールに出力するために使用されます。
ここでは、イベントメカニズムを使用します。特に、次のイベントのサブスクライブについて説明しています。
-
data
-data
一部を読み取るときに呼び出されます。 -
end
読み取りストリームからデータが読み取られるときに呼び出されます。 -
error
-データの読み取りプロセスでエラーが発生した場合に呼び出されます。
このプログラムを使用すると、7.4 GBのファイルがエラーメッセージなしでコピーされます。
$ time node streams_copy_basic.js cartoonMovie.mkv ~/Documents/4kdemo.mkv
ただし、1つの問題があります。 さまざまなプロセスによるシステムリソースの使用に関するデータを調べることで特定できます。
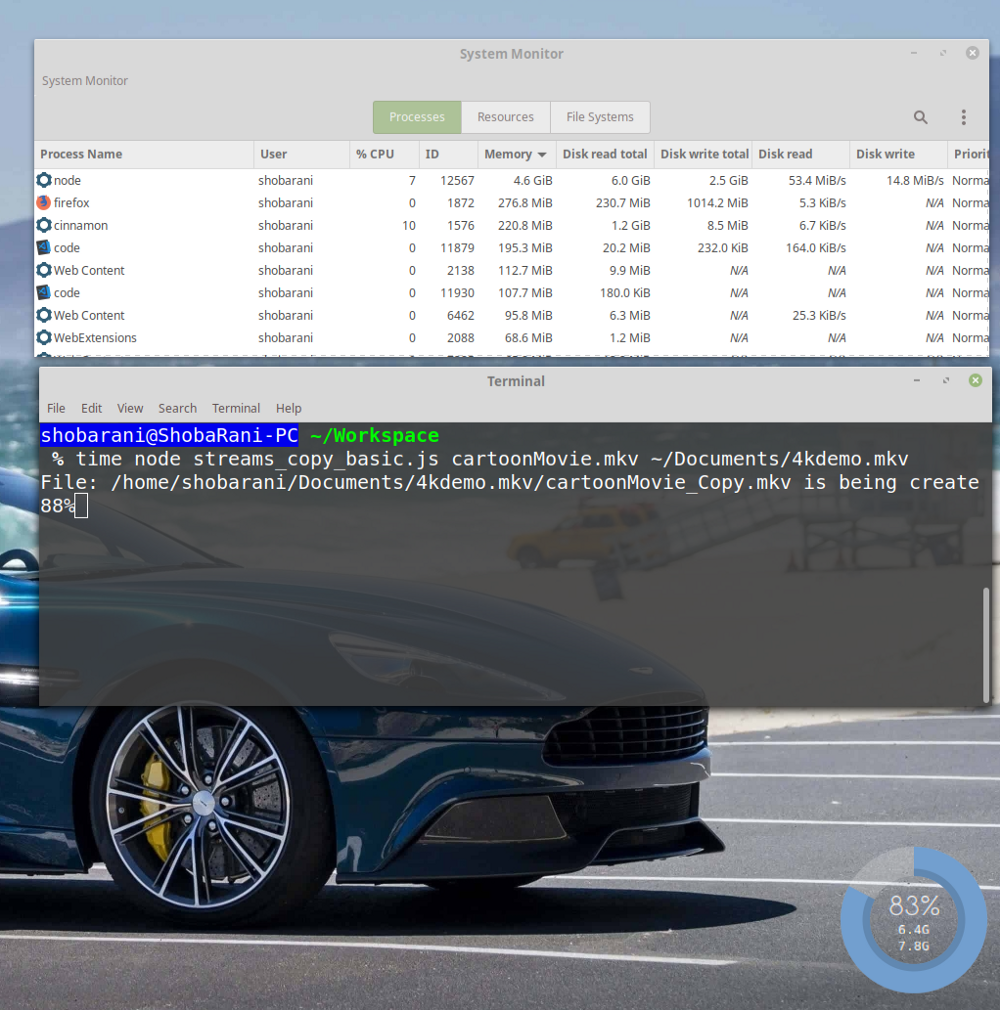
システムリソース使用量データ
node
プロセスは、ファイルの88%をコピーした後、4.6 GBのメモリを消費することに注意してください。 これは非常に多く、このようなメモリの処理は他のプログラムの動作を妨げる可能性があります。
excessive過剰なメモリ消費の理由
前の図のディスクからのデータの
Disk Read
と
Disk Write
へのデータの書き込みの速度に注意して
Disk Read
([
Disk Read
列と[
Disk Write
列)。 つまり、ここでは次のインジケータを確認できます。
Disk Read: 53.4 MiB/s Disk Write: 14.8 MiB/s
データレコードと読み取り速度のこの違いは、データソースがそれらを生成することを意味します。 コンピュータは、ディスクに書き込まれるまで、読み取ったデータをメモリに保存する必要があります。 その結果、メモリ使用量のこのようなインジケータが表示されます。
私のコンピューターでは、このプログラムは3分16秒実行されました。 その進捗に関する情報は次のとおりです。
17.16s user 25.06s system 21% cpu 3:16.61 total
解決策2.ストリームを使用し、データの読み取りと書き込みの速度を自動調整してファイルをコピーする
上記の問題に対処するために、ファイルのコピー中に読み取りおよび書き込み速度が自動的に構成されるようにプログラムを変更できます。 このメカニズムはバックプレッシャーと呼ばれます。 それを使用するために、特別なことをする必要はありません。
pipe()
メソッドを使用して、読み取りストリームを書き込みストリームに接続するだけで十分です。Node.jsはデータ転送速度を自動的に調整します。
このプログラムを
streams_copy_efficient.js
呼びます。 彼女のコードは次のとおりです。
/* pipe(). : Naren Arya */ const stream = require('stream'); const fs = require('fs'); let fileName = process.argv[2]; let destPath = process.argv[3]; const readable = fs.createReadStream(fileName); const writeable = fs.createWriteStream(destPath || "output"); fs.stat(fileName, (err, stats) => { this.fileSize = stats.size; this.counter = 1; this.fileArray = fileName.split('.'); try { this.duplicate = destPath + "/" + this.fileArray[0] + '_Copy.' + this.fileArray[1]; } catch(e) { console.exception('File name is invalid! please pass the proper one'); } process.stdout.write(`File: ${this.duplicate} is being created:`); readable.on('data', (chunk) => { let percentageCopied = ((chunk.length * this.counter) / this.fileSize) * 100; process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write(`${Math.round(percentageCopied)}%`); this.counter += 1; }); readable.on('error', (e) => { console.log("Some error occurred: ", e); }); writeable.on('finish', () => { process.stdout.clearLine(); // process.stdout.cursorTo(0); process.stdout.write("Successfully created the file copy!"); }); readable.pipe(writeable); // ! });
このプログラムと以前のプログラムの主な違いは、データフラグメントをコピーするためのコードが次の行に置き換えられていることです。
readable.pipe(writeable); // !
ここで発生するすべての中心にあるのは
pipe()
メソッドです。 読み取りと書き込みの速度を制御します。これにより、メモリが過負荷にならないようになります。
プログラムを実行します。
$ time node streams_copy_efficient.js cartoonMovie.mkv ~/Documents/4kdemo.mkv
同じ巨大なファイルをコピーしています。 次に、メモリとディスクの操作がどのように見えるかを見てみましょう。
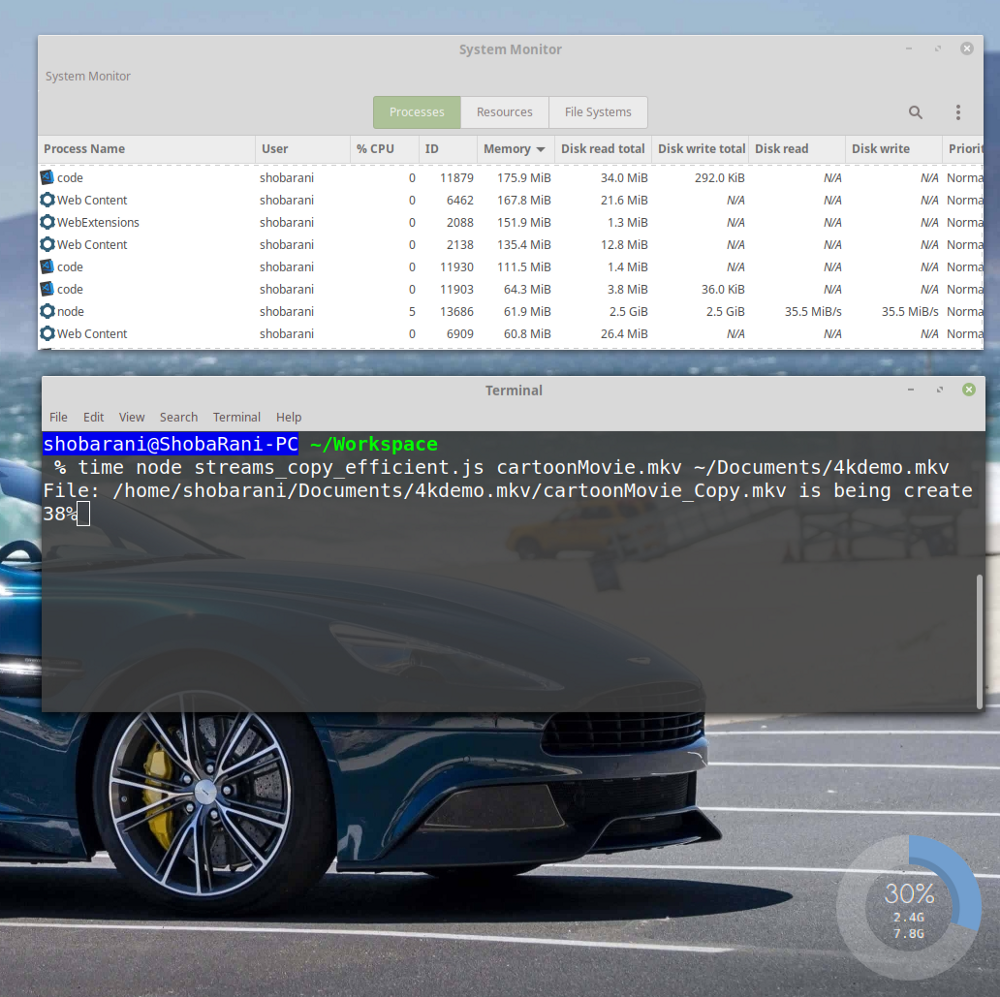
パイプ()を使用することにより、読み取りおよび書き込み速度が自動的に構成されます
node
プロセスが消費するメモリは61.9 MBのみであることがわかります。 ディスク使用量に関するデータを見ると、次のことがわかります。
Disk Read: 35.5 MiB/s Disk Write: 35.5 MiB/s
バックプレッシャーメカニズムのおかげで、読み取りと書き込みの速度は常に同じになりました。 さらに、新しいプログラムは古いプログラムよりも13秒速く実行されます。
12.13s user 28.50s system 22% cpu 3:03.35 total
pipe()
メソッドのおかげで、プログラムの実行時間を短縮し、メモリ消費を98.68%削減できました。
この場合、61.9 MBはデータ読み取りストリームによって作成されたバッファーのサイズです。 ストリームの
read()
メソッドを使用して
read()
ことで、このサイズを適切に設定できます。
const readable = fs.createReadStream(fileName); readable.read(no_of_bytes_size);
ここでは、ファイルをローカルファイルシステムにコピーしましたが、同じアプローチを使用して、他の多くのデータ入出力タスクを最適化できます。 たとえば、これはソースがKafkaで、レシーバーがデータベースであるデータストリームで動作しています。 同じスキームを使用して、ディスクからの読み取りデータを整理し、「オンザフライ」で言うように圧縮し、すでに圧縮された形式でディスクに書き戻すことができます。 実際、ここで説明されているテクノロジーには、他にも多くのアプリケーションがあります。
まとめ
この記事の目的の1つは、このプラットフォームが開発者に優れたAPIを提供しているにもかかわらず、Node.jsで不正なプログラムを作成することがいかに簡単かを示すことでした。 このAPIにある程度注意を払えば、サーバー側のソフトウェアプロジェクトの品質を向上させることができます。
親愛なる読者! Node.jsのバッファーとスレッドをどのように使用しますか?
