
それはすっかり始まりました-今では、私の会社は写真にあるナンバープレートのある地域を見つけることができるサービスに対して月額料金を支払いました。 この関数は、一部のクライアントの番号を自動的にスケッチするために使用されます。
ある晴れた日、ウクライナ内務省は車両登録簿へのアクセスを開始しました。 これで、ナンバープレートを使用して、車に関する情報(メーカー、モデル、製造年、色など)を確認できるようになりました。 線形プログラミングの退屈なルーチンは、新しいタスクの前に衰退しました-写真ベース全体の数字を読み取り、ユーザーが指定したものでこのデータを検証します。 あなたはそれがどのように「目が光る」かを知っています-呼び出しは受け入れられ、他のすべてのタスクはしばらく退屈で単調になりました...私たちは仕事を始めて、良い結果を得ました。実際、私たちはコミュニティと共有することにしました。
参考:AUTO.RIA.comサイトでは、1日に約100,000枚の写真が追加されています。Datasaentistsはそのような問題を長い間知っており、解決できるので、 dimabenderaと私はプログラマ向けにこの記事を書きました。 「畳み込みネットワーク」というフレーズを恐れず、Pythonで「Hello World」を書く方法を知っているなら、猫の下で歓迎されます…
誰が認める
一年前、私はこの市場を調査しましたが、exUSSRの国番号で動作できるサービスとソフトウェアは多くないことが判明しました。 以下は、協力した企業のリストです。
自動ナンバープレート認識
オープンソースと商用バージョンがあります。 オープンソース版は非常に低い認識率を示しました。さらに、アセンブリと操作に特定の依存関係が必要でした(特に気に入らなかった)。 商用版、またはむしろ商用サービスがうまく機能します。 ロシア語とウクライナ語の数字を扱うことができます。 価格は中程度です-1か月あたり49ドル/ 5万回の認識。 OpenALPRのオンラインデモ
認識者
このサービスは約1年間使用しました。 品質は良いです。 彼はその番号のあるエリアを非常によく見つけます。 このサービスは、ウクライナおよびヨーロッパの番号を処理する方法を知りません。 低品質の画像(雪の中、低解像度の写真など)を使用した場合の優れた成果に注目してください。 サービスの価格も許容できますが、少量の購入には消極的です。
クローズドソフトウェアを備えた商用システムは数多くありますが、適切なオープンソースの実装は見つかりませんでした。 実際、これは非常に奇妙です。なぜなら、この問題の解決策の根底にあるオープンソースのツールは長い間存在していたからです。
数字を認識するために必要なツール
画像またはビデオストリームでオブジェクトを見つけることは、さまざまなアプローチで解決されますが、ほとんどの場合、いわゆる畳み込みニューラルネットワークの助けを借りて解決されるコンピュータービジョンの分野のタスクです。 写真内の目的のオブジェクトが見つかった領域だけでなく、そのすべてのポイントを他のオブジェクトまたは背景から分離する必要もあります。 この種のタスクは「インスタンスセグメンテーション」と呼ばれます。 次の図は、さまざまな種類のコンピュータービジョンタスクを視覚化します。
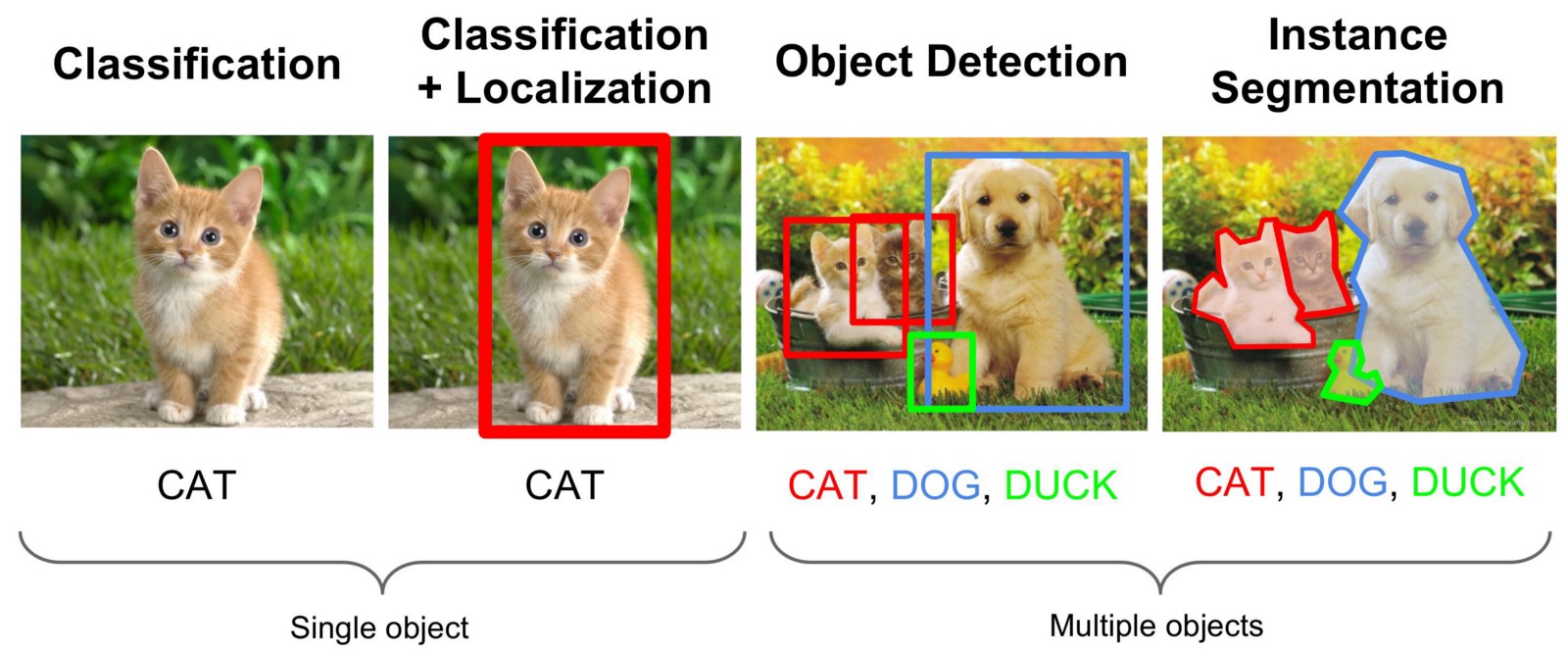
たたみ込みネットワークがどのように機能するかについての理論はあまり書きませんが、この情報はネットワーク上で十分であり、youtubeでレポートします。
セグメンテーションタスク用の畳み込み配列の最新のアーキテクチャから、 U-NetまたはMask R-CNNを使用することがよくあります。 Mask R-CNNを選択しました。
必要な2番目のツールは、異なる言語で動作し、認識されるテキストの詳細に合わせて簡単にカスタマイズできるテキスト認識ライブラリです。 ここでの選択はそれほど大きくありませんが、最も高度なのはGoogleのtesseractです。
また、ライセンスプレートを使用して領域を正規化する必要がある(テキスト認識が可能になるような方法でそれを提供する)必要のない「グローバル」なツールもいくつかあります。 通常、このような変換にはopencvが使用されます。
また、ナンバープレート番号が属する国とタイプを決定しようとする可能性があるため、後処理では、この国とこのタイプの番号に固有の絞り込みテンプレートを適用します。 たとえば、2015年に開始され、青と黄色で装飾されたウクライナのナンバープレートは、「2文字4数字2文字」のテンプレートで構成されています。

さらに、特定の文字または数字の組み合わせのナンバープレートで「会議」の頻度に関する統計情報を取得すると、「物議を醸す」状況での後処理の品質を向上させることができます。 」
ノメロフネット
記事のタイトルから、私たち全員がプロジェクトNomeroff Netを実装し、命名したことは明らかです。 現在、このプロジェクトのコードの一部は、すでにAUTO.RIA.comで運用されています。 もちろん、それはまだ商業的なアナログとはほど遠いです、すべてがウクライナの数字でのみうまく機能します。 さらに、許容可能な速度は、GPUモジュールテンソルフローのサポートによってのみ達成されます! GPUがなくても試すことはできますが、Raspberry Piではできません:)。
私たちのプロジェクトのすべての資料: マークアップされたデータセットと訓練されたモデル 、私たちはRIA.comの許可を得てCreative Commons CC BY 4.0ライセンスの下で公開しました
何が必要ですか
- Python3
- opencv-pythonバージョン3.4以降
- フレッシュマスクRCNN 、 tesseract
- pip3パッケージマネージャーを使用して、python3にいくつかのモジュールをインストールする必要があります。それらは個別のrequirements.txtファイルにリストされます。
Dmitryと私はすべてFedora 28で実行しています。他のLinuxディストリビューションにもすべてインストールできると確信しています。 あなたが試してみたいと何かがうまくいかない場合、私はこの投稿をテンソルフローのインストールと設定の手順にしたくないでしょう-コメントで尋ねて、私は答えてあなたに伝えます。
インストールを高速化するために、dockerfileの作成を計画しています-プロジェクトの次の更新で予定されています。
ノメロフネット「ハローワールド」
何かを認識してみましょう。 githubのコードを使用してリポジトリを複製しています 。 モデルフォルダーにダウンロードし、数値を検索および分類するための訓練されたモデルを作成します。変数を自分用のフォルダーの場所でわずかに調整します。
UPD:このコードは非推奨です。0.1.0ブランチでのみ動作し ます 。 最新の例を参照してください :
すべてが認識できます:
import os import sys import json import matplotlib.image as mpimg # change this property NOMEROFF_NET_DIR = "/var/www/nomeroff-net/" MASK_RCNN_DIR = "/var/www/Mask_RCNN/" MASK_RCNN_LOG_DIR = os.path.join(NOMEROFF_NET_DIR, "logs/") MASK_RCNN_MODEL_PATH = os.path.join(NOMEROFF_NET_DIR, "models/mask_rcnn_numberplate_0700.h5") REGION_MODEL_PATH = os.path.join(NOMEROFF_NET_DIR, "models/imagenet_vgg16_np_region_2019_1_18.h5") sys.path.append(NOMEROFF_NET_DIR) # Import license plate recognition tools. from NomeroffNet import filters, RectDetector, TextDetector, RegionDetector, Detector, textPostprocessing # Initialize npdetector with default configuration file. nnet = Detector(MASK_RCNN_DIR, MASK_RCNN_LOG_DIR) # Load weights in keras format. nnet.loadModel(MASK_RCNN_MODEL_PATH) # Initialize rect detector with default configuration file. rectDetector = RectDetector() # Initialize text detector. textDetector = TextDetector() # Initialize numberplate region detector. regionDetector = RegionDetector() regionDetector.load(REGION_MODEL_PATH) img_path = './examples/images/example1.jpeg' img = mpimg.imread(img_path) NP = nnet.detect([img]) # Generate image mask. cv_img_masks = filters.cv_img_mask(NP) for img_mask in cv_img_masks: # Detect points. points = rectDetector.detect(img_mask, fixRectangleAngle=1, outboundWidthOffset=3) # Split on zones zone = rectDetector.get_cv_zones(img, points) # find standart regionId = regionDetector.predict(zone) regionName = regionDetector.getLabels(regionId) # find text with postprocessing by numberplate region detector text = textDetector.detect(zone) text = textPostprocessing(text, regionName) print('Detected numberplate: "%s" in region [%s]'%(text,regionName)) # Detected numberplate: "AC4921CB" in region [eu-ua-2015]
オンラインデモ
このすべてをインストールして実行したくない人のための簡単なデモをスケッチしました:)。 スクリプトの速度に寛容で忍耐強くあります。
(補正アルゴリズムの動作を確認するために)ウクライナの数値の例が必要な場合は、このフォルダーから例を取ります。
次は何ですか
このトピックは非常にニッチであり、幅広いプログラマーに大きな関心を呼びそうにないことを理解しています。さらに、コードとモデルは認識品質、速度、メモリ消費などの点でまだかなり「未加工」です。ニーズに合ったモデルのトレーニングに興味を持っている人、国、問題のある場所を教えてくれる人、そして私たちと一緒にプロジェクトを商業的な相手よりも悪くはしないでしょう。
既知の問題
- プロジェクトにはドキュメントはなく、基本的なコード例のみがあります。
- ユニバーサルOCR tesseractが認識モジュールとして選択され、多くの情報を読み取ることができますが、多くの間違いを犯します。 ウクライナの数字の認識の場合、特殊な修正システムがそこに書かれており、これはこれまでのところいくつかのエラーを補正しますが、ここでもっと多くのことができるようになっています。
- 「正方形」の番号(1:2の比率のライセンスプレート)は非常にまれであり、私たちはそれらに対処し始めたばかりなので、さらにエラーが発生します。
- 時には、ナンバープレートの代わりに、村の名前、小屋の中のダッシュボード、その他のアーティファクトが付いた道路標識を見つけます。
- 数値の質が低い、または解像度が低い場合、4ポイントの領域は完全には決定されません
発表
誰かにとって興味深い場合は、第2部で、データセットをマークアップする方法と方法、およびコンテンツ(国、写真のサイズ)に適したモデルをトレーニングする方法について説明します。 また、独自の分類子を作成する方法についても説明します。これは、たとえば、写真に番号がスケッチされているかどうかを判断するのに役立ちます。