GitHubは、 git
に関連しないすべての主要データウェアハウスとしてMySQLを使用しているため、MySQLの可用性はGitHubの通常の操作の鍵となります。 サイト自体、GitHub API、認証システム、およびその他の多くの機能には、データベースへのアクセスが必要です。 複数のMySQLクラスターを使用して、さまざまなサービスとタスクを処理します。 これらは、記録に使用できる1つのメインノードとそのレプリカを使用した従来のスキームに従って構成されます。 レプリカ (他のクラスターノード)は、メインノードへの変更を非同期的に再現し、読み取りアクセスを提供します。
ホストサイトの可用性は非常に重要です。 メインノードがないと、クラスターは記録をサポートしません。つまり、必要な変更を保存できません。 トランザクションの修正、問題の登録、新しいユーザーの作成、リポジトリ、レビューなどは、まったく不可能です。
記録をサポートするには、対応するアクセス可能なノード、つまりクラスター内のメインノードが必要です。 ただし、そのようなノードを識別または検出する能力も同様に重要です。
現在のメインノードに障害が発生した場合は、新しいサーバーを迅速に交換して交換し、すべてのサービスにこの変更を迅速に通知できるようにすることが重要です。 合計ダウンタイムは、障害の検出、フェイルオーバー、および新しいメインノードの通知にかかった時間の合計です。

この出版物は、GitHubでMySQLの高可用性を確保し、メインサービスを発見するためのソリューションについて説明しています。これにより、複数のデータセンターをカバーする操作を確実に実行し、これらのセンターの一部が利用できない場合に操作性を維持し、障害発生時の最小ダウンタイムを保証できます。
高可用性の目標
この記事で説明するソリューションは、GitHubに実装された以前の高可用性(HA)ソリューションの新しい改良バージョンです。 成長するにつれて、MySQL HA戦略を変化に適応させる必要があります。 MySQLおよびGitHubの他のサービスについても同様のアプローチに従うよう努めています。
高可用性とサービス検出のための適切なソリューションを見つけるには、最初にいくつかの特定の質問に答える必要があります。 それらのサンプルリストを次に示します。
- あなたにとって重要ではない最大ダウンタイムはどれくらいですか?
- 障害検出ツールの信頼性はどのくらいですか? 誤検知(早期障害処理)は重要ですか?
- フェールオーバーシステムの信頼性 障害はどこで発生しますか?
- 複数のデータセンターでのソリューションの有効性はどのくらいですか? 低遅延および高遅延ネットワークでのソリューションの有効性はどのくらいですか?
- 完全なデータセンター(DPC)の障害またはネットワークの分離が発生した場合でも、ソリューションは引き続き機能しますか?
- 独立して記録するクラスター内の2つのメインサーバーの出現の結果を防止または緩和するメカニズム(ある場合)
- データ損失はあなたにとって重要ですか? もしそうなら、どの程度まで?
デモンストレーションの目的で、最初に以前のソリューションを検討し、なぜそれを放棄することにしたのかを議論しましょう。
発見にVIPとDNSを使用することの拒否
前のソリューションの一部として、次を使用しました。
- 障害検出およびフェイルオーバーのオーケストレーター 。
- ホスト検出用のVIPおよびDNS。
その場合、クライアントは、たとえばmysql-writer-1.github.net
などの名前で記録ノードを検出しました。 この名前により、ホストの仮想IPアドレス(VIP)が決まりました。
したがって、通常の状況では、クライアントは名前を解決し、受信したIPアドレスに接続するだけで済みました。メインノードは既に待機していました。
3つの異なるデータセンターにまたがる次のレプリケーショントポロジを検討してください。
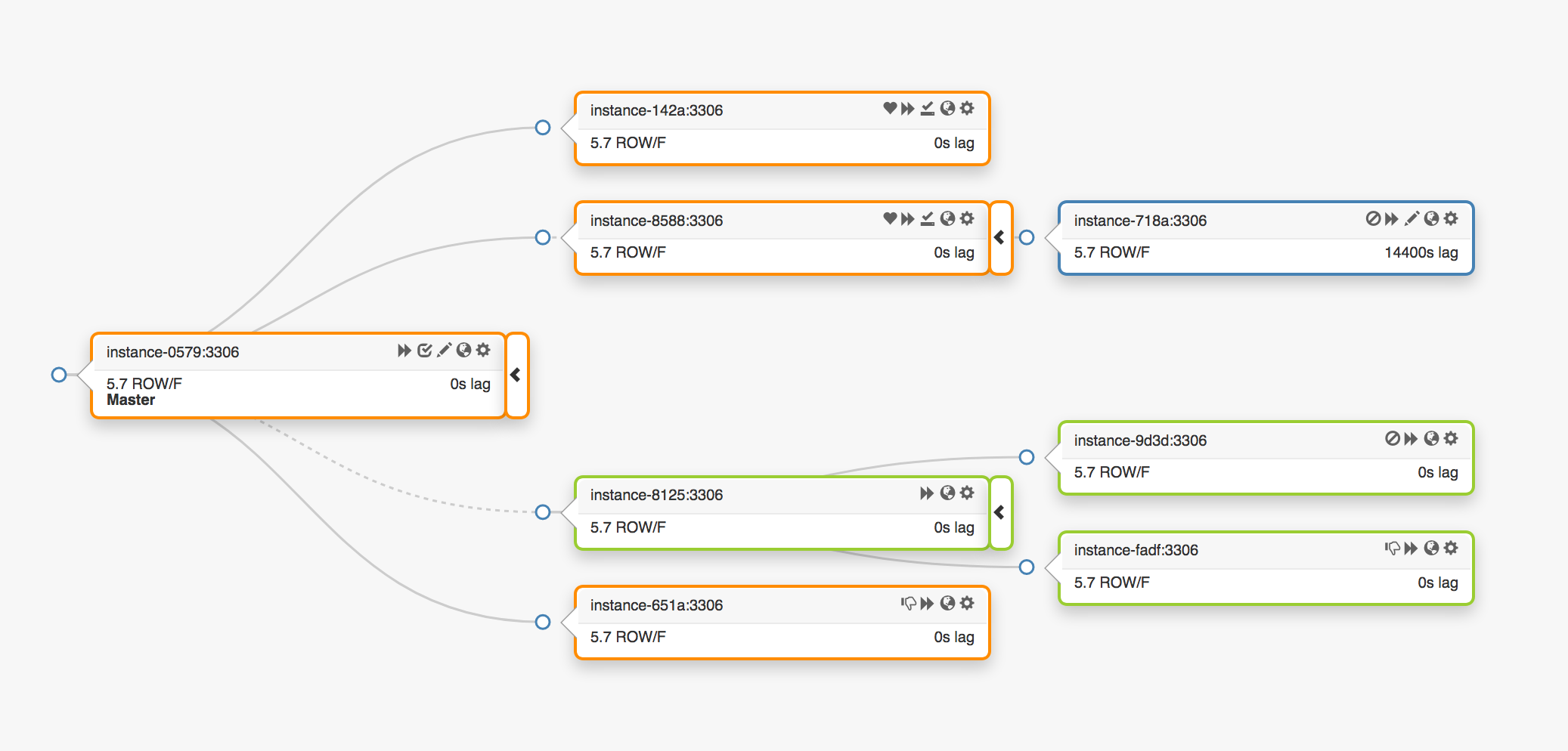
メインノードに障害が発生した場合、新しいサーバーをその場所(レプリカの1つ)に割り当てる必要があります。
orchestrator
は障害を検出し、新しいマスターノードを選択して、名前/ VIPを割り当てます。 クライアントは実際にはメインノードのIDを知らず、名前だけを知っています。名前は新しいノードを指しているはずです。 ただし、これに注意してください。
VIPアドレスは共有され、データベースサーバー自体が要求して所有します。 VIPを受信または解放するには、サーバーはARP要求を送信する必要があります。 VIPを所有するサーバーは、新しいホストがこのアドレスにアクセスする前に、まずVIPを解放する必要があります。 このアプローチは、いくつかの望ましくない結果につながります。
- 通常モードでは、フェールオーバーシステムはまず障害が発生したメインノードに接続し、VIPを解放するように要求してから、VIPの割り当てを要求する新しいメインサーバーに切り替えます。 しかし、最初のメインノードが使用できない場合、またはVIPアドレスを解放する要求を拒否した場合はどうすればよいでしょうか? サーバーが現在障害状態にあることを考えると、時間内に要求に応答できるか、まったく応答できない可能性はほとんどありません。
- その結果、2人のホストが同じVIPに対する権利を主張する状況が発生する場合があります。 最短のネットワークパスに応じて、さまざまなクライアントがこれらのサーバーのいずれかに接続できます。
- この状況での正しい操作は、2つの独立したサーバーの相互作用に依存し、そのような構成は信頼できません。
- 最初のメインノードがリクエストに応答しても、貴重な時間を無駄にします。古いメインサーバーに接続している間は、新しいメインサーバーへの切り替えは発生しません。
- 同時に、VIPの再割り当ての場合でも、古いサーバー上の既存のクライアント接続が切断されるという保証はありません。 ここでも、2つの独立したメインノードがある状況に陥るリスクがあります。
環境内の一部の場所では、VIPアドレスは物理的な場所に関連付けられています。 それらはスイッチまたはルーターに割り当てられます。 そのため、元のホストと同じ環境にあるサーバーにのみVIPアドレスを再割り当てできます。 特に、場合によっては、別のデータセンターのVIPサーバーを割り当てることができず、DNSを変更する必要があります。
- DNSへの変更の配布には時間がかかります。 クライアントは、事前定義された期間DNS名を保存します。 複数のデータセンターを含むフェールオーバーでは、すべての顧客に新しいメインノードに関する情報を提供するのに時間がかかるため、ダウンタイムが長くなります。
これらの制限は、新しいソリューションの検索を開始するように強制するのに十分でしたが、次のことも考慮する必要がありました。
- メインノードは、遅延と負荷調整を測定するために 、
pt-heartbeat
を介してパルスパケットを個別に送信しました。 サービスは、新しく指定されたメインノードに転送する必要がありました。 可能であれば、古いサーバーで無効にしておく必要があります。 - 同様に、メインノードはPseudo-GTIDの動作を独立して制御しました 。 新しいメインノードでこのプロセスを開始し、できれば古いメインノードで停止する必要がありました。
- 新しいマスターノードが書き込み可能になりました。 古いノード(可能な場合)には
read_only
(読み取り専用)が必要です。
これらの追加手順により、全体的なダウンタイムが増加し、独自の障害点と問題点が追加されました。
ソリューションは機能し、GitHubはバックグラウンドでMySQLクラッシュを正常に処理しましたが、HAへのアプローチを次のように改善したかったのです。
- 特定のデータセンターからの独立性を確保します。
- データセンターに障害が発生した場合の操作性を保証します。
- 信頼性の低い共同作業のワークフローを放棄する
- 総ダウンタイムを短縮します。
- 可能な限り、フェイルオーバーを損失なく実行します。
GitHub HAソリューション:オーケストレーター、Consul、GLB
新しい戦略とそれに伴う改善により、上記の問題のほとんどが解消されるか、結果が緩和されます。 現在のHAシステムは、次の要素で構成されています。
- 障害検出およびフェイルオーバーのためのオーケストレーター 。 次の図に示すように、 オーケストレーター/ラフトスキームをいくつかのデータセンターで使用します。
- Hashicorp Consul for service discovery;
- クライアントとレコーディングノード間のプロキシレイヤーとしてのGLB / HAProxy 。 GLBディレクターのソースコードは公開されています。
- ネットワークルーティング用の
anycast
テクノロジー。
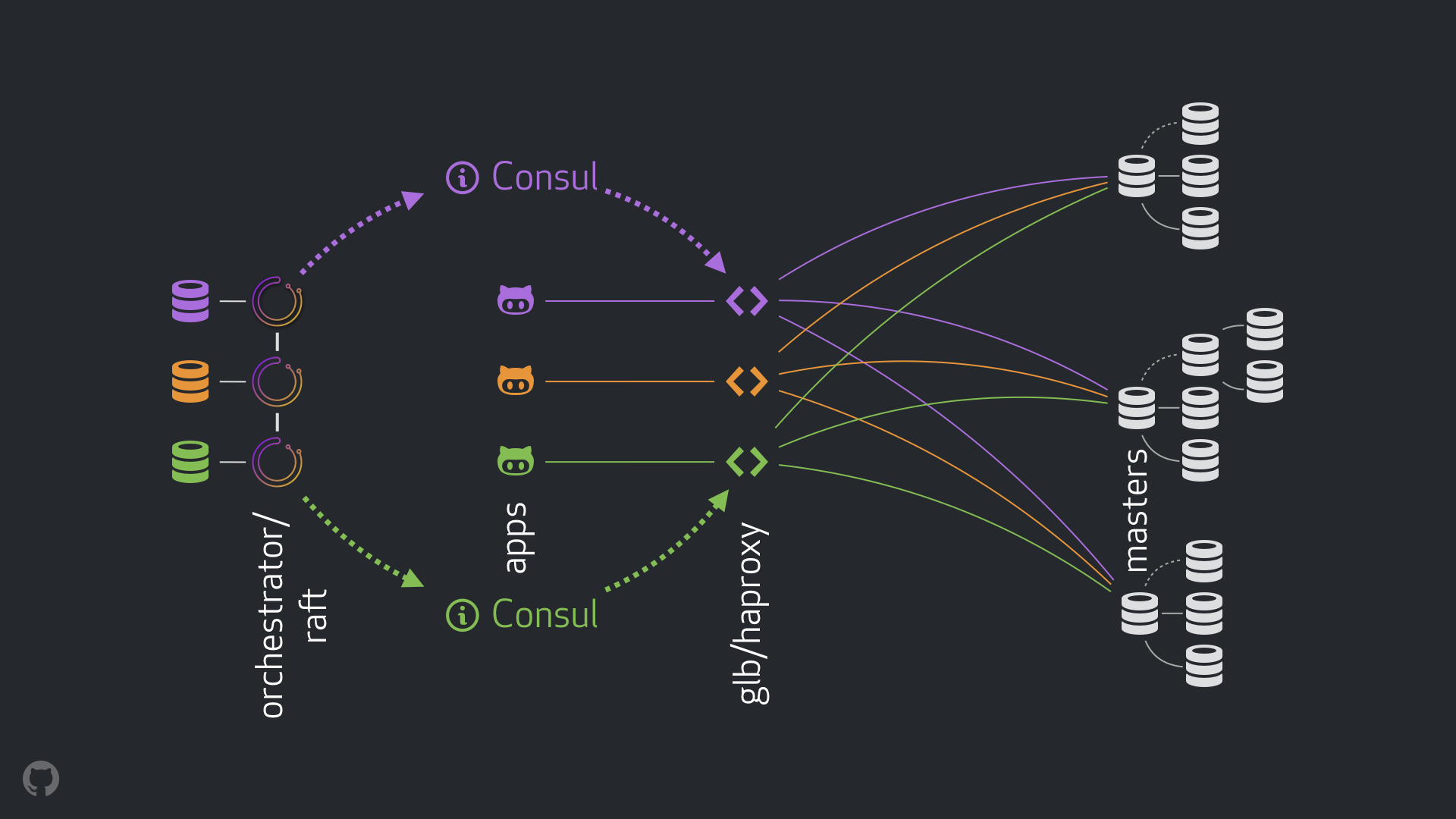
新しいスキームにより、VIPとDNSの変更を完全に放棄することができました。 これで、新しいコンポーネントを導入するときに、それらを分離してタスクを簡素化できます。 さらに、信頼できる安定したソリューションを使用する機会を得ました。 新しいソリューションの詳細な分析を以下に示します。
通常の流れ
通常の状況では、アプリケーションはGLB / HAProxyを介して記録ノードに接続します。
アプリケーションはメインサーバーのIDを受け取りません。 前と同じように、名前のみを使用します。 たとえば、 cluster1
のメインノードはmysql-writer-1.github.net
です。 ただし、現在の構成では、この名前はエニーキャスト IPアドレスに解決されます。
anycast
技術のおかげで、名前はどこでも同じIPアドレスに解決されますが、クライアントの場所を考慮すると、トラフィックの方向は異なります。 特に、可用性の高いロードバランサーであるGLBの複数のインスタンスが各データセンターに展開されています。 mysql-writer-1.github.net
常にローカルデータセンターのGLBクラスターにルーティングされます。 このため、すべてのクライアントはローカルプロキシによって処理されます。
HAProxyの上でGLBを実行します。 HAProxyサーバーは、各MySQLクラスターに1つずつ、 書き込みプールを提供します。 また、各プールには1つのサーバー(クラスターのメインノード)のみがあります。 すべてのデータセンターのすべてのGLB / HAProxyインスタンスには同じプールがあり、それらはすべてこれらのプールの同じサーバーを指します。 したがって、アプリケーションがmysql-writer-1.github.net
のデータベースにデータを書き込む場合、どのGLBサーバーに接続するかは重要ではありません。 どちらの場合でも、実際のメインクラスターノードcluster1
へのリダイレクトが実行されます。
アプリケーションの場合、ディスカバリーはGLBで終了し、再ディスカバリーは不要です。 そのGLBはトラフィックを適切な場所にリダイレクトします。
GLBは、リストするサーバーに関する情報をどこで取得しますか? GLBをどのように変更しますか?
領事による発見
Consulサービスは、サービスディスカバリソリューションとして広く知られ、DNS機能も引き受けます。 ただし、この例では、非常にアクセスしやすいキー値(KV)のストレージとして使用します。
ConsulのKVリポジトリに、クラスターのメインノードのIDを記録します。 各クラスターには、対応するメインノードのデータを指すKVレコードのセットがあります:そのfqdn
、ポート、ipv4およびipv6アドレス。
各GLB / HAProxyノードは、Consulデータの変更を追跡するサービスであるconsul-templateを起動します(この場合、これらはメインノードのデータの変更です)。 consul-template
は設定ファイルを作成し、設定を変更するときにHAProxyをリロードできます。
このため、ConsulのメインノードのIDの変更に関する情報は、各GLB / HAProxyインスタンスで利用できます。 この情報に基づいて、インスタンスの構成が実行され、新しいメインノードがクラスターサーバープール内の唯一のエンティティとして示されます。 その後、インスタンスが再ロードされ、変更が有効になります。
各データセンターにConsulインスタンスを展開しており、各インスタンスは高可用性を提供します。 ただし、これらのインスタンスは互いに独立しています。 それらは複製せず、データを交換しません。
Consulは変更に関する情報をどこで入手し、データセンター間でどのように配布しますか?
オーケストレーター/いかだ
orchestrator/raft
スキームを使用します。 orchestrator
ノードは、 ラフトコンセンサスを通じて互いに通信します。 各データセンターには、1つまたは2つのorchestrator
ノードがあります。
orchestrator
は、障害の検出、MySQLフェールオーバー、および変更されたマスターノードデータのConsulへの転送を担当します。 フェールオーバーは単一のorchestrator/raft
ホストによって管理されますが、クラスターが新しいマスターになったことをorchestrator/raft
変更は、 raft
メカニズムを使用してすべてのorchestrator
ノードに伝達されます。
orchestrator
ノードがメインノードのデータの変更に関するニュースを受信すると、各ノードはConsulのローカルインスタンスにアクセスし、KV記録を開始します。 orchestrator
複数のインスタンスを持つデータセンターは、Consulで複数の(同一の)レコードを受け取ります。
ストリーム全体の一般的なビュー
マスターノードに障害が発生した場合:
-
orchestrator
ノードは障害を検出します。 -
orchestrator/raft
マスターが回復を開始します。 新しいマスターノードが割り当てられます。 -
orchestrator/raft
スキームは、メインノードの変更に関するデータをraft
クラスターのすべてのノードに転送します。 - 各
orchestrator/raft
インスタンスはノードの変更に関する通知を受け取り、ConsulのローカルKVストレージに新しいマスターノードのIDを書き込みます。 - 各GLB / HAProxyインスタンスで、
consul-template
サービスが起動され、ConsulのKVリポジトリの変更を監視し、HAProxyを再構成して再起動します。 - クライアントトラフィックは新しいマスターノードにリダイレクトされます。
コンポーネントごとに、責任が明確に分散され、構造全体が多様化および簡素化されます。 orchestrator
はロードバランサーと対話しません。 領事は、情報の出所についての情報を必要としません。 プロキシサーバーはConsulでのみ動作します。 クライアントはプロキシのみで動作します。
さらに:
- DNSに変更を加えて、それらに関する情報を広める必要はありません。
- TTLは使用されません。
- スレッドは、エラー状態のホストからの応答を待機しません。 一般に、それは無視されます。
追加情報
流れを安定させるために、次の方法も適用します。
- HAProxy
hard-stop-after
パラメーターは非常に小さな値に設定されます。 書き込みプール内の新しいサーバーでHAProxyが再起動すると、サーバーは古いマスターノードへの既存の接続をすべて自動的に終了します。
-
hard-stop-after
パラメーターを設定すると、クライアントからのアクションを待たずに済みます。さらに、クラスター内で2つのメインノードが発生する可能性のある負の結果が最小限に抑えられます。 ここには魔法がないことを理解することが重要です。いずれにせよ、古い関係が壊れるまでに時間がかかります。 しかし、不快な驚きを待つのをやめることができる時点があります。
-
- Consulサービスの継続的な可用性は必要ありません。 実際、フェイルオーバー中にのみ使用可能にする必要があります。 Consulサービスが応答しない場合、GLBは最新の既知の値で引き続き動作し、抜本的な対策を講じません。
- GLBは、新しく割り当てられたマスターノードのIDを確認するように構成されています。 状況依存のMySQLプールと同様に、サーバーが実際に書き込み可能であることを確認するためにチェックが実行されます。 ConsulでメインノードのIDを誤って削除した場合、問題はなく、空のレコードは無視されます。 誤って別のサーバー(メインサーバーではない)の名前をConsulに書き込んだ場合、この場合は問題ありません。GLBはそれを更新せず、最後の有効な状態で引き続き動作します。
次のセクションでは、問題を検討し、高可用性の目標を分析します。
オーケストレーター/ラフトによるクラッシュ検出
orchestrator
は、障害検出に包括的なアプローチを採用しているため、ツールの高い信頼性が保証されます。 誤検知の結果は発生せず、早期の障害は実行されません。つまり、不必要なダウンタイムが排除されます。
orchestrator/raft
スキームは、データセンターの完全なネットワーク分離の状況も処理します(データセンターの「フェンス」)。 データセンターのネットワーク分離は混乱を引き起こす可能性があります。データセンター内のサーバーは互いに通信できます。 特定のデータセンターまたは他のすべてのデータセンター内のサーバー-本当に孤立している人を理解する方法は?
orchestrator/raft
スキームでは、 orchestrator/raft
マスターはフェールオーバーです。 ノードがリーダーになり、グループ内の多数派(クォーラム)のサポートを受けます。 orchestrator
ノードは、単一のデータセンターでは過半数を提供できず、 n-1
データセンターでは提供できるような方法で展開しました。
データセンターの完全なネットワーク分離の場合、このセンターのorchestrator
ノードは他のデータセンターの同様のノードから切断されます。 その結果、隔離されたデータセンターのorchestrator
ノードは、 raft
クラスターの先頭に立つことはできません。 そのようなノードがマスターの場合、このステータスは失われます。 新しいホストには、他のデータセンターのノードの1つが割り当てられます。 このリーダーは、相互にやり取りできる他のすべてのデータセンターをサポートします。
この方法では、 orchestrator
マスターは常にネットワーク分離されたデータセンターの外部にあります。 マスターノードが分離されたデータセンターにある場合、 orchestrator
はフェールオーバーを開始して、使用可能なデータセンターのいずれかのサーバーに置き換えます。 利用可能なデータセンターの定足数に決定を委任することにより、データセンターの分離の影響を軽減します。
より迅速な通知
メインノードの変更通知を高速化することにより、合計ダウンタイムをさらに短縮できます。 これを達成する方法は?
orchestrator
がフェイルオーバーを開始すると、サーバーのグループが考慮され、そのうちの1つをメインのサーバーとして割り当てることができます。 レプリケーションルール、推奨事項、および制限事項を考慮して、彼は最適な行動方針について情報に基づいた決定を下すことができます。
次の兆候によれば、彼はアクセス可能なサーバーがメインのアポイントメントの理想的な候補であることも理解できます。
- サーバーが昇格するのを妨げるものは何もありません(そして、おそらくユーザーはこのサーバーを推奨します)。
- サーバーが他のすべてのサーバーをレプリカとして使用できることが期待されます。
この場合、 orchestrator
まずサーバーを書き込み可能として構成し、そのステータスの増加をすぐに通知します(この場合、レコードをConsulのKVリポジトリに書き込みます)。 orchestrator , .
, , GLB , , . : !
, . , , . , , , .
: 500
. . ( ), .
( ) . , .
, / pt-heartbeat
/ , . , pt-heartbeat
, read_only
, .
pt-heartbeat
, . . . , pt-heartbeat
.
orchestrator
orchestrator :
- Pseudo-GTID;
- , ;
- (
read_only
), .
, . , , , . orchestrator
.
- , , . , -, .
, .
, , , - . . STONITH . , , , «» - . , , .
: Consul , . . , , , , .
結果
orchestrator/GLB/Consul :
- ;
- ;
- ;
- ;
- , ( );
- ;
-
10-13
.
-
20
, —25
.
-
おわりに
«// » , , . . , .