それで、私たちは何について話しているのでしょう。 ベクトルから1つのランダムな要素を選択することは基本的なタスクです。
// C++ std::random_device rd; std::mt19937 gen(rd()); std::uniform_int_distribution<> dis(0, vect.size() — 1); auto result = vect[dis(gen)];
「サイズNのベクトルからK個のランダム要素を返す」というタスクは、すでに複雑です。 ここで、あなたはすでに間違いを犯すことができます-例えば、最初のK個の要素を取る(これはランダム性の要件に違反します)または確率K / Nで各要素を取る(これは正確にK個の要素を取る要件に違反します) さらに、形式的には正しいが、非常に効果のないソリューション「すべての要素をランダムに混合し、最初にKを取得する」ことも可能です。 そして、Nが非常に大きい数(N個の要素すべてを保存するのに十分なメモリがない)および/または事前にわからないという条件を追加すると、すべてがさらに興味深いものになります。 たとえば、1つずつ要素を送信する何らかの外部サービスがあるとします。 それらがどれだけ入ってくるかはわかりませんし、すべてを保存することはできませんが、任意の時点で受け取った要素から正確にK個のランダムに選択された要素のセットが必要です。
リザーバーサンプリングアルゴリズムを使用すると、O(N)ステップとO(K)メモリでこの問題を解決できます。 この場合、事前にNを知る必要はなく、正確にK個の要素のランダムサンプリングの条件が明確に観察されます。
単純化されたタスクから始めましょう。
K = 1、つまり すべての着信要素から要素を1つだけ選択する必要がありますが、着信要素のそれぞれが同じ確率で選択されるようにします。 アルゴリズムはそれ自身を提案します:
ステップ1 :メモリを1つの要素のみに割り当てます。 到着した最初の要素を保存します。

これまでのところ、すべてが大丈夫です-100%の確率で(現時点では)選択されるべき要素が1つしかありません-それはそうです。
ステップ2 :2番目の着信要素は、選択された要素の1/2の確率で書き換えられます。

ここでも、すべてが問題ありません。これまでのところ、たった2つの要素が到着しています。 最初は1/2の確率で選択されたままで、2番目は1/2の確率でそれを上書きします。
ステップ3 :3番目の着信要素は、選択されたものとして1/3の確率で書き換えられます。
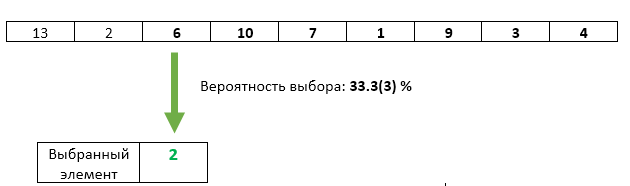
3番目の要素はすべて問題ありません。選択される可能性は正確に1/3です。 しかし、私たちは以前の要素の平等な機会に何らかの形で違反しましたか? いや 選択したアイテムがこのステップで上書きされない確率は、1-1/3 = 2/3です。 また、ステップ2で各要素を選択する機会が等しいことを保証しているため、ステップ3の後、各要素を2/3 * 1/2 = 1/3の機会で選択できます。 3番目の要素とまったく同じチャンス。
ステップN :1 / Nの確率で、要素番号Nが選択されたものとして書き換えられます。 到着した以前の各アイテムには、選択されたままになる1 / Nのチャンスがあります。
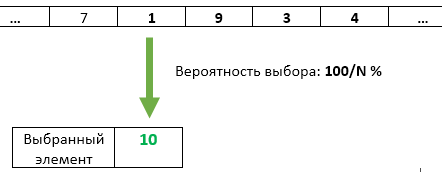
しかし、K = 1の単純化されたタスクでした。
K> 1の場合、アルゴリズムはどのように変わりますか?
ステップ1 :K個の要素にメモリを割り当てます。 到着した最初のK個の要素を書き込みます。

K個の到着した要素からK個の要素を取得する唯一の方法は、それらすべてを取得することです:)
ステップN :(各N> Kに対して):1からNまでの乱数Xを生成します。X> Kの場合、この要素を破棄して次へ進みます。 X <= Kの場合、要素を数値Xで書き換えます。Xの値は1〜Nの範囲で一様にランダムになるため、X <= Kの条件下では1〜Kの範囲で一様にランダムになります。書き換え可能なアイテムの選択。

あなたが見ることができるように-来るすべての次の要素は、選択される可能性がますます少なくなっています。 それにもかかわらず、それは常に正確にK / Nになります(以前に到着した各要素について)。
このアルゴリズムの利点は、いつでも停止し、ユーザーに現在のベクトルKを表示できることです。これは、到着した要素のシーケンスから正直に選択されたランダム要素のベクトルになります。 おそらく、これはユーザーに適しているか、または入力値の処理を継続したいでしょう。これはいつでも実行できます。 この場合、冒頭で述べたように、O(K)メモリ以上を使用することはありません。
そうそう、完全に忘れてしまった、 std ::サンプル関数は、上記で説明したことを正確に実行し、最終的に標準C ++ 17ライブラリに含まれています。 標準では、リザーバーサンプリングのみを使用することは義務付けられていませんが、O(N)ステップで動作することが義務付けられています-標準ライブラリでの実装の開発者は、O(K)より多くのメモリを使用するアルゴリズムを選択することはほとんどありません-結果はどこかに保存する必要があります)。
関連資料
- Facebook開発者は、内部コードベースを使用した検索エンジンでのリザーバーサンプリングの使用方法について報告しています(34分から)。
- ウィキペディアの記事
- std :: cppreferenceのサンプル