
最近、顧客からディスク容量アカウンティングシステムの実装を依頼されました。 タスクは、SANスイッチとVMware ESXホストからのさまざまなベンダーの70以上のディスクアレイからの情報を結合することでした。 次に、データをシステム化、分析し、ダッシュボードおよびさまざまなレポートに表示できるようにする必要がありました。たとえば、すべてまたは個別に取得したアレイの空きディスク容量と占有ディスク容量についてです。
運用分析システム-Splunkを使用してプロジェクトを実装することにしました。
なぜ割れますか?
Splunkは、収集したデータを視覚化するのに強力です。 インタラクティブなレポート-ダッシュボード-をリアルタイムで更新して作成できます。 それらの合計ディスク容量に関する情報を表示し、容量などの異なるフィルターでソートできるすべてのアレイをすぐに表示しました。 配列をクリックすると、すべての接続に関する情報がすぐに取得されます。 別のパネルで、仮想マシンの名前を入力し、どのESXホストが存在するか、どのアレイからデータやその他のパラメーターを受信するかを確認できます。
私の意見では、これまでのところ、Splunkにはすぐに使用できるストレージシステムで動作するアナログはありません。 数年前、有料のCommandCentralが登場しましたが、必要な柔軟性がなく、任意のレポートを生成する方法がわかりません(レポートの最初のバージョンではまったくありませんでした)。 一般に、これはインベントリ用のツールではなく、システムのステータスを監視および制御するためのツールです。 顧客が設定したタスクを実行するには、修正に時間がかかり、費用がかかります。
同時に、Splunkには優れた情報表示機能があります。グラフを相互に自由に配置し、すべてのシステムのステータスを単一ウィンドウモードで監視し、メンテナンスを簡素化できます。 他のすべてに-私たちのタスクでは、無料版を使用しました。

あなたは何をしましたか?
この時点まで、Splunkのチームには経験がありませんでした。 幸いなことに、このシステムは使いやすく直感的であることが判明し、新たな問題の解決策は、通常のヘルプまたは検索エンジンを使用して簡単に見つかりました。
Splunkは、必要な多くのツールを構築しました。 たとえば、システムでは、いわゆるルックアップ(ディレクトリ)を使用して、任意のフィールドのさまざまなソースからのデータを組み合わせることができます。 したがって、あるテーブルでは、ESXホストはIPとして表示され、別のテーブルではDNS名として表示されました。 最初は、自作のLookupを作成し、nslookupユーティリティを使用してDNSレコードを選択し、テーブルを収集したかったのですが、SplunkにはDNSをIPとIPで比較するディレクトリがあることがわかりました。 このビルトインルックアップは設定する必要がなく、システム設定からDNSサーバーに関するデータを抽出します。WindowsまたはLinuxであるかどうかは関係なく、DNSレコードのデータは常に最新です。

Splunkで実装される興味深いシナリオの1つは、システムの変更管理(RFC)です。 たとえば、RFCマネージャーは、エンジニアからSANスイッチの1つをサービスする要求を受け取ります。 彼はSplunkにスイッチ名を入力し、どのストレージがそれに接続されているか、どのサーバーがこれらのストレージからデータを受信するかを確認します。 同時に、マネージャーはエンジニアが作成した作業計画を確認し、メンテナンス中にこのスイッチを無効にするとアレイとサーバーのパフォーマンスにどのように影響するかを評価できます。
すべてのスイッチとアレイをSplunkに接続することに関する情報の毎日の読み込みを設定します。 顧客はこのようなリフレッシュレートに満足しています。 彼はすでに監視ツールStor2RRDを持っていましたが、異なるソースからのデータを結合して視覚化する方法を知りません。 したがって、Splunkのデータ収集システムを次のように構成しました。
- Stor2RRDからストレージに関する情報を受け取ります。
- スイッチからSANに関する情報を受け取ります。
- PowerCLIスクリプトを使用したvCenterを通じて、ESXホストからデータを収集します。
受信したデータは自動的に単一の形式になり、必要なレポートの形式で処理および表示されます。
何と戦わなければなりませんでしたか?
Splunkは強力なシステムですが、すぐに解決できないタスクがあり、一部のタスクにはVMwareの詳細な知識が必要です。
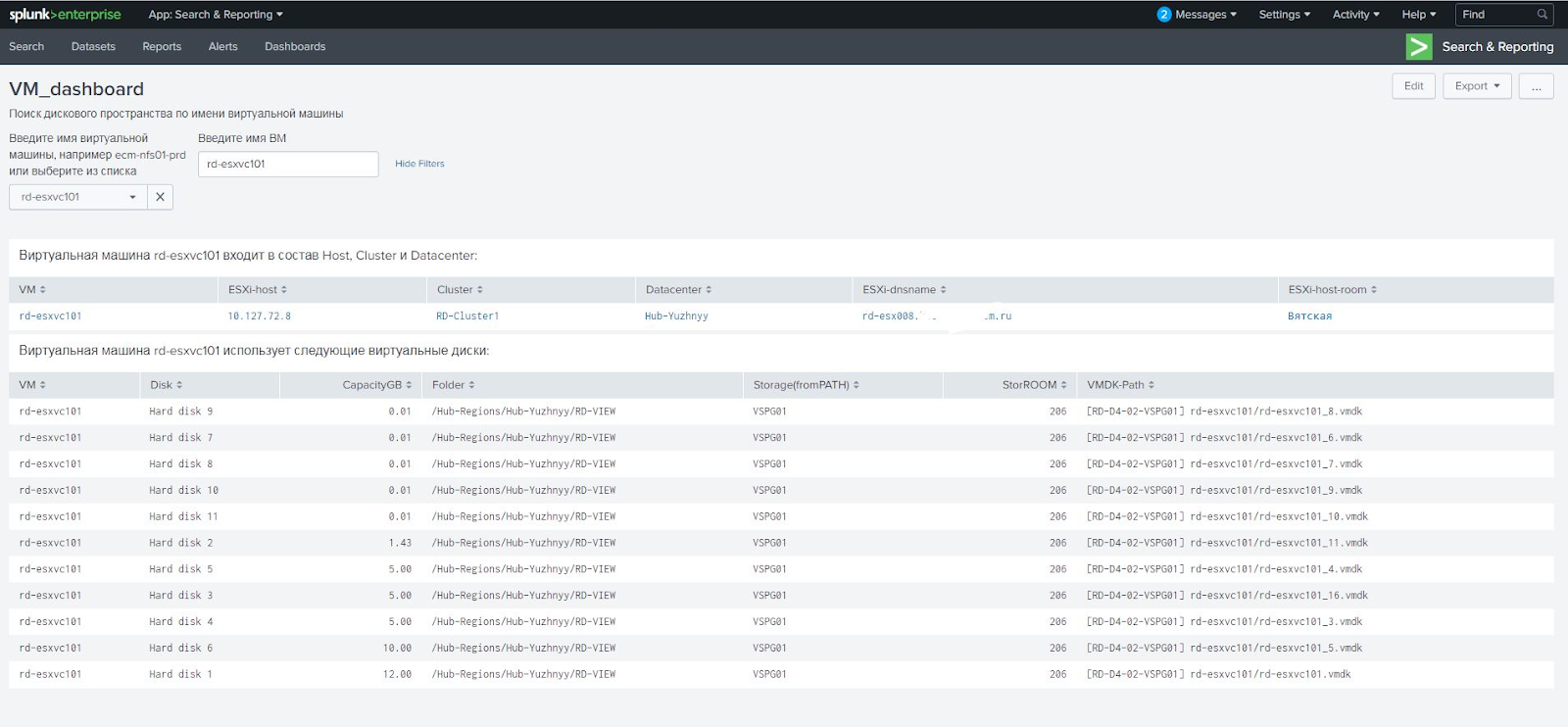
たとえば、顧客は、仮想マシンに直接割り当てられたRDMディスクと仮想仮想データストアの両方を使用します。 これら2つのタイプのドライブは、異なる方法で処理する必要があります。 最初は自分で問題を解決しましたが、仮想マシンがRAWディスクと仮想ディスクの両方を受信するという状況に遭遇しました。 vCenterからレポートの間違ったパスフィールドとRAWディスクアレイへの誤ったリンクを取得していることが判明しました。 このスキームは通常のデータストアで機能しますが、RAWディスクでは機能しません。 それらの場合、ディスク属性を含むRAWディスクIDディスクプロパティを使用する必要があります。 RAWディスクIDを介して正しいアレイを計算するために、スクリプトを再編集したVMwareの専門家に頼らなければなりませんでした。
また、PowerCLIスクリプトを最適に使用する方法をすぐには学習しませんでした。後でアルゴリズムをさらに開発する必要がありました。 当初、スクリプトは数千の仮想マシンからのデータを3時間も処理していました! 改良後、スクリプトの期間は40分に短縮されました。
結果は何ですか?
Splunkの経験がなかったため、多数のソースから情報を受け取り、それを統合し、広範囲の便利で視覚的なチャートを提供するディスク容量を記録するシステムをすぐに実装しました。 そのようなシステムを以前に選択または作成する必要がなかった場合、Splunkはこの役割の有力な候補です。 迅速に機能し、簡単かつ柔軟に構成され、ほとんどの問題を解決するための専門知識は必要ありません。
Vladislav Semenov、Jet Infosystems、コンピューティングコンプレックス設計センター、システムアーキテクチャグループ長