
通常、開発者向けの企業ナレッジベースには問題があります。責任者やソビエトのアパートの物で満たされたバルコニーのいずれかでそれを埋める動機がないため、それは無効になります、誰もが貢献しますが、彼らはランダムに書き込み、情報はすぐに古くなり、常に更新する時間がありません。
これを回避する方法、または少なくとも可能なコストを削減する方法は? あなたの企業基盤を暖かくしてランプにする方法は? 答えようとします。
コラボレーションスタイルのドキュメント
そのようなアプローチ、共同文書があり、診断の決定が患者と数人の医師によって集合的に行われるときに、もともと医学の分野に現れました。
IT分野の鮮やかな例としては、Google Docs、Wiki、Github、内部規約があり、プロジェクトで一緒に作業できる可能性があるシステムがあります。
アイデアは、開発者、専門家、批評家をできるだけ早くドキュメントの作業に含め、ギャップを特定することです。
なぜこれが必要なのでしょうか?

まず、バス要素を減らすことは、企業の知識のボトルネックであり、知識保有者の数が一致する傾向があります。 そのような知識を開発者の頭から、ホワイトボード、チケット、キッチンでの会話から単一のスペースに移して、誰もが一緒に作業して貢献できるようにする必要があります。
第二に、新規参入者のプロジェクトへの参入を簡素化するため、これは分散チームおよび特定数のアウトソーシング開発者を抱えるチームにとって非常に重要であり、非常に特定の事業領域を持つ企業にとっても、既製のスペシャリストを見つけるチャンスはゼロです。
第三に、健全な企業文化の形成のために、「言葉ではなく」透明性。 そのような環境の開発者は、専門的な成長のポイント、会社で他に試すことができる技術、学ぶべきことを明確に理解しています。
どうする?
企業のナレッジベース内のドキュメントは、チームのどのメンバーでも作成できます。チームにとっては、この機会を簡素化する必要があり、結果の所有者のように感じます。
ただし、情報アーキテクトの機能を引き受ける人が必ず必要です。統一されたルール、構造、ロジック、スタイルを設定し、ドキュメントをスペースに正しく配置してください。
以前にゲームのルールに同意した上で、チームメンバーに対してドキュメントの編集および作成の可能性を開きます。 これらのルールを最大限に自動化する-チームに依存せず、テンプレートを作成し、タグでコンテンツを自動的にタグ付けし、リポジトリからナレッジベースへのアップロードを構成します(これについては別の記事を作成します)。

開発者は、企業のWikiのドキュメントが消滅しないことを確認することが重要です。 重要な原則:内部ドキュメントの完了の定義、これは修正またはコメントが作成された瞬間 、つまり、実際にはコラボレーションの瞬間です。 これはその価値であり、彼らはそれに時間を費やすことを望んでいます。 補足しない-それは、配信プロセス、検索の実装がうまく編成されていない、またはツールが不便であることを意味します。

このアプローチの潜在的な問題は、雪だるまとしての編集とコメントの蓄積であり、それを追跡することは困難であり、多くの場合、複製文書が作成されます。
これを防ぐために、次のことができます。A.チームをベクター、ルールセットに設定し、それらに従わないプロセスを複雑にします(たとえば、Confluenceでは、[作成]ボタンを非表示にし、テンプレートの選択を必須にします)。 B.情報アーキテクチャを担当する人にとっては、権利を制限し、編集プロセスを便利に設定するのが便利です。
そして、完璧な世界が来る
ネタバレ
いや
開発者は、愚かな繰り返しの質問など、お互いに質問することをやめません 。 彼らは知識ベースですべての答えを自分で見つけることを学びません。 Confluenceの検索インデックスの制限により、開発者が何かを見つけることができず、情報アーキテクトとして私に尋ねると、ユーモアがあります。 これをSvetaベースの検索と呼びます。
これらの制限、ナレッジベース自体の構造、ページの統一された命名、ラベルの使用は、たとえば、頻繁に繰り返される質問に答えないように、ナレッジを検索して作成するよう刺激します。
私たちが使用したもう1つのライフハックは、ドキュメントにビジネスコンテキストを常に含めることです。たとえそれがライブラリまたはクラスの説明またはタスクのチェックリストであっても、これがクライアントにとって何を意味するかを理解することは重要です。
練習する
次のパートでは、「どのように」、Confluenceの内部機能(はい、Atlassianスタックを使用)を使用してこれらの原則を実装できます。
パターン
技術仕様、ハウツー、チェックリストなど、最も頻繁に作成するさまざまな種類のドキュメント用の既製のテンプレートを作成しました。 これらは、管理スペースパネルで設定できます。 開発者がドキュメントを作成するときに空白ページが表示されないように、テンプレートが必要です。開発者はこのセクションまたはそのセクションに何を書くかについての指示を既に持っています。 特定のタイプのドキュメントを1つのセクションに分類し、メタ情報を表示する場合(これは、たとえば、1つのスキームに従って複雑な製品またはマイクロサービスのセットのコンポーネントを記述するのに便利です)、ブループリントを作成します。これは、最高速度のテンプレートのようなものです。
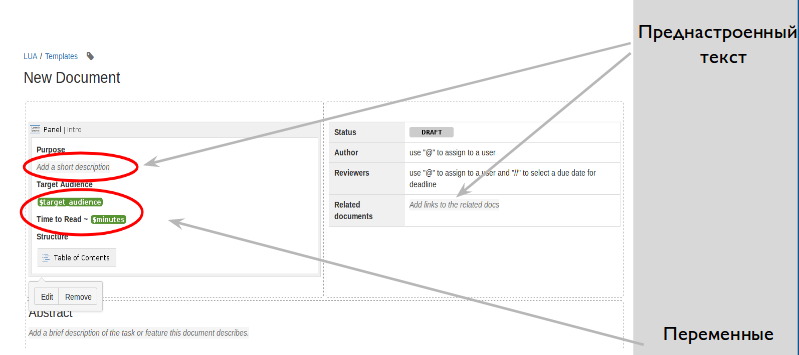
それらでは、ページレイアウト、見出しを設定します。ここでは、いくつかの単語、ステータス付きのヘッダー、画像、表、コードブロック、さらには変数を置き換えるだけです。
変数は、後続のドキュメントエディタが重要度を設定する必要がある事前設定されたコンテンツ要素です。たとえば、テキストを入力したり、リストから選択したりします。
事前にテンプレートにタグを追加することもできます。テンプレートが狭いタイプの場合、たとえば、ステートメント、Jiraマクロによる明確な名前付きワークフローがある場合、ユーザーをレビューアとして言及し、Jiraからチケットを添付できます。 私たちの経験では、タスクの最大80%がテンプレートでカバーできることが示されています。
ページレイアウト
もう1つの重要な要素は、チームスペースにわかりやすく美しいランディングページを作成することです。 これを行うには、ページレイアウトとマクロパネル、列、およびセクションを使用します。
以下は、開発チームのスペースの一例です。

わかりやすいページ名を使用してください。 ご存知かもしれませんが、Confluenceは同じスペース内で同一のページ名をサポートしていません。 次のような明確なページ名を維持してください
悪名の Python
社内サービスチーム向けの適切なPythonスタイルガイド
ラベル
Confluenceには、コンテンツのインデックス作成に関連する検索アルゴリズムにいくつかの制限があります。 そして、企業のナレッジベースにとって、最も差し迫った問題であるのは、まさに発見とつながりです。 ナレッジベースには「Confluence検索を克服する方法」という記事があります。必要に応じて、コメントで共有します。

これらの制限を克服するために、ラベルシステムを使用します。 実際、これらはコンテンツの主題をマークするタグであり、特定の主題のコンテンツをある種のRSSフィード(ラベル別マクロコンテンツ)の形式で1か所に集約できる理由です。 したがって、サブジェクトインデックスを構成しました。
データベースにすでに数百のページがある場合は、次の演習から始めることをお勧めします。
- https:// <my-host-name> /labels/listlabels-alphaview.actionというURLですべてのラベルのリストを参照してください。
- 高度な検索文字列でラベルが付いていないすべてのコンテンツを検索します:type:page NOT labelText:[a TO z] NOT labelText:[0 TO 9]。
あなたは今何をして何ができますか?
- 開発者に編集する権利を与えますが、賢明です。
- コマンドスペースの構造について考え、便利なランディングページを作成します。
- テンプレートをカスタマイズします。
- ラベルを使用します。
- 他の人のドキュメントに移動して編集するか、コメントを書いて、このドキュメントを機能させます。