Velocityは、分散システム専用の会議です。 オライリーが主催し、年に3回開催されます。カリフォルニアで1回、ニューヨークで1回、ヨーロッパで1回です(都市は毎年変わります)。
2018年、会議は10月30日から11月2日までロンドンで開催されました。 Badooのメインオフィスはそこにあるため、同僚と私はVelocityに行く2つの理由がありました。
彼女のデバイスは、ロシアの会議で出会ったデバイスよりもやや複雑であることが判明しました。 通常の2日間のプレゼンテーションに加えて、さらに2日間のトレーニングがありました。トレーニングは全部、一部、またはまったく受けられません。 一緒に、これは必要なチケットの種類を選択するための真剣な探求に変わります。
このレビューでは、覚えているこれらのレポートとマスタークラスについてお話します。 一部のレポートに追加資料へのリンクを添付します。 部分的に、これらは著者が言及した資料であり、一部はさらなる研究のための資料であり、私は自分自身を見つけました。
会議の一般的な印象:著者のパフォーマンスは非常に良好です(そして、基調講演セッションは、スピーカーが音楽に合わせてステージに上がって行くというショー全体です)が、同時に技術的な観点から深いレポートがいくつかありました。
この会議で最もホットなトピックはKubernetesで 、これはほぼ2番目のレポートで言及されています。
ソーシャルネットワークでの作業は非常にうまく構築されています。会議中の公式twitterアカウントには、レポートを含む多くの運用上のリツイートがありました。 これにより、他の部屋で何が起こっているかを簡単に確認できました。
マスタークラス
10月31日は報告がなかった日でしたが、それぞれ3時間の純粋な時間のワークショップが6つまたは8つあり、そのうち2つを選択する必要がありました。
PSオリジナルでは、それらはチュートリアルと呼ばれていますが、「マスタークラス」として翻訳するのは正しいようです。
カオスエンジニアリングブートキャンプ
プレゼンター: Ana Medina 、 グレムリンエンジニア| 説明
ワークショップは、カオスエンジニアリングの紹介に専念しました。 Anaは流itにそれが何であるか、それがどのような利益をもたらすか、どのように使用できるか、どのソフトウェアが役立つか、そして会社でそれを使い始める方法を示しました。
一般に、これは初心者にとっては良い入門書でしたが、Kubernetesを使用して複数のマシンのクラスターにデモWebアプリケーションを展開し、 DataDogからモニタリングをねじ込むという実用的な部分はあまり好きではありませんでした。 主な問題は、マスタークラスのほぼ半分の時間をこれに費やし、クラスター内のさまざまな問題をエミュレートするスクリプトを5〜10分間試し、グラフの変化を見るだけでよいことでした。
同じ効果のために、事前に設定されたDataDogにアクセスしたり、シーンからそれをすべてデモンストレーションしたりするのに十分だったようです。この時間は、たとえば、同じカオスモンキーの使用のより詳細なレビューと例に費やす必要がありますいくつかのフレーズ。


おもしろい:この会議で、スピーカーは「ブラスト半径」という言葉にしばしば言及しました。 特定の問題が発生したときに影響を受けるシステムの部分を指定しました。
追加資料:
- カオスエンジニアリング:歴史、原則、および実践
- エンジニアのためのカオスモンキーガイド
- システム内の問題をエミュレートするスクリプトを含むリポジトリ (スクリプトはマスタークラスで使用され、同様のマスタークラスからのプレゼンテーションへのリンクもあります)
- カオスエンジニアリングモニタリングおよびメトリックガイド
- 独自のカオスの日を計画する
進化するインフラストラクチャの構築
プレゼンター: Kief Morris 、インフラストラクチャコンサルタント、およびコードとしてのインフラストラクチャの作成者 | 説明
マスタークラスの主なポイントは、次の2つに減らすことができます。
- システムは常に変化するため、インフラストラクチャも変化させる必要があるのは正常です。
- インフラストラクチャは変化しているため、シンプルかつ安全であることを確認する必要があり、これは自動化によってのみ実現できます。
彼の話の主な部分は、特にインフラストラクチャの変更の自動化、この問題の可能な解決策、およびテストの変更に専念しました。 私はこのトピックの専門家ではありませんが、彼は非常に自信を持って詳細に(そして非常に迅速に)話しているように思えました。
このマスタークラスから覚えている主なポイントは、コードから環境変数への環境(プロダクション、ステージングなど)の区別を最大化するための推奨事項です。 これにより、環境を変更する際にインフラストラクチャでエラーが発生する可能性が低くなり、テストしやすくなります。



報告書
11月1日と2日は報告の日でした。 それらは2つの基本的なブロックに分けられました:朝に1つのストリームで送られた一連の3〜4つの短い基調報告(および2つの小さなホールから集まった大きなホール)と、残りの5つのフローでのより長いテーマレポート。 日中は、レポートの間にいくつかの大きな休止があり、カンファレンスパートナーのスタンドでエキスポを歩き回ることができました。
Runtasticバックエンドの進化
サイモン・ラッセルスベルガー(Runtastic GmbH)| 説明とスライド
著者が何かをする方法を伝えるだけでなく、特定のプロジェクトの詳細と彼に何が起こったかを示した数少ないレポートの1つ。
当初、Runtasticには共通のPercona Serverデータベースと、モバイルアプリケーションとサイトを提供するコードを備えたモノリスがありました。 その後、ストレージのキーと値が十分であるデータの一部をCassandraに書き込み始めました(その理由は覚えていません)。 次第にデータベースが膨らみ、MongoDBが追加され、ほとんどのサービスからデータを書き始めました。 時間が経つにつれて、彼らはWebアプリケーションとモバイルアプリケーション(私たちのアプリのようなもの)の両方からのリクエストを処理する一般的なレベルを作りました。
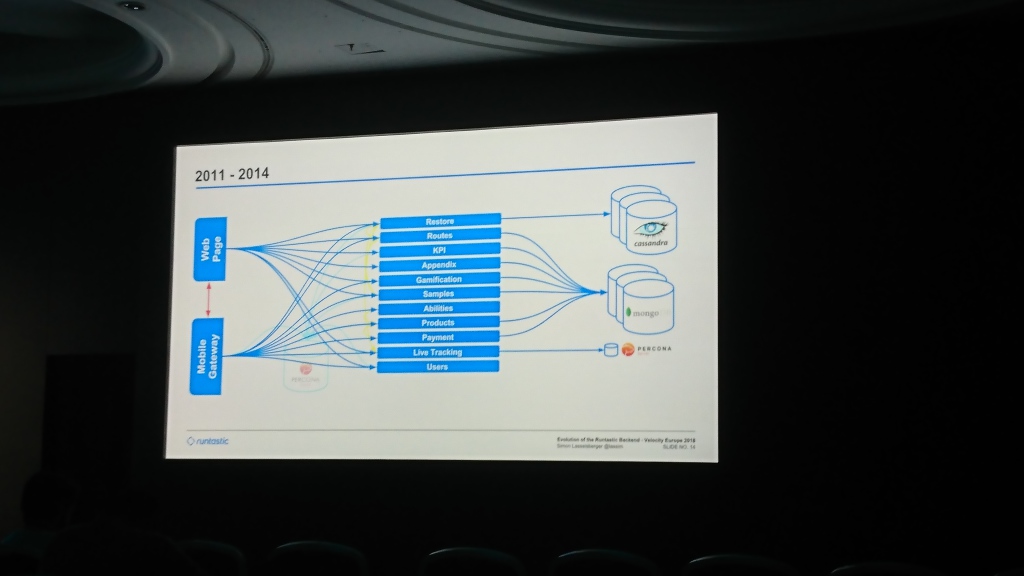
レポートのほとんどは、データセンター間の移動に当てられました。 最初は、サーバーをHetznerに保持していましたが、しばらくして安定性が不十分と見なされ、データがT-Systemsに移行しました。 数年後、彼らはすでにそこにスペースの不足に直面し、再びリンツAGに移動しました。 ここで最も興味深い部分は、データの移行です。 彼らは数ヶ月続いたデータのコピーを開始しました。 彼らはそんなに待つことができませんでした、なぜなら スペースが足りず、追加できなかったため、コードをフォールバックし、古いデータセンターからデータを読み取ろうとしたが、新しいデータセンターになかった場合。
将来的には、データをいくつかの個別のデータセンターに分割し(ロシアと中国にはこれが必要であると何度も述べています)、データベースを個別のサービスに厳密に分割する予定です(現在、すべてのサービスに共通プールが使用されています)。
サイモンがさりげなく言及した、システム内のモジュールの設計に対する興味深いアプローチ: 六角形のアーキテクチャ 。
ユーザー、プログラム、自動化されたテストまたはバッチスクリプトによってアプリケーションを等しく駆動し、最終的な実行時のデバイスおよびデータベースから分離して開発およびテストすることができます。
アリスター・コックバーン
追加資料:
カスタムメトリックの監視。 または、最初にインスツルメントし、後で質問する方法を学んだ方法
マキシム・ペタッツォーニ(SignalFx)| 説明とプレゼンテーション
このストーリーは、アプリケーションを理解するために必要なメトリックを収集することに専念しました。 主なメッセージは、通常のREDメトリック(レート、エラー、および持続時間)だけでは完全に不十分であり、それらに加えて、アプリケーション内で何が起こっているのかを理解するのに役立つ他のものをすぐに収集する必要があるということでした。
要約すると、著者は、システム内のいくつかの重要なアクション(および必然的に障害カウンター)のカウンターとタイマーを収集し、それらの分布のグラフとヒストグラムを作成し、カスタムメトリックのメタモデルを決定することを提案しました(異なるメトリックが必要なパラメーターの同じセットを持つように)同じ意味はどこでも同じと呼ばれていました)。

言葉で詳細を言い直すのは非常に困難です。プレゼンテーションの詳細と例を見やすくなります。プレゼンテーションへのリンクは、会議Webサイトのレポートページにあります。
追加資料:
サーバーレスがIT部門をどのように変えるか
ポール・ジョンストン(Roundabout Labs)| 説明とプレゼンテーション
著者は、CTOであり環境保護主義者であると自己紹介し、サーバーレスは技術的ではなく、ビジネスソリューションであると述べました(「使用しない場合は無料です」)。 次に、サーバーレスで作業するためのベストプラクティス、彼と連携するために必要な能力、およびこれが新しい従業員の選択と既存の従業員との連携にどのように影響するかについて説明しました。

私が覚えていた「IT部門への影響」の重要な瞬間は、必要なコンピテンシーが、単にコードを書くことからインフラストラクチャとその自動化で動作するようにシフトしたことです(「開発」より「エンジニアリング」)。コードレビュー、システムで使用可能なデータストリームとイベントの文書化、より多くのコミュニケーションと迅速な学習)を行いますが、何らかの理由で作成者はそれらをサーバーレス機能に起因すると考えています。

全体として、報告書は少し複雑に思えた。 スピーカーが語ったことの多くは、頭に完全には収まらない複雑なシステムに起因する可能性があります。
追加資料:
- サーバーレスのベストプラクティス - ベストプラクティスに関する著者の記事
パニックにならないでください! 生産の責任を負った今の対処方法
Euan Finlay(Financial Times)| 説明とプレゼンテーション
何かが今うまくいかない場合の生産インシデントへの対処方法に関するレポート。 主なポイントは、時間によって部分に分割されました。
事件の前に:
- 重要度によってアラートを区別します。おそらく、一部は待機でき、緊急に対処する必要はありません。
- インシデントの分析のために事前に計画を準備し、ドキュメントを最新の状態に保ちます。
- 演習を行う-何かを壊して何が起こるかを確認します(別名カオスエンジニアリング)。
- 変更や問題に関するすべての情報が集まる単一の場所を確立します。
インシデント中:
- あなたはすべてを知らないのが普通です-必要に応じて他の人を引き付けます;
- インシデントの解決に取り組んでいる人々間のコミュニケーションのための単一の場所を確立します。
- 生産を稼働状態に戻す最も簡単なソリューションを探し、問題を完全に解決しようとしないでください。
事件後:
- 問題が発生した理由と、それがあなたに何を教えたのかを把握します。
- これに関するレポート(「インシデントレポート」)を書くことが重要です。
- 改善できるものを特定し、特定のアクションを計画します。
最後に、EwanはFinancial Timesの事件について面白い話をしました。これは、生産ベース( prodと呼ばれる)が生産前( pprod )ではなく誤って変更されたために発生し、そのような類似した名前を避けることを勧めました。
Web of Lifeから学ぶ(基調講演)
クレア・ジャニッシュ(BiomimicrySA)| 説明
私はこの報告に遅れましたが、ツイッターで彼らはそれについて非常によく話しました。 それが出くわすかどうかを確認する必要があります。
プレゼンテーション付きのビデオは、会議のウェブサイトで見ることができます
誤報の時代(基調講演)
ジェーン・アダムス(Two Sigma Investments)| 説明
「意思決定アルゴリズムを信頼できますか」というトピックに関する哲学レポート。 一般的な結論は、いいえ:アルゴリズムは特定のメトリックを最適化できますが、同時に測定が困難なものまたはこれらのメトリックの外側にあるものに深刻な影響を与えます(例として、Amazonの従業員を雇用するアルゴリズムに差別があり、それが会社の文化に悪影響を及ぼしましたこのアルゴリズムを強制的に放棄します)。
Kubernetesの自由(基調講演)
クリスノバ| 説明
そこから、2つの考えを思い出しました。
- 柔軟性は自由ではなく、混乱です。
- 複雑さ自体には問題がありません(元の値では「必要な複雑さ」と呼ばれていました)。この複雑さのコストを超えています。
この報告書はかなり哲学的なものだったので、一方ではあまり情報を得ることができませんでしたが、一方で、私が得たものはKubernetesだけに当てはまりませんでした。

最初にオフラインになると何が変わりますか? (基調講演)
Martin Kleppmann(ケンブリッジ大学)、 Designing Data-Intensive Applications | 説明
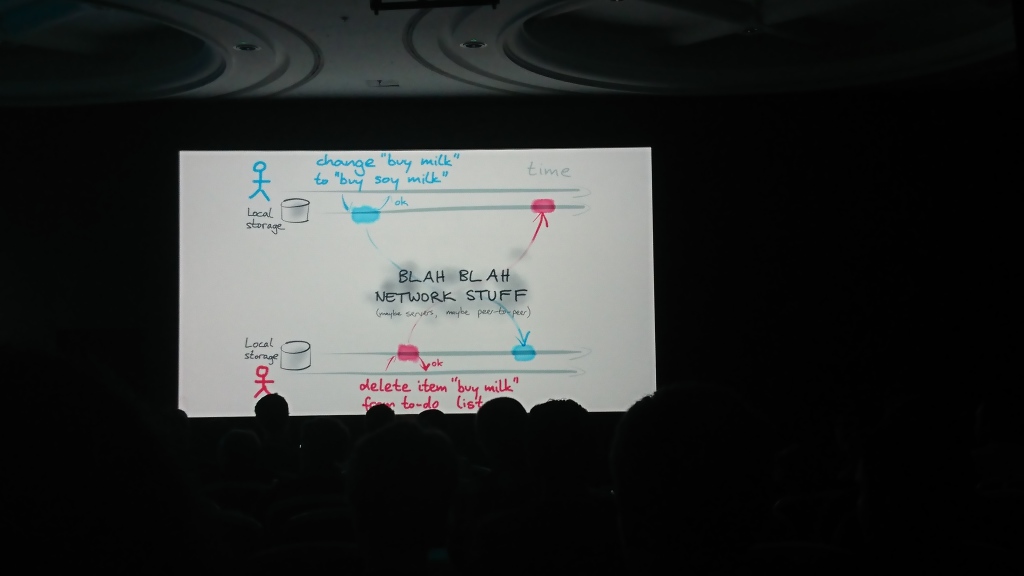
レポートは2つの論理部分で構成されていました:最初に、Martinは複数のソースで独立して変更できる相互にデータを同期する問題について話し、2番目に、これに使用できる可能なソリューションとアルゴリズム( 操作変換 、OT 、および競合のない複製されたデータ型 (CRDT))およびその解決策-そのような問題を解決するための自動マージライブラリを提案しました。


追加資料:
接続を保護するためのプログラマーズガイド
このレポートは、ライブコーディングセッションの形式で開催され、その中で、LizはHTTPSの仕組み、セキュアな接続を使用しているときに発生する可能性のあるエラー、およびそれらを解決する方法を示しました。 深みはありませんでしたが、デモンストレーション自体はとても良かったです。
最も役立つ:主なエラーを含むスライド( 別名別の会議でのリズのレポートから ):

追加資料:
モノレポについて知りたいが、尋ねることを恐れていたすべて
サイモンスチュワート(セレンプロジェクト)| 説明
レポートの主な論文は、monorepoではコード内の依存関係を管理するのがはるかに簡単であり、これが個々のリポジトリのすべての利点をカバーしているということです。 彼は、GoogleとMicrosoftは1つのリポジトリ(それぞれ86 Tbと300 Gbのサイズ)にデータを保存し、Facebookリポジトリ(54 Gbファイル)は「シェルマーキュリアル」を使用するという事実に訴えました。
「従業員よりも会社のリポジトリが多いのは誰か」という質問の後、部屋は「爆発」しました。
「低速で動作する大きなリポジトリを使用する」という議論は、次のように壊れました。
- 変更履歴全体をローカルマシンに取り込む必要はありません。 シャドウクローンとスパースチェックアウトを使用します。
- リポジトリのすべてのファイルを使用する必要はありません。ファイルの階層を整理し、必要なディレクトリのみを操作し、他のすべてを除外します。
追加資料:
分散リアルタイムストリーム処理システムの構築
エイミー・ボイル(New Relic)| 説明とプレゼンテーション
NewRelicのエンジニアからのストリーミングデータを扱うことに関する良い話(彼らが明らかにそのようなデータを扱う経験が豊富な場合)。 エイミーは、ストリーミングデータ、集計方法、時間差データの処理方法、シャードイベントストリームの方法、プロセッサ障害の場合にそれらを再調整する方法、監視対象などを操作していると述べました。
レポートには多くの資料がありましたが、再説明するつもりはありませんが、プレゼンテーション自体を見ることをお勧めします(既に会議のWebサイトにあります)。


テレビの設計
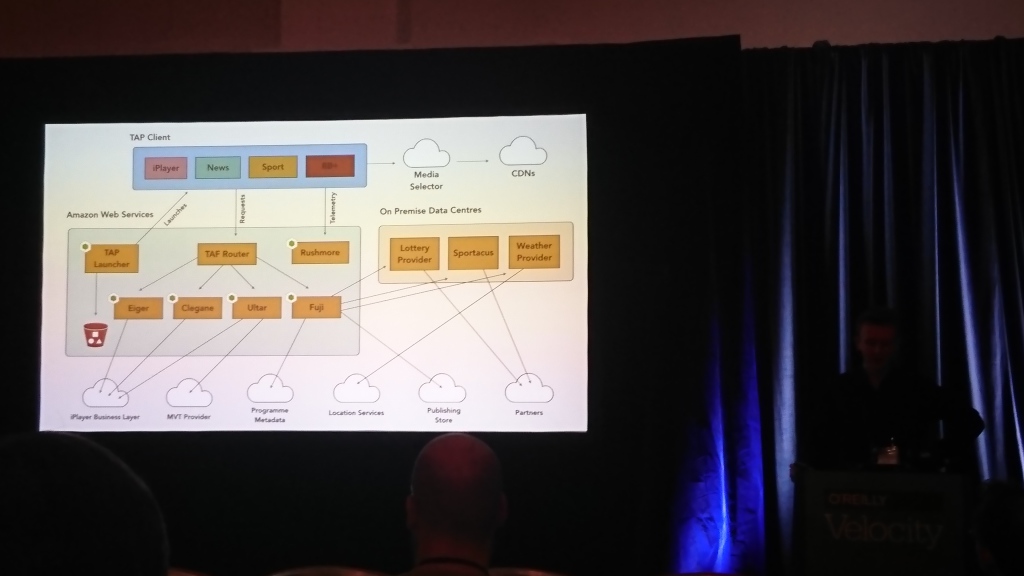
デビッドバックハースト(BBC)、ロスウィルソン(BBC)| 説明
講演のほとんどは、BBCフロントエンドに関するものでした。 彼らはインタラクティブなテレビと、これが機能するはずの多くのテレビやその他のデバイス(コンピューター、電話、タブレット)を持っています。 まったく異なる方法でさまざまなデバイスを操作する必要があるため、インターフェイスを記述する独自のJSONベースの言語を考え出し、それを特定のデバイスが理解できるものに変換します。
私にとっての主な結論は、テレビの人々と比較して、モバイルアプリケーションは古い顧客には問題がないということです。