私たちの仕事は、コンタクトセンターの音声分析システムを開発することでした。 このシステムは、音声認識とインデックス検索の2つの基本技術に基づいています。 認識にはエンジンを使用し、インデックス作成と検索にはSolrを選択しました。
なぜSolrなのか? インデックス検索エンジンに関する独自の比較調査は行いませんでしたが、同僚の意見を注意深く調べました。 もちろん、ElasticsearchまたはSphinxを優先して選択することもできますが、明らかに、プロジェクトのスターはSolrを優先して形成されたため、「見ました」。 プロジェクトの過程ですでに、Solrで使用可能な設定でタスクを構成するのに十分であると判断しました。
私たちのプロジェクトの特徴
このシステムは、カスタマーコールの分析用に開発されたもので、コンタクトセンターに記録されてサービス品質を監視します。 音声を分析するのではなく、対話の自動認識の結果として得られたテキストを分析します。 認識された音声のテキストは、ウェブサイトや電子メールで定期的に出会うテキストとは根本的に異なります。 認識精度が100%であっても、認識された自然発話のテキストには意味がないように見える場合があります。
これは2つの主な要因によるものです。 第一に、口頭スピーチでは、非言語的および顔の表情が非常に頻繁に使用されます。これらはテキストでは認識されませんが、言われたことを理解するために重要です。 第二に、スピーチでは、言語構成の略語と省略が常に使用されます。これは、コミュニケーション状況の文脈から復元することができます。 言語学におけるこの現象は、省略記号と呼ばれます。
認識されたスピーチのテキストとそのすべての機能を自分の目で見るには、音声をオフにしたYouTubeのビデオの自動字幕を参照してください。 これがこのコンテンツに関するもので、資料は音声分析システムの入力に使用されます。
複雑なクエリ
Solrは標準の条件ステートメントとグループ化をサポートしていますが 、多くの場合、これらの機能ではアナリスト向けのすべてのシナリオを実装するには不十分です。
多くの場合、アナリストはSolrインデックスに含まれていないパラメーターを使用してクエリを作成する必要があります。 たとえば、会話の最後の30秒間に話されたすべての単語「ありがとう」を見つけます。 単語はSolrによってインデックス付けされますが、一時的な単語位置はありません。 これらのクエリを「複雑」と呼びます。Solrインデックスパラメータと、Solrインデックスに含まれないその他のデータ選択パラメータの両方を含むクエリです。
アナリストはどのようにクエリを作成しますか?
アナリストは、Solrインデックスの構成について何も考えていません。彼は、呼び出しの表音文字とそのテキストの解読のすべての属性を検索およびカットすることが重要です。 したがって、アナリストにとっての「複雑なクエリ」の概念は純粋に実用的です。多くの選択パラメータがあるクエリ、またはクエリが階層に配置されています。
集合論の言語でアナリストの行動を説明すると、アナリストはクエリの助けを借りて、異なるサブセット(交差、相違、追加)間の関係を探求していると言えます。 アナリストは、階層クエリを使用して、データ配列を構造の必要な詳細レベルまで解析します。
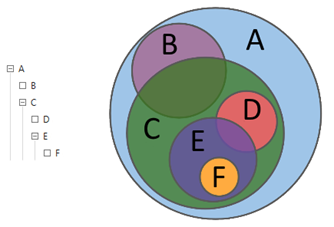
図1.階層クエリ
図2は、テキストと数値の両方の選択基準を含む複雑なクエリの典型的な例を示しています。
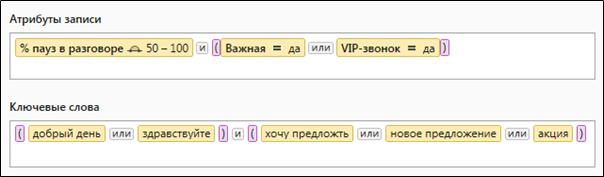
図2.定量的および語彙的なデータ選択パラメーターを含む複雑なクエリ
Solrのクエリはどのように見えますか?
図1のクエリBの例を使用して、Solrでクエリを実行する一般的なメカニズムを考えてみましょう。見てわかるように、クエリBには親クエリA 、つまりB⊆Aがあります。 音声分析では、「親」の少なくとも1つが未解決になるまでリクエストを処理できません。 したがって、クエリAが最初に実行され、次にBが実行されます。 明らかに、 BにはクエリAの条件が含まれている必要があります。
最初に頭に浮かぶのは、両方のクエリの条件を
AND
で結合し、クエリに貼り付けることです。
q=key:A AND key:B
ただし、連続するすべてのクエリを1つの
query
に単純に結合すると、
query
は大きくなり、クエリごとに異なり、全体が計算されます。 また、条件Aは、クエリBの結果の関連性に影響しますが、これは望ましくありません。
親クエリを
FilterQuery
として追加してみましょう。 この場合、クエリAは非関連性の影響を受けず、すでに完了しており、その結果がキャッシュにあると予想できます。 したがって、SolrはクエリBのみを計算する必要がありますが、Solrは必要な方法で結果の選択をソートします。
q=keyword:B &fq=keyword:A
Solrへのリクエストの形式を模式的に考えると、2つの主要なエンティティを区別できます。
-
MainQuery
ドキュメントが満たす必要がある一連のパラメーターを持つメインクエリ。 たとえば、text_operator: ” ”
オペレータの検索リクエストは、text_operator: ” ”
ます。
これは、検索ドキュメントのtext_operatorフィールドに「こんにちは“ ”
というフレーズが含まれている必要があることを意味します
-
FilterQuery
結果の選択を制限する追加のフィルターのセット。FilterQuery
形式はMainQuery
一致しMainQuery
要求を
Main
と
Filter
分割すると、次のことができます。
- どのクエリパラメータが選択範囲内のドキュメントのランクに影響を与え、どのクエリパラメータが結果の選択範囲内の選択にのみ役立つかを明示的に示します。 ドキュメントのランクを構築するための関連性は、MainQueryクエリの一部が実行されるときに計算され、
FilterQuery
クエリの一部がFilterQuery
と、クエリ条件を満たさないドキュメントが削除されます -
FilterQuery
計算後に取得された結果のサンプルは完全にキャッシュされるFilterQuery
、検索エンジンの負荷を大幅に削減します。一方、MainQuery
計算の結果は、50個の値のランクの最初の結果についてのみキャッシュに保存されます
MainQuery
と
FiletrQuery
は、Solr関数に異なる影響を及ぼします。 たとえば、 強調表示の場合、関連するドキュメントフラグメントを強調表示する機能であり、
MainQuery
のみ
MainQuery
、
FilterQuery
パラメータ
FilterQuery
highlighting
影響
FilterQuery
ません。 関連性は
MainQuery
クエリの一部で正確に計算されるため、これは論理的です。 これが、単語「hello」および「services」を含むテキストの実際の検索で
highlighting
結果がどのように見えるかです。
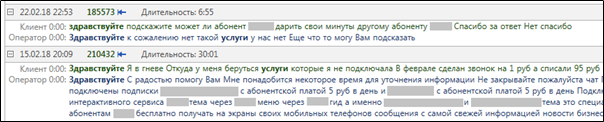
図3.
MainQuery
クエリの完了後の関連する単語の強調表示。
Solrの複雑なクエリ
丁寧なオペレーターの例に戻りましょう。 この例では、オペレーターのスピーチに「こんにちは」というフレーズがあるかどうかで適切な通話を決定しましたが、会話の開始または終了に関連するキーワードを検索する時間間隔を示していませんでした。
これに必要なものはすべてあるようです-電話での会話のテキストの書き起こしには、各単語のタイムスタンプと、それが属する対話の参加者に関する情報が含まれています。 このデータは検索にも使用できます。
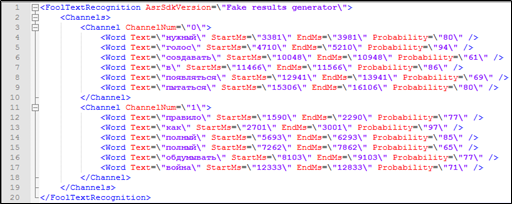
図4. Solrインデックスに含まれないマークアップ付きのテキスト復号化の断片:スピーカーの所属、タイムスタンプ。
しかし、索引付けできないパラメーターが照会に関係している場合(単語が発音される時間)、Solrへの検索照会を処理する方法は?
この問題を解決する2つの明白な方法が発生します。
- Solrインデックスにインデックスのないパラメーターを追加します。 同時に、メモリ消費量はわずかに増加しますが、インデックスは大幅に増加します
- インデックス付けできないパラメーターによるデータの選択は、そのサービスを使用して実行する必要があり、そのような選択後に取得したドキュメントのコレクションでは、Solrインデックスを使用して検索します。 同時に、メモリ消費量は最初の場合よりも大幅に増えますが、パフォーマンスは予測可能です
2番目のオプションを選択しました。 これを行うために、Solrインデックスに含まれていない論理パラメーターと数値パラメーターを含む要求によってコレクションを計算するサービスを開発しました。 このサービスの結果として、要求を満たさなかったコレクションの部分は特別なタグ(「エスケープ」)でマークされ、クエリ結果の計算に参加しなくなりました。
ダイアログの最初の30秒間でのみ、既に知っているクエリBの検索に制限を課したいと想像してください。 最初の段階では、 Bを単純なクエリとして実行し、選択された範囲を超える単語をSolrインデックスに入らないように「選別」しますが、同時に元のドキュメントを復元できます。 結果のドキュメントは別のSolrコレクションに配置され、クエリBの検索がそのコレクションで再開されます。
ここで、会話の開始または終了の制限は花であり、果実は親リクエストの結果の制限であると言わなければなりません。 そのようなリクエストの実行を検討してください。
| 文書が数字の付いたボールで構成されていると想像してください。 「5」の右側にある2つ以下のボールにあるすべてのボール「6」を見つけてみましょう。
ボール番号がSolrインデックスに含まれており、ボール間に距離がないことを既に理解しています。 |  |
ボールが「6」と「5」のすべてのドキュメントを検索します。 MainQuery
として、ボール「5」のクエリと「6」のクエリ MainQuery
使用して、 FilterQuery
送信します。 その結果、Solrは検索結果で「5」個のボールを強調表示し、次のステップでの生活を大幅に簡素化します。 | 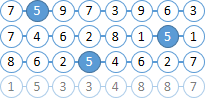 |
| 「5」から必要な距離にあるものを除くすべてのボールを選別します。 受け取ったドキュメント(目的のボールを含むドキュメント)は、別のコレクションに配置されます。 |  |
結果のコレクションのボール「6」でFilterQuery
を実行してみましょう。結果は、 FilterQuery
いるドキュメントです。 |  |
実際には、ボール5と6は通常、テキスト表現でいくつかの画面を占めるクエリを隠します。 この検索を無駄に実装しなかったことを嬉しく思います。アナリストは、親からの制限のあるクエリを頻繁に使用します。
おわりに
プロジェクトの結果、何を学び、何を学び、何を達成しましたか?
Solrを効果的に使用してさまざまなタイプのデータを操作する方法を知っています。Solrを検索して、検索インデックスに含まれていないパラメーターを持つクエリを処理できます。
高負荷で動作する産業用音声分析システムを開発しました。最大500万件のテキストドキュメントのサンプルに対して、アナリストの複雑な検索クエリが計算されます。 それは可能であり、それ以上ですが、実用的な必要性はありませんでした。 アナリストの通常の作業サンプルは、認識された通話の最大約50万テキストで、通話の総数は1500万に達する可能性があります。
コンタクトセンターのお客様に対して、システムは非常に異なる性質の分析の前例のない機会を提供します:トピックの分析とリクエストの理由、顧客満足の分析、その他多数。
現在、新しいソースを分析につなげています-顧客とオペレーターとのテキストチャット。 コンタクトセンターのすべてのチャネル(電話、チャット、ウェブサイト上のフォームなど)でクライアントコールを分析するための単一のアプリケーションを実装します。
ご質問にお答えします。
ありがとう
PS Solrは非常に難しいものであり、良い結果を得るには良いチューニングが必要です。 この分野での経験については、次の記事で説明します。