そして、私は情報セキュリティチェックポイントの分野でイスラエルの大手企業からのサイバーテストについて話し続けています。 以前の投稿で 、4つのテストをどのように行ったかを説明しましたが、これで次の3つのテストについて話したいと思います。
最初の投稿を見逃した方のために、この夏、 チェックポイントは一連のサイバーテストを公開しました。
チャレンジは2018年9月末までに公式に終了しました。
タスクは6つのカテゴリに分けられました。
•ロジック
•Web
•プログラミング
•ネットワーキング
•逆転
•サプライズ
各方向に2つのタスク。 すでに書いたように 、チェックポイントはすでに私の側で尊敬と関心を集めていたので、これらの課題を受け入れることにしました。 しかし、雇用のために、12のタスクのうち8つだけを(4つの異なるカテゴリーから)取る余裕がありました。 そして、そのうちの7つを解決できました。
など:
チャレンジ:パズル
説明:
最後にあなたを見つけました!
私たちはこのパズルを収集する必要があります、そして予言が言うように-あなただけがそれをすることができます。
パズルは非常に奇妙です。 10列10行のボードで構成されています。 合計-100パーツ。 そして、それらのそれぞれは謎を運びます! パーツは、上下左右の4つのパーツで構成されています。 各ビートは数字です。 例:
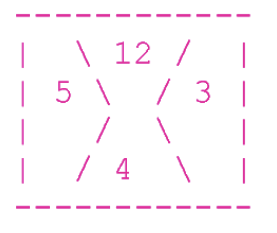
上-12、右-3、下-4および左-5。
パズルが発展するためには、各ピースが等しい値に隣接するように、すべての詳細をボードに配置する必要があります。
さらに、ボードの境界の一部であるが、何にも隣接していない端数は0に設定する必要があります。残りの端数にゼロ値を設定することはできません。 4つの部分の有効な例を次に示します。
ボードの上部では、境界を構成する端数はすべてゼロです。
左上の部分を検討してください。 その右葉は9で、隣接する葉(右上部の左葉)も9です。
残念ながら、詳細はすべてシャッフルされています。 それらは次の形式で与えられます:
キューブのID [割合]; キューブID、[共有]; ...キューブID、[共有]
ここで、キューブIDは0から99までの数字であり、小数部は上、右、下、左の順に並べられた数字で構成されています。
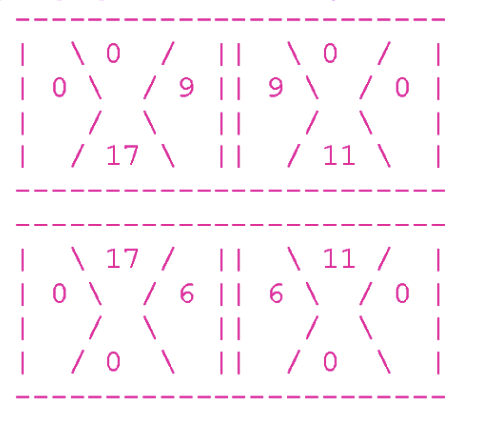
たとえば、次のシャッフルボードを見てください。

このボードを説明する行は次のとおりです。

パズルを組み立てる必要があります!
次のような行を作成してください。
キューブのID。時計回りに回転する必要がある回数。 キューブのid、時計回りに回転する必要がある回数; ...キューブのid、時計回りに回転する必要がある回数
このボードのソリューションの行は次のようになります。

上記の行は、次の(解決された)パズルに対応しています。

左上の部分を検討してください。 行では、指定「2.2」に対応しています。 入力からキューブ番号2を取得する方法:
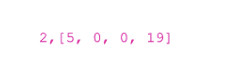
しかし、時計回りに2回ねじると[0,19,5,0]になります。
次に、上部中央部分を検討します。 行では、指定「1.0」に対応しています。 したがって、入力からキューブ番号1を取得します。

そして、それをまったくねじらないでください(はい、それを0回ねじってください)-それはすでに正しい位置にあることを意味します。
わかった?
パズルを組み立てるのを手伝ってください!
次のようになります。

頑張って
理論的には、この問題はさまざまな方法で解決できます。 あなたのものを見つけて共有しましょう。 私はいくつかの選択肢を熟考し、最終的に次の結論に達しました。
最初のもの。 常に、1つのキューブを定義する必要があります。 各キューブについて、上と左の2つの側面を必ず確認します。 最初は0と0です。上部の次のキューブにも0があり、左側には前のキューブの右ローブの番号に対応する番号があります。
二番目。 キューブにはさまざまなバリエーションがあるため、最初のネガティブな結果で無意味な検証を排除し、できるだけ少ないステップを作成するようにしてください。
三番目。 さまざまなキューブを使用するには、それらの初期位置(id)、開始点からのターン数、そして明らかに側面の数(上、右、下、左)を覚えておく必要があります。
4番目。 最初の入力は文字列です。 また、出力も文字列です(現在の位置ではありません)。
これらすべてに基づいて、私は自分のために次の戦略を開発しました。
直線的に移動します-右隅に達するまで左から右へ。 次に、行を下って、上にある立方体の小さい番号から左から始めます。
各回転後にコンプライアンスをチェックする必要があります。 したがって、すでに4ターンを完了し、それでもこのキューブに一致するものが1つもない場合は、次のキューブを取り上げます。 チェックされた各キューブは、他のすべての詳細で潜在的にチェックできます。そのため、他のすべてのキューブの完全なセットを使用して、各キューブの初期化を再帰的に繰り返すことができます。
ソースデータを使用したすべての操作を追跡するために、キューブがid、回転数、および4つの側面(上、右、下、左)を持つオブジェクトであるオブジェクト指向プログラミング方法を選択しました。
初期状態をコピーして、複数のスピン後の誤ったカウントを回避する代わりに、カウントを常に1増やしました。 しかし、最終的な回転数をチェックするとき、4によるモジュロ(除算の剰余)を使用しました。
たとえば、1回転が必要な場合([1,2,3,4]から[4,1,2,3]まで)、最初の3回転が誤って実行された場合(現在[2,3,4,1] )、次回は2(現在の[2,3,4,1]から必要な[4,1,2,3]まで)がかかります。 3 + 2は5です。5%4 = 1で、これが必要です。
使用したキューブを常に追跡し、再チェックを防止する必要があります。 これには、idキューブのテーブルを使用します。 そして、比較されているキューブが一致する場合、リストから削除します。
次のデータ構造を選択しました。
HashMap-id(初期位置)と入力文字列から構築されたキューブをバインドします。
スタック-関連するIDキューブを確認します。
配列-結果の一時的なテスト用。
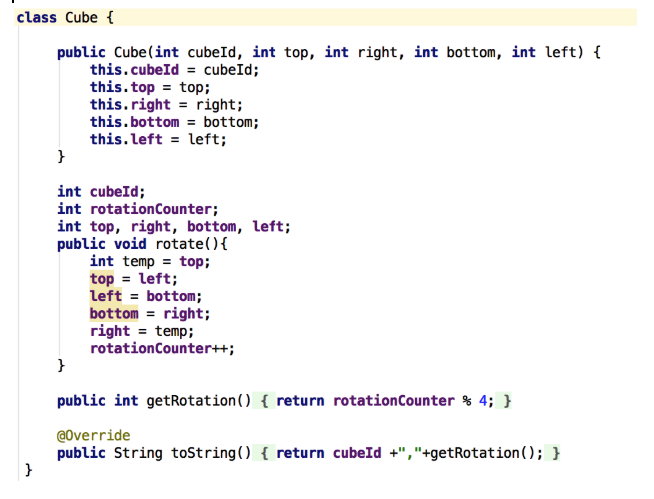
オブジェクトコードキューブ:
文字列操作関数:

一致するキューブを見つけるためのソリューションのロジック:

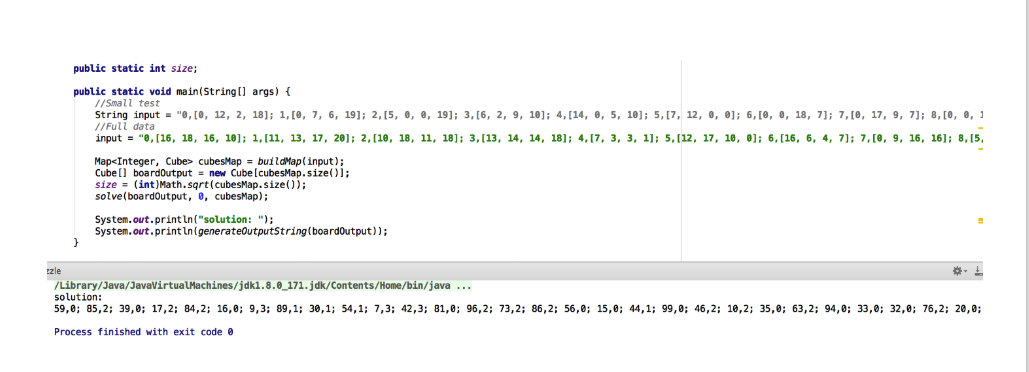
結果:
チャレンジ:ピンポン
説明:
あなたは私を打ち負かすほど速くないに違いない。
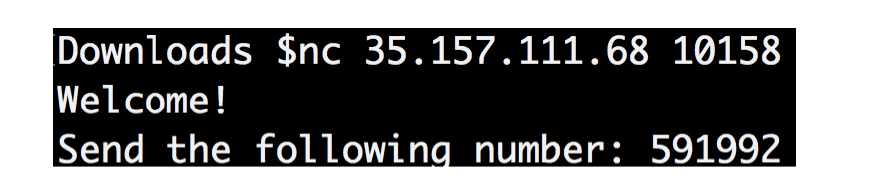
これは私がいる場所です:
nc 35.157.111.68 10158
このコマンドを実行すると、次のものが得られます。
一見、これはストリームを操作するためのタスクのようです。
ただし、最初のデータを受信した後、タイムアウトになり、その後完全に-覆われるようです。
データが終了すると、新しい行区切り記号が表示されます。
Pythonコードを使用してストリームを再作成しました。
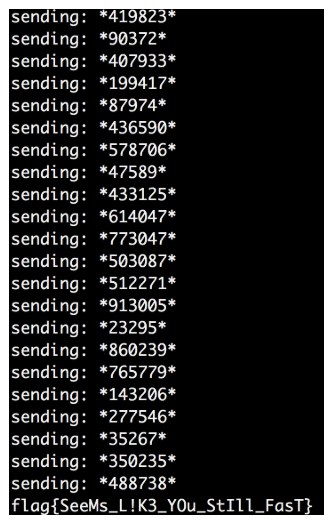
動作しているようなので、ピンポンアルゴリズムを繰り返す反復コードを追加し、フラグが表示されるまで待ちます。

クライアントとサーバーとの間で膨大な数の(おそらく1000以上の)ピンポンシャッフルが行われた後、ようやく完了しました。
課題:「プロトコル」
説明:
こんにちは!
特別なサーバーから秘密データを抽出する必要があります。 彼についてはあまり知りませんが、このサーバーとの通信をサポートするトラフィックを傍受することができました。
また、この秘密ファイルへのパスは/usr/PRivAtE.txtであることもわかっています。
ここでスニフファイルを見つけることができます(ファイルへのリンク)。
その秘密を教えてください!
頑張って
ファイルをダウンロードし、Wiresharkを使用して開きました
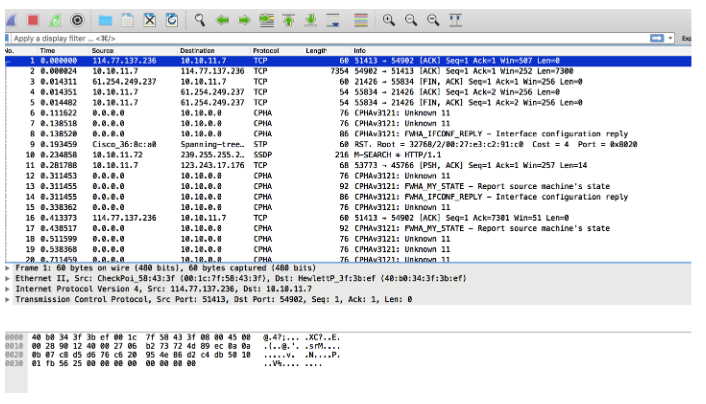
そして、登録された交渉を確認しました
何が起こっているのかを理解することができました。
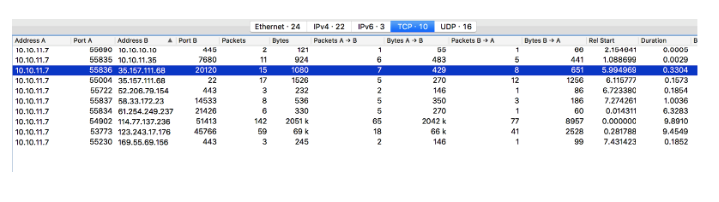
ポート20120とSSHポート22を介してIP 35.157.111.68の間でネゴシエーションが行われていることに気付きました。このポート20120を確認し、決定してからSSHに切り替える必要があります(これは必要ないことがわかりました)。
ncコマンドを使用してこのIPとポートを確認し、「0 8 Welcome」という応答を受け取りました。
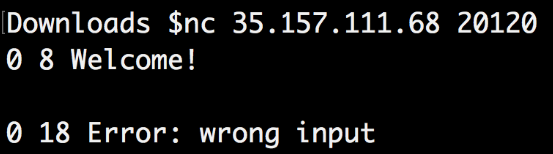
彼が何を期待していたのかわからなかったので、Wiresharkに戻って手掛かりが残っているかどうかを確認しました。
ポート20120で35.157.111.68のすべてのデータパケットをフィルターで除外すると、読みやすい会話が見つかりました。
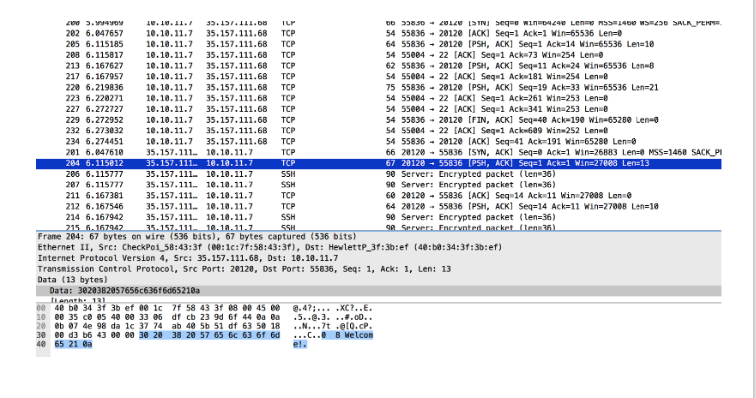
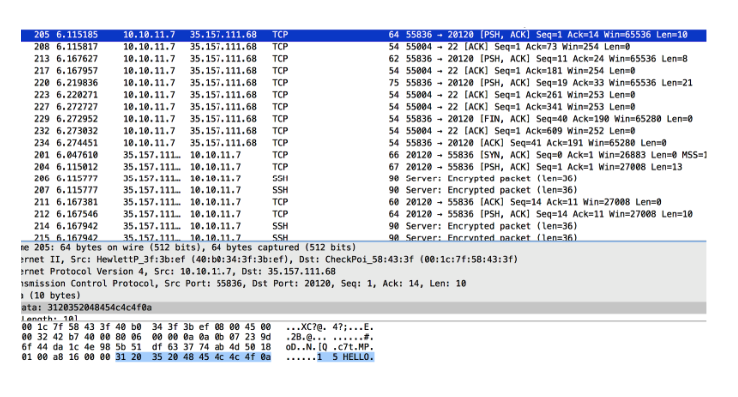
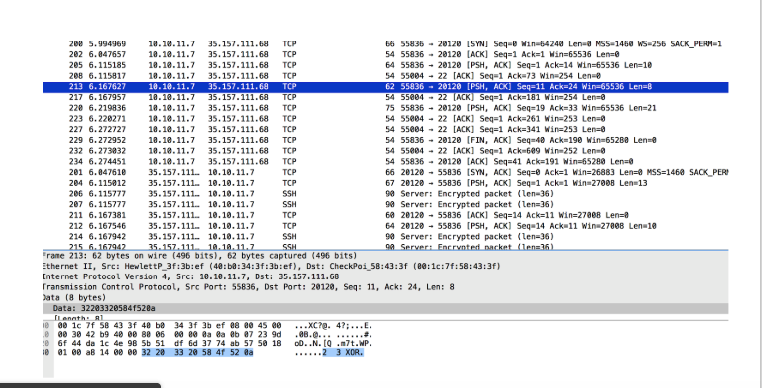
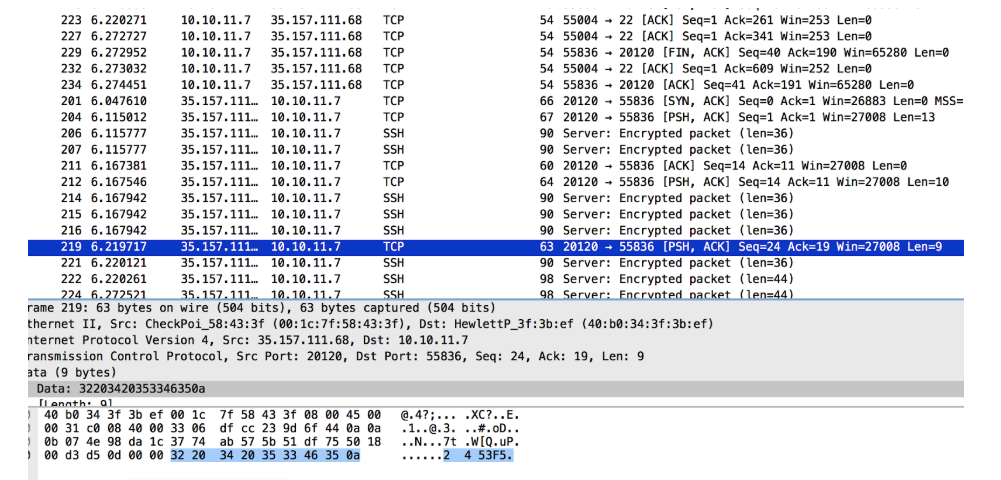
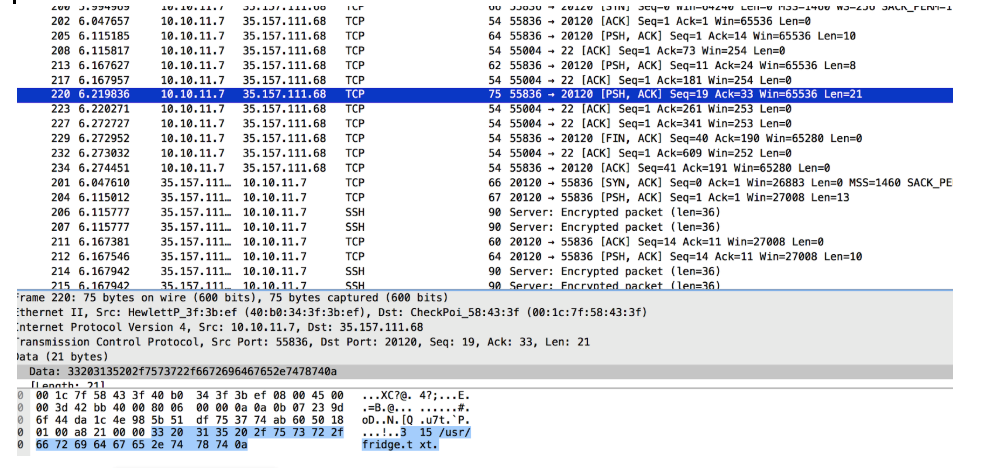
ncコマンドラインを使用して、これをすべて再作成しました。
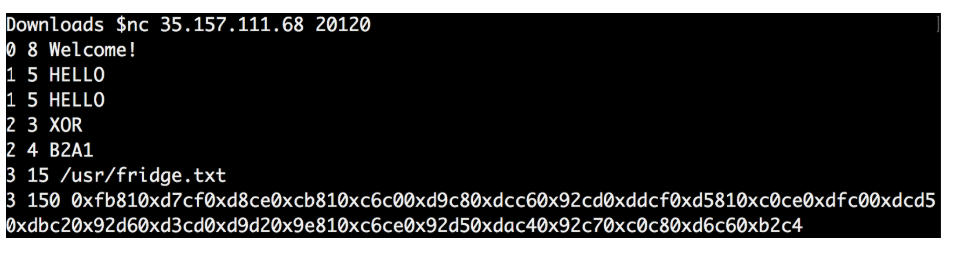
「2 3 XOR」リクエストに対する回答がファイル内の回答と異なることに気付きました。
答えが毎回変わるかどうかを確認するために、手順全体を何度も繰り返しました。
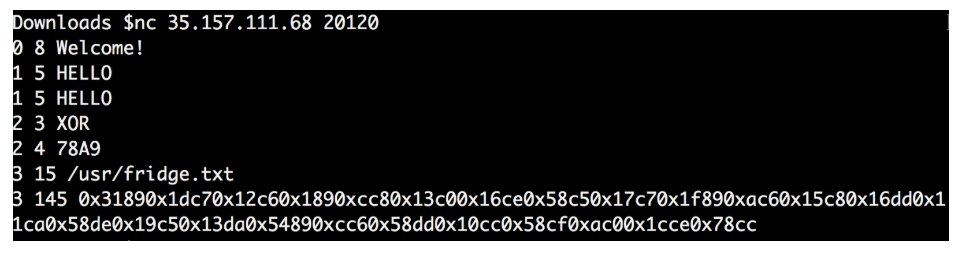
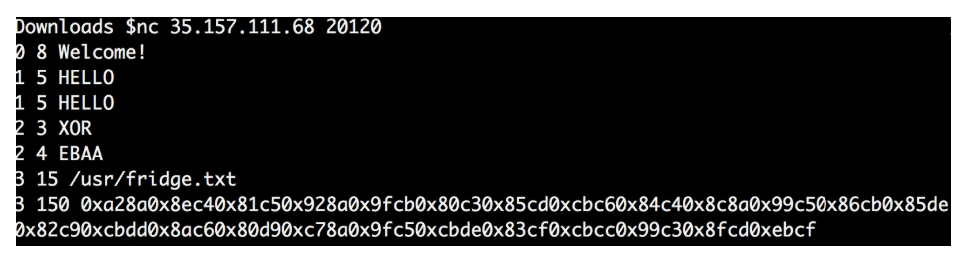
思ったように、得られた4つの値は毎回異なり、最終データもそうでした。
得られた4つの値は、最終データを解読するための鍵のようです。
また、各データパケットの前の数字はランダムではないことに気付きました。
次のようになります。
最初の数字は順序を意味します:0->最初、1-> 2番目、2-> 3番目など...
2番目の数字は、フレーズ8->「ようこそ」、5->「こんにちは」->などの期間を意味します。
これが復号化の鍵ではないかと考えました。 最終データは4 HEX値のブロックの連続した行であり、XORキーも4 HEX値です。 おそらく、それぞれを反復処理して別々のバイトに分割し、キーからのバイトで噛むことができます。
そして、解読しようとしました:

すべてが判明しましたが、受信したデータにはフラグがありませんでした。

ルールを読み直し、この秘密ファイルへのパスは次のとおりであることを思い出しました:/usr/PRivAtE.txt
もう一度手順を繰り返しましたが、今回はパス「/usr/PRivAtE.txt」を要求しました
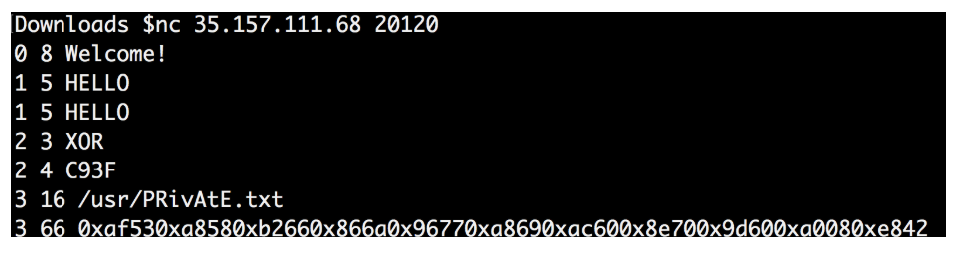
最終データの復号化を再試行しました。

そして、旗は私の手にありました:

成功しましたか? あなたのアイデアやオプションを書いて、私はコメントしてうれしいです。