 ビッグデータは今日のビッグビジネスです。 情報は私たちの生活を制御し、それを利用することは現代の組織の仕事の中心です。 アナリティクスを扱うビジネスマン、初心者プログラマー、または開発者である「Big Data Theoretical Minimum」は、あなたが誰であろうと、現代のテクノロジーの荒れ狂う海にdrれず、急速に発展する新しいビッグデータ処理業界の基本を理解できます。
ビッグデータは今日のビッグビジネスです。 情報は私たちの生活を制御し、それを利用することは現代の組織の仕事の中心です。 アナリティクスを扱うビジネスマン、初心者プログラマー、または開発者である「Big Data Theoretical Minimum」は、あなたが誰であろうと、現代のテクノロジーの荒れ狂う海にdrれず、急速に発展する新しいビッグデータ処理業界の基本を理解できます。
ビッグデータとその操作方法について学びたいですか? 各アルゴリズムに個別の章が設けられており、作業の基本原理を説明するだけでなく、実際の問題での使用例も示しています。 多数の図と簡単なコメントにより、ビッグデータの最も複雑な側面を簡単に理解できます。
「主要コンポーネント」の一節をよく理解してください。
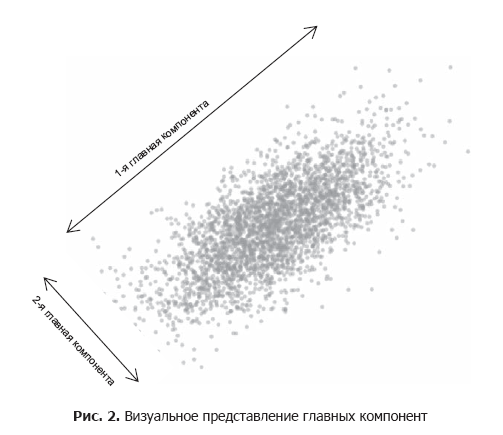
主成分分析(CIM)メソッドは、データ要素を最適な方法で区別する基本変数(主成分と呼ばれる)を見つける方法です。 これらの主要なコンポーネントは、データの最大の分散を提供します(図2)。
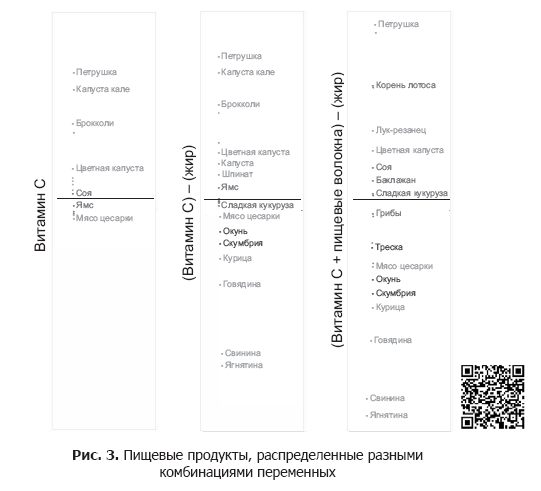
主要コンポーネントは、1つ以上の変数を表現できます。 たとえば、単一の変数「Vitamin C」を使用できます。 ビタミンCは野菜には含まれているが肉には含まれていないため、最終的なグラフ(図3の左列)では野菜が分布しますが、すべての肉は1つの山になります。
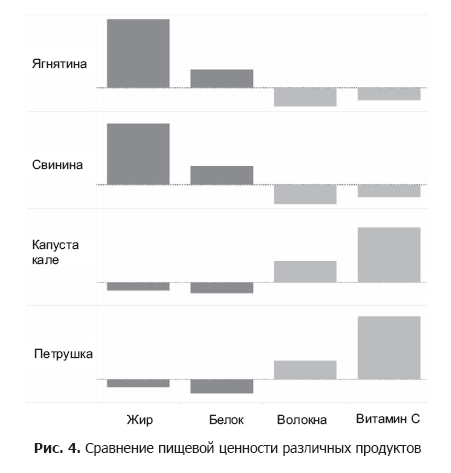
肉製品の流通には、2番目の変数として脂肪を使用できます。脂肪は肉に含まれていますが、野菜にはほとんど含まれていません。 ただし、脂肪とビタミンCは異なる単位で測定されるため、それらを組み合わせる前に標準化する必要があります。
標準化とは、各変数をパーセンタイルで表現したもので、これらの変数を単一のスケールに変換し、それらを組み合わせて新しい変数を計算できます。
ビタミンC-脂肪
ビタミンCはすでに野菜を広げているので、脂肪を差し引いて肉を分配します。 これら2つの変数の組み合わせは、野菜と肉製品の両方を配布するのに役立ちます(図3の中央の列)。
野菜の含有量が異なる食物繊維を考慮することにより、広がりを改善できます。
(ビタミンC +食物繊維)-脂肪。
この新しい変数により、最適なデータ散布が得られます(図3の右列)。
この例の主要なコンポーネントは試行錯誤によって取得しましたが、CIMは体系的にこれを行うことができます。 次の例で、これがどのように機能するかを確認します。
例:食品群分析
米国農務省のデータを使用して、脂肪、タンパク質、食物繊維、ビタミンCの4つの食品変数を調べて、ランダムな食品セットの栄養特性を分析しました。 4、特定の栄養素はしばしば一緒に食品に含まれています。
特に、脂肪とタンパク質のレベルは、食物繊維とビタミンCのレベルが増加する方向とは反対の方向に増加します。どの変数が相関するかを確認することで仮定を確認できます(セクション6.5を参照)。 実際、タンパク質と脂肪のレベル(r = 0.56)、および食物繊維とビタミンCのレベル(r = 0.57)の両方に有意な正の相関があることがわかりました。
したがって、4つの食品変数を個別に分析する代わりに、相関性の高いものを組み合わせて、2つだけを考慮に入れることができます。 したがって、主成分法は次元削減手法と呼ばれます。
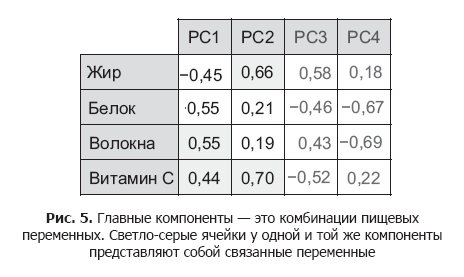
それを食品データセットに適用すると、図に示す主要なコンポーネントが得られます。 5。
各主要コンポーネントは食品変数の組み合わせであり、その値は正、負、またはゼロに近い場合があります。 たとえば、個々の製品のコンポーネント1を取得するには、次を計算できます。
.55(食物繊維)+ .44(ビタミンC)-.45(脂肪)-
.55(タンパク質)
つまり、試行錯誤によって変数を結合する代わりに、以前に行ったように、主成分法自体が、位置を区別できる正確な式を計算します。
主成分1(PC1)は、すぐに脂肪とタンパク質、食物繊維とビタミンCを組み合わせ、これらのペアは反比例することに注意してください。
PC1は肉と野菜を区別しますが、コンポーネント2(PC2)は肉(脂肪含有量に基づく)および野菜(ビタミンC含有量に基づく)の内部サブカテゴリをより詳細に識別します。 グラフの両方のコンポーネントを使用して、最適なデータ散布図を取得します(図6)。

肉製品の成分1の値は低いため、チャートの左側、野菜の反対側に集中しています。 また、非野菜製品の中でも、魚介類の低脂肪含有量、したがってそれらの成分2の価値は低く、それら自体がグラフの下部にあることがわかります。 同様に、緑以外の野菜の成分2の値は低く、右側のグラフの下部に表示されます。
コンポーネントの数の選択 。 この例では、データセットの初期変数の数によって4つの主要なコンポーネントが作成されます。 主要コンポーネントは通常の変数に基づいて作成されるため、データ要素の分布に関する情報は初期セットに限定されます。
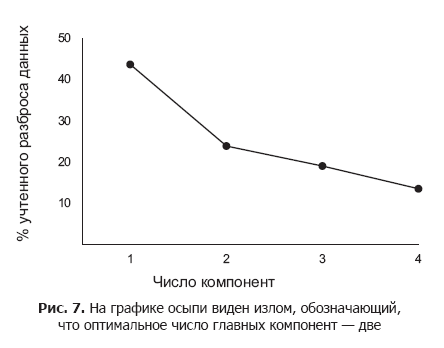
同時に、結果のシンプルさとスケーラビリティを維持するために、分析と視覚化のために最初のいくつかの主要なコンポーネントのみを選択する必要があります。 主なコンポーネントは、データ要素の配布の効率が異なり、最初のコンポーネントは最大限にこれを行います。 考慮すべき主要コンポーネントの数は、前の章で検討したスクリーグラフを使用して決定されます。
グラフは、データ要素を区別する際の後続の主要コンポーネントの有効性の低下を示しています。 原則として、スクリープロットの急性骨折の位置に対応する主成分の量が使用されます。
図 7骨折は、約2つのコンポーネントにあります。 これは、3つ以上の主要なコンポーネントがデータ要素をより適切に区別できたとしても、この追加情報が最終的なソリューションの複雑さを正当化できない場合があることを意味します。 スクリーグラフからわかるように、最初の2つの主要コンポーネントはすでに70%の広がりを持っています。 データ分析に少数の主要コンポーネントを使用することにより、スキームが将来の情報に適していることが保証されます。
制限事項
主成分法は、複数の変数を持つデータセットを分析する便利な方法です。 ただし、欠点もあります。
分布を最大化します。 CIMは、最大の散乱を与える測定が最も有用であるという重要な仮定から始まります。 ただし、これは常にそうではありません。 よく知られている反例は、スタック内のパンケーキを数える問題です。
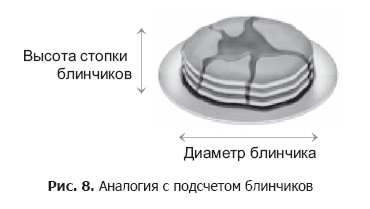
パンケーキを数えるために、垂直軸(つまり、スタックの高さ)に沿って互いに分離します。 ただし、スタックが小さい場合、この測定では広範囲の値を見つけることができるため、MHCは水平軸(パンケーキの直径)が最適な主要コンポーネントであると誤って判断します。
コンポーネントの解釈。 CIMの主な難点は、生成されたコンポーネントを解釈する必要があることであり、場合によっては、選択した方法で変数を組み合わせる必要がある理由を説明するために一生懸命努力する必要があることです。
それにもかかわらず、予備的な一般情報は私たちを助けることができます。 この例では、主要なコンポーネントの食品変数は、製品とそのカテゴリに関する予備知識の助けを組み合わせています。
»本の詳細については、出版社のウェブサイトをご覧ください
» コンテンツ
» 抜粋
ホーカーのクーポンが20%オフ-BigData