
この記事では、食物のある画像の認識の例を使用して、転移学習法の使用方法を説明します。 Machine Learning and Neural Networks for Developersワークショップで、他の機械学習ツールについて説明します。
画像認識のタスクに直面している場合は、既製のサービスを使用できます。 ただし、独自のデータセットでモデルをトレーニングする必要がある場合は、自分で行う必要があります。
画像分類などの一般的なタスクでは、既成のアーキテクチャ(AlexNet、VGG、Inception、ResNetなど)を使用して、データのニューラルネットワークをトレーニングできます。 さまざまなフレームワークを使用したこのようなネットワークの実装はすでに存在するため、この段階では、その動作原理を深く掘り下げることなく、そのうちの1つをブラックボックスとして使用できます。
ただし、ディープニューラルネットワークは、学習の収束のために大量のデータを要求しています。 また、特定のタスクでは、ニューラルネットワークのすべての層を適切にトレーニングするための十分なデータがないことがよくあります。 Transfer Learningはこの問題を解決します。
画像分類のための転移学習
分類に使用されるニューラルネットワークは、通常、最後の層に
N
出力ニューロンを含みます(
N
はクラスの数)。 このような出力ベクトルは、クラスに属する確率のセットとして扱われます。 食品の画像認識タスクでは、クラスの数は元のデータセットのものと異なる場合があります。 この場合、必要な数の出力ニューロンを使用して、この最後のレイヤーを完全に捨てて新しいレイヤーを配置する必要があります
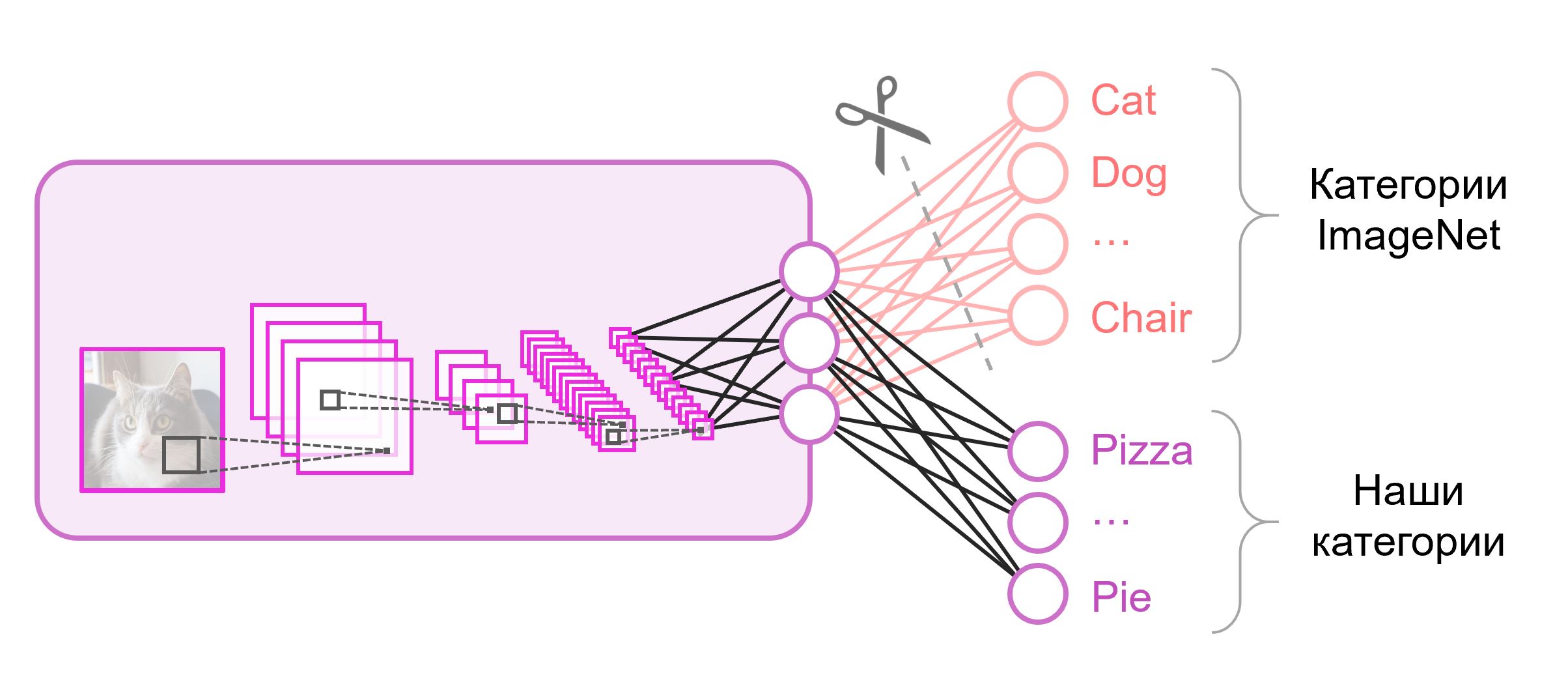
多くの場合、分類ネットワークの最後に、完全に接続されたレイヤーが使用されます。 このレイヤーを置き換えたため、事前にトレーニングされたウェイトを使用しても機能しません。 ランダムな値で重みを初期化し、ゼロから訓練する必要があります。 事前にトレーニングされたスナップショットから、他のすべてのレイヤーの重みをロードします。
モデルをさらにトレーニングするためのさまざまな戦略があります。 以下を使用します。ネットワーク全体をエンドツーエンド( エンドツーエンド )でトレーニングします。事前にトレーニングしたウェイトを修正して、少し調整してデータを調整できるようにします。 このプロセスは微調整と呼ばれます 。
構造部品
問題を解決するには、次のコンポーネントが必要です。
- ニューラルネットワークモデルの説明
- 学習パイプライン
- 干渉パイプライン
- このモデルの事前学習済みの重み
- トレーニングおよび検証データ
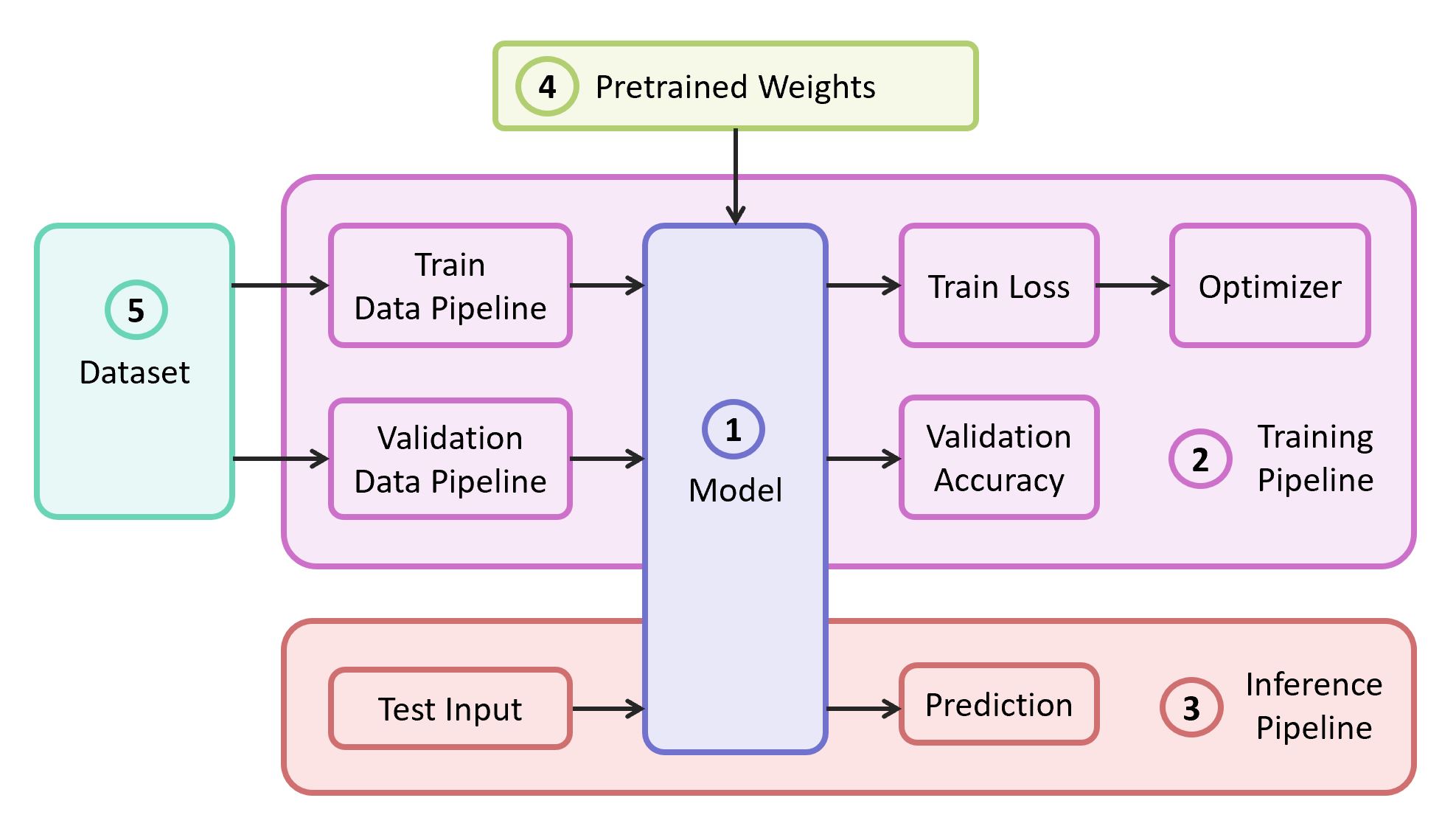
この例では、コンポーネント(1)、(2)、および(3)を、最も軽量なコードを含む独自のリポジトリから取得します。必要に応じて簡単に把握できます。 この例は、一般的なTensorFlowフレームワークに実装されます。 選択したフレームワークに適した事前学習済みの重み(4)は、それらが古典的なアーキテクチャの1つに対応する場合に見つけることができます。 デモンストレーション用のデータセット(5)としてFood-101を使用します。
モデル
モデルとして、古典的なVGGニューラルネットワーク(より正確にはVGG19 )を使用します。 いくつかの欠点にもかかわらず、このモデルはかなり高い品質を示しています。 また、分析も簡単です。 TensorFlow Slimでは、モデルの説明は非常にコンパクトに見えます。
import tensorflow as tf import tensorflow.contrib.slim as slim def vgg_19(inputs, num_classes, is_training, scope='vgg_19', weight_decay=0.0005): with slim.arg_scope([slim.conv2d], activation_fn=tf.nn.relu, weights_regularizer=slim.l2_regularizer(weight_decay), biases_initializer=tf.zeros_initializer(), padding='SAME'): with tf.variable_scope(scope, 'vgg_19', [inputs]): net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') net = slim.max_pool2d(net, [2, 2], scope='pool1') net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') net = slim.max_pool2d(net, [2, 2], scope='pool2') net = slim.repeat(net, 4, slim.conv2d, 256, [3, 3], scope='conv3') net = slim.max_pool2d(net, [2, 2], scope='pool3') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv4') net = slim.max_pool2d(net, [2, 2], scope='pool4') net = slim.repeat(net, 4, slim.conv2d, 512, [3, 3], scope='conv5') net = slim.max_pool2d(net, [2, 2], scope='pool5') # Use conv2d instead of fully_connected layers net = slim.conv2d(net, 4096, [7, 7], padding='VALID', scope='fc6') net = slim.dropout(net, 0.5, is_training=is_training, scope='drop6') net = slim.conv2d(net, 4096, [1, 1], scope='fc7') net = slim.dropout(net, 0.5, is_training=is_training, scope='drop7') net = slim.conv2d(net, num_classes, [1, 1], scope='fc8', activation_fn=None) net = tf.squeeze(net, [1, 2], name='fc8/squeezed') return net
ImageNetでトレーニングされ、TensorFlowと互換性のあるVGG19の重みは、 事前トレーニングモデルセクションのGitHubのリポジトリからダウンロードされます。
mkdir data && cd data wget http://download.tensorflow.org/models/vgg_19_2016_08_28.tar.gz tar -xzf vgg_19_2016_08_28.tar.gz
データセット
トレーニングおよび検証のサンプルとして、101のカテゴリに分割された10万を超える食品の画像を含む公共の食品データセットFood-101を使用します。

データセットをダウンロードして解凍します。
cd data wget http://data.vision.ee.ethz.ch/cvl/food-101.tar.gz tar -xzf food-101.tar.gz
トレーニングのデータパイプラインは、データセットから次を解析する必要があるように設計されています。
- クラスのリスト(カテゴリ)
- チュートリアル:写真へのパスのリストと正解のリスト
- 検証セット:写真へのパスのリストと正解のリスト
データセットの場合、 トレーニングセットと検証セットは個別に分割する必要があります。 Food-101にはすでにそのようなパーティションがあり、この情報は
meta
ディレクトリに保存されます。
DATASET_ROOT = 'data/food-101/' train_data, val_data, classes = data.food101(DATASET_ROOT) num_classes = len(classes)
データ処理を担当するすべての補助機能は、別の
data.py
ファイルに移動されます。
data.py
from os.path import join as opj import tensorflow as tf def parse_ds_subset(img_root, list_fpath, classes): ''' Parse a meta file with image paths and labels -> img_root: path to the root of image folders -> list_fpath: path to the file with the list (eg train.txt) -> classes: list of class names <- (list_of_img_paths, integer_labels) ''' fpaths = [] labels = [] with open(list_fpath, 'r') as f: for line in f: class_name, image_id = line.strip().split('/') fpaths.append(opj(img_root, class_name, image_id+'.jpg')) labels.append(classes.index(class_name)) return fpaths, labels def food101(dataset_root): ''' Get lists of train and validation examples for Food-101 dataset -> dataset_root: root of the Food-101 dataset <- ((train_fpaths, train_labels), (val_fpaths, val_labels), classes) ''' img_root = opj(dataset_root, 'images') train_list_fpath = opj(dataset_root, 'meta', 'train.txt') test_list_fpath = opj(dataset_root, 'meta', 'test.txt') classes_list_fpath = opj(dataset_root, 'meta', 'classes.txt') with open(classes_list_fpath, 'r') as f: classes = [line.strip() for line in f] train_data = parse_ds_subset(img_root, train_list_fpath, classes) val_data = parse_ds_subset(img_root, test_list_fpath, classes) return train_data, val_data, classes def imread_and_crop(fpath, inp_size, margin=0, random_crop=False): ''' Construct TF graph for image preparation: Read the file, crop and resize -> fpath: path to the JPEG image file (TF node) -> inp_size: size of the network input (eg 224) -> margin: cropping margin -> random_crop: perform random crop or central crop <- prepared image (TF node) ''' data = tf.read_file(fpath) img = tf.image.decode_jpeg(data, channels=3) img = tf.image.convert_image_dtype(img, dtype=tf.float32) shape = tf.shape(img) crop_size = tf.minimum(shape[0], shape[1]) - 2 * margin if random_crop: img = tf.random_crop(img, (crop_size, crop_size, 3)) else: # central crop ho = (shape[0] - crop_size) // 2 wo = (shape[0] - crop_size) // 2 img = img[ho:ho+crop_size, wo:wo+crop_size, :] img = tf.image.resize_images(img, (inp_size, inp_size), method=tf.image.ResizeMethod.AREA) return img def train_dataset(data, batch_size, epochs, inp_size, margin): ''' Prepare training data pipeline -> data: (list_of_img_paths, integer_labels) -> batch_size: training batch size -> epochs: number of training epochs -> inp_size: size of the network input (eg 224) -> margin: cropping margin <- (dataset, number_of_train_iterations) ''' num_examples = len(data[0]) iters = (epochs * num_examples) // batch_size def fpath_to_image(fpath, label): img = imread_and_crop(fpath, inp_size, margin, random_crop=True) return img, label dataset = tf.data.Dataset.from_tensor_slices(data) dataset = dataset.shuffle(buffer_size=num_examples) dataset = dataset.map(fpath_to_image) dataset = dataset.repeat(epochs) dataset = dataset.batch(batch_size, drop_remainder=True) return dataset, iters def val_dataset(data, batch_size, inp_size): ''' Prepare validation data pipeline -> data: (list_of_img_paths, integer_labels) -> batch_size: validation batch size -> inp_size: size of the network input (eg 224) <- (dataset, number_of_val_iterations) ''' num_examples = len(data[0]) iters = num_examples // batch_size def fpath_to_image(fpath, label): img = imread_and_crop(fpath, inp_size, 0, random_crop=False) return img, label dataset = tf.data.Dataset.from_tensor_slices(data) dataset = dataset.map(fpath_to_image) dataset = dataset.batch(batch_size, drop_remainder=True) return dataset, iters
モデルトレーニング
モデルトレーニングコードは、次の手順で構成されます。
- トレイン/検証データパイプラインの構築
- 列車/検証グラフの作成(ネットワーク)
- トレイングラフ上の損失の分類関数( クロスエントロピー損失 )の付加
- トレーニング中に検証サンプルの予測の精度を計算するために必要なコード
- スナップショットから事前にトレーニングされたスケールをロードするためのロジック
- トレーニングのためのさまざまな構造の作成
- 学習サイクル自体(反復最適化)
グラフの最後の層は、必要な数のニューロンで構成され、事前に訓練されたスナップショットからロードされるパラメーターのリストから除外されます。
モデルトレーニングコード
import numpy as np import tensorflow as tf import tensorflow.contrib.slim as slim tf.logging.set_verbosity(tf.logging.INFO) import model import data ########################################################### ### Settings ########################################################### INPUT_SIZE = 224 RANDOM_CROP_MARGIN = 10 TRAIN_EPOCHS = 20 TRAIN_BATCH_SIZE = 64 VAL_BATCH_SIZE = 128 LR_START = 0.001 LR_END = LR_START / 1e4 MOMENTUM = 0.9 VGG_PRETRAINED_CKPT = 'data/vgg_19.ckpt' CHECKPOINT_DIR = 'checkpoints/vgg19_food' LOG_LOSS_EVERY = 10 CALC_ACC_EVERY = 500 ########################################################### ### Build training and validation data pipelines ########################################################### train_ds, train_iters = data.train_dataset(train_data, TRAIN_BATCH_SIZE, TRAIN_EPOCHS, INPUT_SIZE, RANDOM_CROP_MARGIN) train_ds_iterator = train_ds.make_one_shot_iterator() train_x, train_y = train_ds_iterator.get_next() val_ds, val_iters = data.val_dataset(val_data, VAL_BATCH_SIZE, INPUT_SIZE) val_ds_iterator = val_ds.make_initializable_iterator() val_x, val_y = val_ds_iterator.get_next() ########################################################### ### Construct training and validation graphs ########################################################### with tf.variable_scope('', reuse=tf.AUTO_REUSE): train_logits = model.vgg_19(train_x, num_classes, is_training=True) val_logits = model.vgg_19(val_x, num_classes, is_training=False) ########################################################### ### Construct training loss ########################################################### loss = tf.losses.sparse_softmax_cross_entropy( labels=train_y, logits=train_logits) tf.summary.scalar('loss', loss) ########################################################### ### Construct validation accuracy ### and related functions ########################################################### def calc_accuracy(sess, val_logits, val_y, val_iters): acc_total = 0.0 acc_denom = 0 for i in range(val_iters): logits, y = sess.run((val_logits, val_y)) y_pred = np.argmax(logits, axis=1) correct = np.count_nonzero(y == y_pred) acc_denom += y_pred.shape[0] acc_total += float(correct) tf.logging.info('Validating batch [{} / {}] correct = {}'.format( i, val_iters, correct)) acc_total /= acc_denom return acc_total def accuracy_summary(sess, acc_value, iteration): acc_summary = tf.Summary() acc_summary.value.add(tag="accuracy", simple_value=acc_value) sess._hooks[1]._summary_writer.add_summary(acc_summary, iteration) ########################################################### ### Define set of VGG variables to restore ### Create the Restorer ### Define init callback (used by monitored session) ########################################################### vars_to_restore = tf.contrib.framework.get_variables_to_restore( exclude=['vgg_19/fc8']) vgg_restorer = tf.train.Saver(vars_to_restore) def init_fn(scaffold, sess): vgg_restorer.restore(sess, VGG_PRETRAINED_CKPT) ########################################################### ### Create various training structures ########################################################### global_step = tf.train.get_or_create_global_step() lr = tf.train.polynomial_decay(LR_START, global_step, train_iters, LR_END) tf.summary.scalar('learning_rate', lr) optimizer = tf.train.MomentumOptimizer(learning_rate=lr, momentum=MOMENTUM) training_op = slim.learning.create_train_op( loss, optimizer, global_step=global_step) scaffold = tf.train.Scaffold(init_fn=init_fn) ########################################################### ### Create monitored session ### Run training loop ########################################################### with tf.train.MonitoredTrainingSession(checkpoint_dir=CHECKPOINT_DIR, save_checkpoint_secs=600, save_summaries_steps=30, scaffold=scaffold) as sess: start_iter = sess.run(global_step) for iteration in range(start_iter, train_iters): # Gradient Descent loss_value = sess.run(training_op) # Loss logging if iteration % LOG_LOSS_EVERY == 0: tf.logging.info('[{} / {}] Loss = {}'.format( iteration, train_iters, loss_value)) # Accuracy logging if iteration % CALC_ACC_EVERY == 0: sess.run(val_ds_iterator.initializer) acc_value = calc_accuracy(sess, val_logits, val_y, val_iters) accuracy_summary(sess, acc_value, iteration) tf.logging.info('[{} / {}] Validation accuracy = {}'.format( iteration, train_iters, acc_value))
トレーニングを開始した後、TensorFlowにバンドルされており、さまざまなメトリックやその他のパラメーターを視覚化するTensorBoardユーティリティを使用して、進捗を確認できます。
tensorboard --logdir checkpoints/
TensorBoardでのトレーニングの最後に、ほぼ完全な画像が表示されます。 トレイン損失の減少と検証精度の増加です。

その結果、
checkpoints/vgg19_food
保存されたスナップショットを取得し
checkpoints/vgg19_food
。これはモデルのテスト中に使用します( 推論 )。
モデルテスト
次に、モデルをテストします。 これを行うには:
- 推論専用に設計された新しいグラフを作成します(
is_training=False
) - スナップショットからトレーニング済みの重みをロードする
- 入力テストイメージをダウンロードして前処理します。
- ニューラルネットワークを介して画像を駆動し、予測を取得しましょう
inference.py
import sys import numpy as np import imageio from skimage.transform import resize import tensorflow as tf import model ########################################################### ### Settings ########################################################### CLASSES_FPATH = 'data/food-101/meta/labels.txt' INP_SIZE = 224 # Input will be cropped and resized CHECKPOINT_DIR = 'checkpoints/vgg19_food' IMG_FPATH = 'data/food-101/images/bruschetta/3564471.jpg' ########################################################### ### Get all class names ########################################################### with open(CLASSES_FPATH, 'r') as f: classes = [line.strip() for line in f] num_classes = len(classes) ########################################################### ### Construct inference graph ########################################################### x = tf.placeholder(tf.float32, (1, INP_SIZE, INP_SIZE, 3), name='inputs') logits = model.vgg_19(x, num_classes, is_training=False) ########################################################### ### Create TF session and restore from a snapshot ########################################################### sess = tf.Session() snapshot_fpath = tf.train.latest_checkpoint(CHECKPOINT_DIR) restorer = tf.train.Saver() restorer.restore(sess, snapshot_fpath) ########################################################### ### Load and prepare input image ########################################################### def crop_and_resize(img, input_size): crop_size = min(img.shape[0], img.shape[1]) ho = (img.shape[0] - crop_size) // 2 wo = (img.shape[0] - crop_size) // 2 img = img[ho:ho+crop_size, wo:wo+crop_size, :] img = resize(img, (input_size, input_size), order=3, mode='reflect', anti_aliasing=True, preserve_range=True) return img img = imageio.imread(IMG_FPATH) img = img.astype(np.float32) img = crop_and_resize(img, INP_SIZE) img = img[None, ...] ########################################################### ### Run inference ########################################################### out = sess.run(logits, feed_dict={x:img}) pred_class = classes[np.argmax(out)] print('Input: {}'.format(IMG_FPATH)) print('Prediction: {}'.format(pred_class))
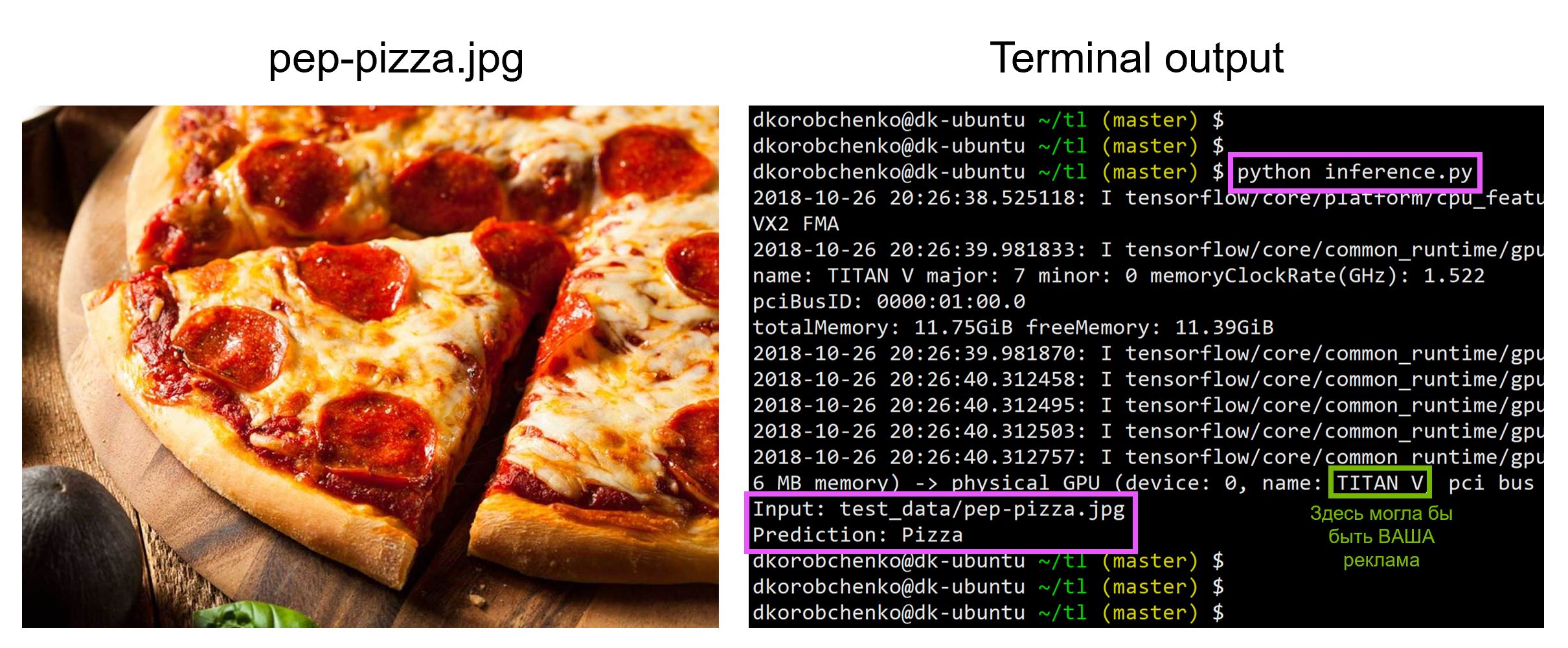
必要なすべてのバージョンのライブラリを備えたDockerコンテナを構築および実行するためのリソースを含むすべてのコードはこのリポジトリにあります。記事を読んだ時点で、リポジトリ内のコードは更新されている可能性があります。
ワークショップ「開発者向けの機械学習とニューラルネットワーク」では、 機械学習の他のタスクを分析し、学生は集中セッションの終わりまでにプロジェクトを発表します。