だから、コミュニティ、私はあなたに3回目を驚かせる機会を与えてください、私はPythonを使用した以前の決定で、私はここで専門家の注意を引くと思ったので、すぐに教えてくれるだろう、なぜこれを行うのか、一般的には正規表現があるこれは動作しますが、これは私たちのpythonが提供できるもので、より高速です。
記事の次のトピックは別のタスクである必要がありますが、いいえ、最初の1つは私に任せませんでした。サイトでの勝利は別の競争でwith冠されたため、さらに迅速な解決策を得るために何ができるかです。
私は平均してこの種の速度の実装を書きました。つまり、誰かがそれをさらに速く解決する方法を知っていて、 彼が沈黙していることに気づかなかったソリューションの90%がまだあることを意味し、以前の2つの記事を見た後、私は言いませんでした:パフォーマンスの問題、それからすべてが明確です-ここでプロローグは適合しません。 しかし、パフォーマンスがあれば、すべてが問題なくなり、弱いハードウェアで実行されるプログラムを想像することはできません。
挑戦する
問題をさらに迅速に解決するために、Pythonがあり、時間がありましたが、Pythonにはより高速なソリューションがありますか?
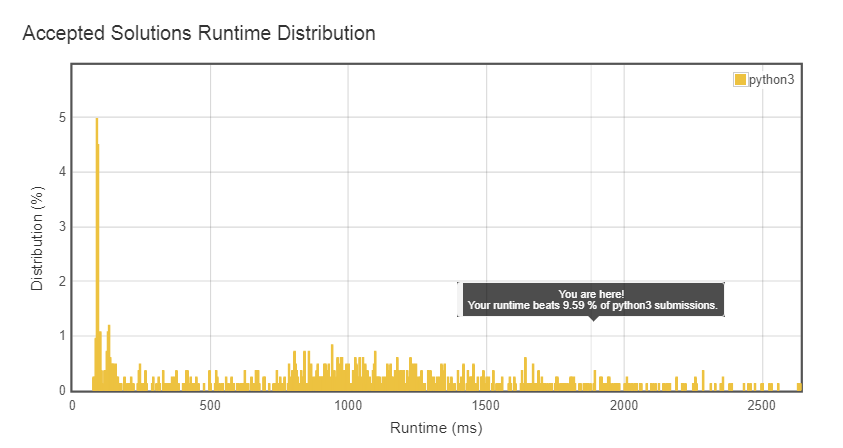
「実行時:2504ミリ秒、ワイルドカードマッチングのPython3オンライン送信の1.55%より高速」と通知されます。
さらに、オンラインで一連の考えがあります。
1レギュラー?
たぶん、正規表現を使用するだけで、より高速なプログラムを作成するオプションがここにあります。
明らかに、pythonは入力行をチェックする正規表現オブジェクトを作成でき、プログラムをテストするためにサイトのサンドボックスで実行することができます。
reをインポートするだけで、そのようなモジュールをインポートできます。面白いので、試してみなければなりません。
迅速なソリューションを作成することは容易ではないことを理解することは容易ではありません。 次のような実装を検索、試行、作成する必要があります。
1.この規則性のオブジェクトを作成し、
2.選択したライブラリの通常のライブラリのルールによって修正されたテンプレートを彼女に掌握し、
3.比較して、答えの準備ができました
出来上がり:
import re def isMatch(s,p): return re.match(s,pat_format(p))!=None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" if ch=='?':res+="." else: res+=ch return res
これは正しいかのように非常に短い解決策です。
実行しようとしていますが、ここにはありませんでした。完全に正しいわけではなく、一部のオプションが適合しないため、テンプレートへの変換をテストする必要があります。
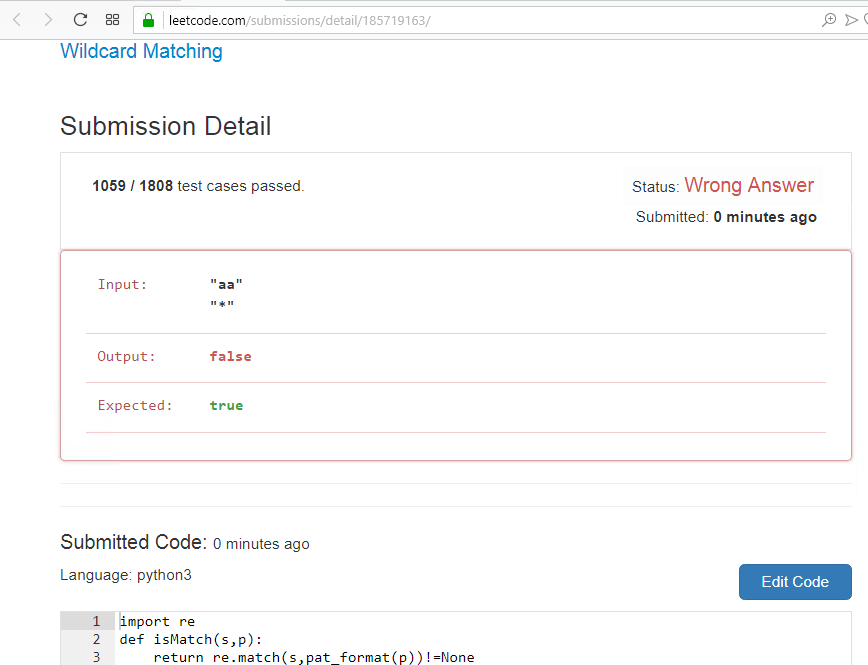
真実はおもしろいです。テンプレートと文字列を混同しましたが、解決策がまとめられ、1058のテストに合格し、ここでのみ失敗しました。
もう一度繰り返しますが、このサイトではテストに慎重に取り組んでおり、それがどのように発生し、以前のものはすべて良いですが、ここでは2つの主要なパラメーターが混同されており、これがTDDの利点です...
そして、このような素晴らしいテキストでは、まだエラーが発生します
import re def isMatch(s,p): return re.match(pat_format(p),s)==None def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
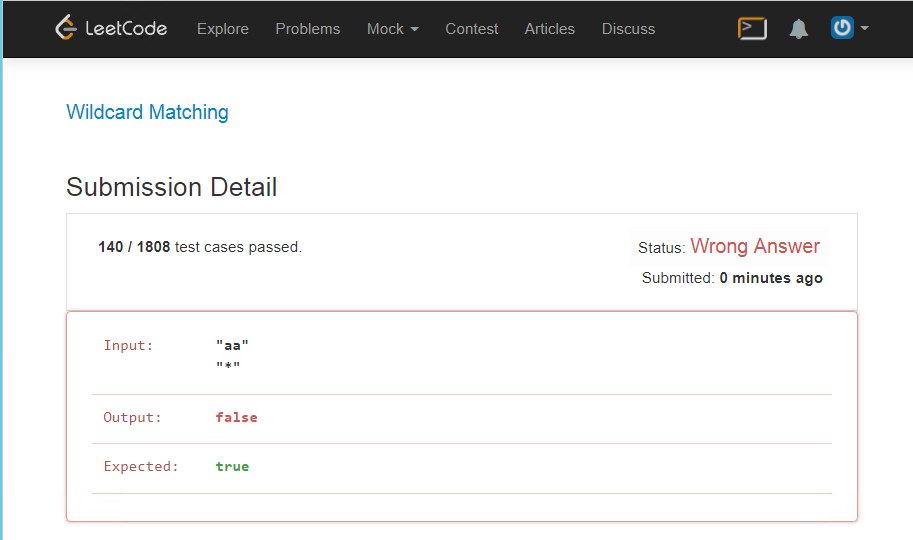
難しい
このタスクはテストで特別にオーバーレイされているため、正規表現を使用したい人はより困難になります。このソリューションの前には、プログラムに論理的なエラーはありませんでしたが、ここでは非常に多くのものを考慮する必要があります。
したがって、正規表現は一致し、最初の結果は行と等しくなります。
勝利
彼に正規表現を使用させるのは簡単ではありませんでしたが、試みは失敗しました。正規人を欺くのはそれほど単純な決定ではありません。 幅優先の検索ソリューションはより高速に機能しました。
以下にそのような実装を示します。
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res.group(0)==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res
これにつながります:
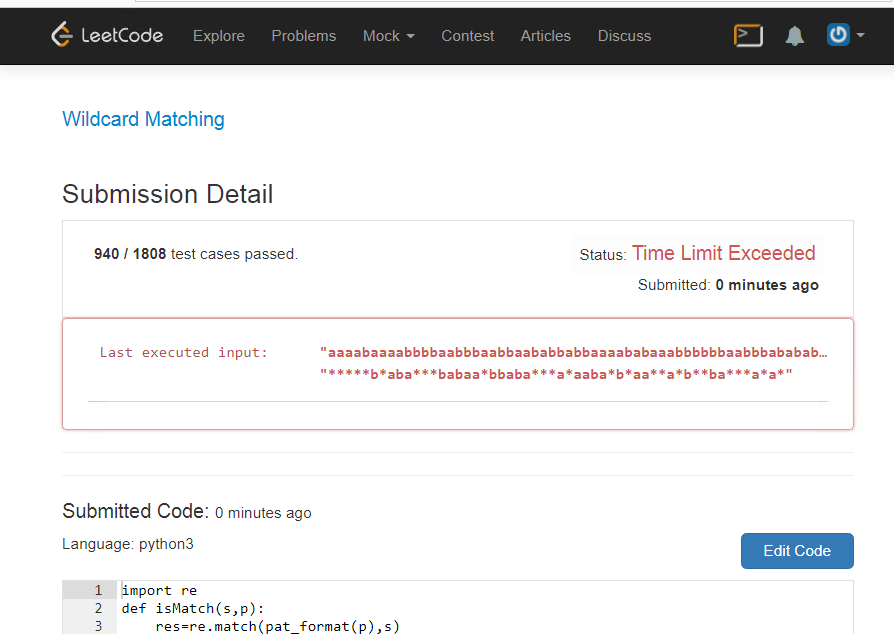
申し立て
親愛なる居住者、これをチェックしようとすると、 Pythonが3つになり 、彼はこのタスクをすぐに完了できません。
import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res ##test 940 import time pt=time.time() print(isMatch("aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba","*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*")) print(time.time()-pt)
"***** B * ABA *** babaa * bbaba *** * AABA * b *のAA ** * B ** BA *** * *") import re def isMatch(s,p): res=re.match(pat_format(p),s) if res is None: return False else: return res[0]==s def pat_format(pat): res="" for ch in pat: if ch=='*':res+="(.)*" else: if ch=='?':res+="." else:res+=ch return res ##test 940 import time pt=time.time() print(isMatch("aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba","*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*")) print(time.time()-pt)
自宅で試すことができます。 奇跡、解決するのに長い時間がかかるだけでなく、フリーズします。
正規表現は、宣言的な外観のサブセットであり、パフォーマンスが低下していますか?
声明は奇妙であり、すべてのファッショナブルな言語にも存在するため、生産性はすごいはずですが、ここでは有限状態マシンが存在しないことはまったく現実的ではありません。
行く
私は1冊の本を読みましたが、それはずっと前でした... Goの最新の言語は非常に迅速に動作しますが、正規表現はどうですか?
私は彼をテストします:
func isMatch(s string, p string) bool { res:=strings.Replace(p, "*", "(.)*", -1) res2:=strings.Replace(res, "?", ".", -1) r, _ := regexp.Compile(res2) fr:=r.FindAllString(s,1) return !(len(fr)==0 || len(fr)!=0 && fr[0]!=s) }
私は認めます、そのような簡潔なテキストを得るのは簡単ではありませんでした、構文は簡単です、siの知識があっても、それを理解するのは簡単ではありません...
これは素晴らしい結果であり、速度は実際にロールオーバーし、合計で約60ミリ秒になりますが、このソリューションが同じサイトでの応答の15%のみより速いことは驚くべきことです。
そしてプロローグはどこですか
正規表現を操作するためのこの忘れられた言語は、Perl Compatible Regular Expressionに基づいたライブラリーを提供することがわかりました。
これは実装方法ですが、別の述語を使用してテンプレート文字列を前処理します。
pat([],[]). pat(['*'|T],['.*'|Tpat]):-pat(T,Tpat),!. pat(['?'|T],['.'|Tpat]):-pat(T,Tpat),!. pat([Ch|T],[Ch|Tpat]):-pat(T,Tpat). isMatch(S,P):- atom_chars(P,Pstr),pat(Pstr,PatStr),!, atomics_to_string(PatStr,Pat), term_string(S,Str), re_matchsub(Pat, Str, re_match{0:Str},[bol(true),anchored(true)]).
そして、ランタイムは問題ありません:
isMatch(aa,a)->ok:0.08794403076171875/sec isMatch(aa,*)->ok:0.0/sec isMatch(cb,?a)->ok:0.0/sec isMatch(adceb,*a*b)->ok:0.0/sec isMatch(acdcb,a*c?b)->ok:0.0/sec isMatch(aab,c*a*b)->ok:0.0/sec isMatch(mississippi,m??*ss*?i*pi)->ok:0.0/sec isMatch(abefcdgiescdfimde,ab*cd?i*de)->ok:0.0/sec isMatch(zacabz,*a?b*)->ok:0.0/sec isMatch(leetcode,*e*t?d*)->ok:0.0009980201721191406/sec isMatch(aaaa,***a)->ok:0.0/sec isMatch(b,*?*?*)->ok:0.0/sec isMatch(aaabababaaabaababbbaaaabbbbbbabbbbabbbabbaabbababab,*ab***ba**b*b*aaab*b)->ok:0.26383304595947266/sec isMatch(abbbbbbbaabbabaabaa,*****a*ab)->ok:0.0009961128234863281/sec isMatch(babaaababaabababbbbbbaabaabbabababbaababbaaabbbaaab,***bba**a*bbba**aab**b)->ok:0.20287489891052246/sec
しかし、いくつかの制限があり、次のテストがもたらしました:
Not enough resources: match_limit Goal (directive) failed: user:assert_are_equal(isMatch(aaaabaaaabbbbaabbbaabbaababbabbaaaababaaabbbbbbaabbbabababbaaabaabaaaaaabbaabbbbaababbababaabbbaababbbba,'*****b*aba***babaa*bbaba***a*aaba*b*aa**a*b**ba***a*a*'),false)
結論として
合計で、質問のみが残りました。 すべてを実装できますが、速度は不十分です。
透明なソリューションは効果的ではありませんか?
誰かが宣言的な正規表現を実装しましたが、どのようなメカニズムがありますか?
そして、そのような課題をどのように気に入っていますか、解決できる問題がありますが、理想的な解決策はどこにありますか?