
規制当局とその要件に関する教育プログラム
電子マネーを発行するには、規制当局のライセンスを取得する必要があります。 たとえばロシアで支払いシステムを開くと、ロシア連邦の中央銀行が規制当局になります。 ePaymentsは英国の支払いシステムであり、当社の規制当局は英国財務省に報告する当局である金融行為監督機構(FCA)です。 FCAは、顧客の確認(KYC)の一連の手順を含むマネーロンダリング防止ポリシー(AML)に準拠することを保証します。
KYCによると、私たちはクライアントが誰であるか、そして彼が社会的に危険なグループに関係しているかどうかをチェックすることにコミットしています。 したがって、2つの義務があります。
- 顧客IDの識別と確認。
- 彼のデータとさまざまなリストとの調整:テロリスト、制裁対象者、政府のメンバー、その他多数。
毎年、KYCの要件はより厳格かつ詳細になっています。 2017年の初めに、検証のないePaymentsのお客様は、引き続き支払いを受けるか、振替を行うことができました。 これは、彼らが身元を確認するまで不可能です。
手動検証
数年前、私たちは自分で対処しました。 ロシア人は身元を確認するためにパスポートの特定のページのスキャンを送信し、住所を確認するために賃貸契約のスキャン、住宅および共同サービスの支払いの領収書を送信しました。 ゲームの論文を覚えていますか? その中で、税関職員として、政府のますます複雑な要件に照らして書類をチェックします。 私たちの顧客部門は毎日仕事でそれを果たしました。

クライアントは、オフィスを訪問せずにリモートで検証されます。 手順を迅速にするために、新しい従業員を雇用しましたが、これは行き詰まりです。 それから、その考えはニューラルネットワークの仕事の一部を委ねるようになりました。 彼女が顔認識にうまく対処できれば、彼女は私たちのタスクに対処します。 ビジネスの観点から、迅速な検証システムは次のことができるはずです。
- 文書を分類します。 身分証明書と居住地の確認書が送られます。 システムは、入り口で受け取ったもの(ロシア連邦市民のパスポート、リース契約など)に回答する必要があります。
- 写真と文書の顔を比較します。 IDカードを使用して自分撮りを送信して、自分自身が支払いシステムに登録されていることを確認するようにお客様にお願いします。
- テキストを抽出します。 スマートフォンで何十ものフィールドに入力するのはあまり便利ではありません。 アプリケーションがあなたのためにすべてをした場合、それははるかに簡単です。
- フォトモンタージュの画像ファイルを確認します。 システムに不正に侵入したい詐欺師を忘れてはなりません。
出力で、システムはクライアントの特定の信頼レベル(高、中、低)を示す必要があります。 このようなグラデーションに焦点を当てて、長期間にわたってお客様を怒らせずに迅速に確認します。
ドキュメント分類子
このモジュールのタスクは、ユーザーが有効な文書を送信し、正確にダウンロードしたものに答えることを確認することです:カザフスタン市民のパスポート、賃貸借契約書、または住宅および公共サービスの支払いの領収書。
分類器は入力データを受け取ります。
- 写真またはスキャン文書
- 居住国
- クライアントによって示されたドキュメントの種類(身分証明書または住所証明)
- 抽出されたテキスト(以下の詳細)
出力では、分類子は受け取ったもの(パスポート、運転免許証など)と、自分が正しい答えにどれだけ自信があるかを報告します。

現在、ソリューションはWide Residual Networkアーキテクチャで実行されています。 私たちはすぐに彼女に来ませんでした。 クイック検証システムの最初のバージョンは、VGGからインスピレーションを受けたアーキテクチャに基づいて機能しました。 彼女には2つの明らかな問題がありました。多数のパラメーター(約1億3,000万)と文書の位置に対する不安定性です。 パラメータが多いほど、そのようなニューラルネットワークをトレーニングするのは難しくなります。知識の一般化が不十分です。 写真の文書は中央に配置する必要があります。そうしないと、写真のさまざまな部分にあるサンプルで分類器をトレーニングする必要があります。 その結果、VGGを放棄し、別のアーキテクチャに切り替えることにしました。
Residual Network(ResNet)はVGGよりもクールでした。 接続をスキップすることで、多数のレイヤーを作成し、高い精度を実現できます。 ResNetには約100万個のパラメーターしかなく、ドキュメントの位置には無関心でした。 画像のどこに配置されていても、このアーキテクチャのソリューションが分類を処理しました。
ファイルを使用してソリューションを完成させている間に、アーキテクチャの新しい修正であるWide Residual Network(WRN)がリリースされました。 ResNetとの主な違いは、深さの点で一歩後退しています。 WRNのレイヤーは少なくなりますが、畳み込みフィルターは多くなります。 現在、これはほとんどのタスクに最適なニューラルネットワークアーキテクチャであり、当社のソリューションはそれで動作します。
いくつかの便利なソリューション
問題番号1。分類器を訓練する必要がありました。 ロシア、カザフ、ベラルーシの多くのパスポートと運転免許証をアップロードする必要がありました。 しかし、もちろん、顧客の書類を受け取ることはできません。 ネットワークにはサンプルがありますが、ニューラルネットワークを正常にトレーニングするにはサンプルが少なすぎます。
解決策。 私たちの技術部門は、各タイプの8000+サンプルのサンプルを生成しました。 ドキュメントテンプレートを作成し、多数のランダムサンプルを乗算します。 次に、その数学モデルと特性(焦点距離、マトリックス解像度など)を考慮して、カメラに対して空間内でドキュメントのランダムな位置を生成します。 人工的な写真を生成するとき、完成したデータセットからランダムな画像が背景として選択されます。 その後、透視歪みのあるドキュメントが画像にランダムに配置されます。 このようなサンプルでは、ニューラルネットワークは十分に訓練されており、「戦闘中」のドキュメントを完全に定義しています。 結果は記事の最後にあります。
問題番号2。コンピューティングリソースとメモリの制限。 大きな画像の入力にディープニューラルネットワークを供給しても意味がありません。 そして、最新のスマートフォンからの写真はまさにそれです。
解決策。 入力に適用する前に、写真は約300x300ピクセルのサイズに圧縮されます。 この許可の画像から、1つの身分証明書を簡単に区別できます。 この問題を解決するために、標準のWide ResNetアーキテクチャを使用できます。
問題番号3。居住地を確認する書類では、すべてがより複雑です。 リース契約または銀行取引明細書は、シート上のテキストによってのみ区別できます。 画像サイズを同じ300x300ピクセルに縮小すると、これらのドキュメントはどれも同じように見えます-判読できないテキストを含むA4シートのように。
解決策。 任意のドキュメントを分類するために、ニューラルネットワーク自体のアーキテクチャを変更しました。 ニューロンの追加の入力層がそこに現れ、出力層に接続されています。 この入力層のニューロンは、 Bag-of-Wordsモデルを使用して以前に認識されたテキストを記述するベクトル入力を受け取ります。
最初に、IDドキュメントを分類するためにニューラルネットワークをトレーニングしました。 任意のドキュメントを分類するために追加のレイヤーで別のネットワークを初期化するときに、訓練されたネットワークの重みを使用しました。 このソリューションは高精度でしたが、テキスト認識には時間がかかりました。 異なるモジュール間の処理速度の違いと分類精度は、表2に記載されています。
顔認識
ドキュメントをチェックする支払いシステムをだます方法は? 他の人のパスポートを借りて、それを使用して登録できます。 クライアントが自分自身を登録していることを確認するために、身分証明書を持ったセルフィーを撮るようにお願いします。 そして、認識モジュールは、ドキュメントの顔と自撮りの顔を比較して回答する必要があります。1人または2人です。
あなたが車であり、車のように考える場合に2つの顔を比較する方法は? 写真を一連のパラメーターに変換し、それらの値を互いに比較します。 これが、顔を認識するニューラルネットワークの仕組みです。 画像を取得し、128次元(たとえば)ベクトルに変換します。 別の顔画像を入力に送信して比較するように依頼すると、ニューラルネットワークは2番目の顔をベクトルに変換し、それらの間の距離を計算します。
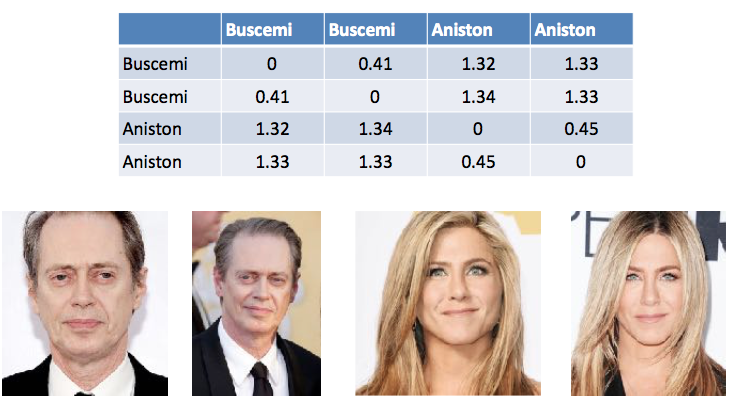
表1.顔認識におけるベクトル間の差を計算する例。 スティーブブシェミは、写真が0.44異なるという点で自分とは異なります。 そしてジェニファー・アニストンから-平均1.33。
もちろん、人の生活とパスポートの見方には違いがあります。 また、ベクトル間の距離を選択し、実際の人でテストして結果を達成しました。 いずれにせよ、最終的な決定はその人によって行われ、システムからのコメントは推奨事項に過ぎません。
テキスト認識
ドキュメントには、分類子がその前にあるものを理解するのに役立つテキストフィールドがあります。 同じパスポートからのテキストが自動的に転送され、誰によって、いつ発行されたかを手動で入力する必要がない場合、ユーザーにとって便利です。 これを行うために、認識とテキスト抽出という次のモジュールを作成しました。
たとえば、ロシア連邦の新しいパスポートなどの一部のドキュメントには、機械可読ゾーン(MRZ)があります。 それを使用すると、情報を簡単に取得できます。白い背景に黒いテキストを読みやすく、認識しやすくなります。 さらに、MRZにはよく知られている形式があるため、必要なデータを簡単に取得できます。

タスクにMRZを含むドキュメントがある場合は、簡単になります。 プロセス全体がコンピュータービジョンの分野にあります。 このゾーンが存在しない場合、テキストを認識した後、1つの興味深い問題を解決する必要があります-理解するために、どのような情報を認識したか? たとえば、「1999年5月15日」は生年月日または発行日ですか? この段階では、間違いを犯すこともあります。 MRZは、一意にデコードされるため優れています。 私たちは常に、MRZのどの情報をどの部分で探すべきかを知っています。 とても便利です。 しかし、MRZは、ネットワークで機能する最も人気のある文書であるロシア連邦のパスポートには載っていませんでした。
テキスト認識には、非常に効果的なソリューションが必要でした。 ほとんどのプロの写真家ではなく、携帯電話のカメラで撮影した画像からテキストを削除する必要があります。 Google Tesseractといくつかの有料ソリューションをテストしました。 何も起きませんでした-それはうまく機能しなかったか、不当に高価でした。 その結果、独自のソリューションの開発を開始しました。 今、彼のテストを終えています。 ソリューションはまともな結果を示しています-以下でそれらについて読むことができます。 フォトモンタージュテストモジュールについては、テストサンプルと「バトル」に関する正確な研究結果が出たときに、少し後で説明します。
結果
このシステムは現在、ロシアの検証用アプリケーションのセグメントでテストされています。 セグメントはランダムサンプリングによって決定され、結果は保存され、特定のクライアントのクライアント部門のオペレーターの決定に対してチェックされます。
| 国 | 分類子タイプ | 精度 | 労働時間、s |
| ロシア | IDカード | 99.96% | 0.41 |
| ロシア | カスタム文書 | 98.62% | 6.89 |
| カザフスタン | IDカード | 99.51% | 0.47 |
| カザフスタン | カスタム文書 | 97.25% | 7.66 |
| ベラルーシ | IDカード | 98.63% | 0.46 |
| ベラルーシ | カスタム文書 | 98.63% | 9.66 |
表2.文書分類子の精度(オペレーターの評価と比較した文書の正しい分類)。
機械学習の大きな利点の1つは、ニューラルネットワークが実際に学習し、ミスを減らすことです。 すぐにセグメントのテストを終了し、検証システムを「戦闘」モードで起動します。 検証申請の30%は、ロシア、カザフスタン、ベラルーシのePaymentに送られます。 見積もりによると、このローンチにより、クライアント部門の負荷が20〜25%削減されます。 将来的には、このソリューションはヨーロッパ諸国にまで拡大される可能性があります。
仕事をお探しですか?
サンクトペテルブルクのオフィスで働く従業員を探しています。 野心的なタスクの大きなプールを持つ国際プロジェクトに興味があるなら、私たちはあなたを待っています。 私たちには、それを実現することを恐れない十分な人がいません。 以下に、hh.ruの求人へのリンクがあります。