KDPV:スペクトル分析タスクのためのDSPノードを通る信号通過の典型的なスキーム。
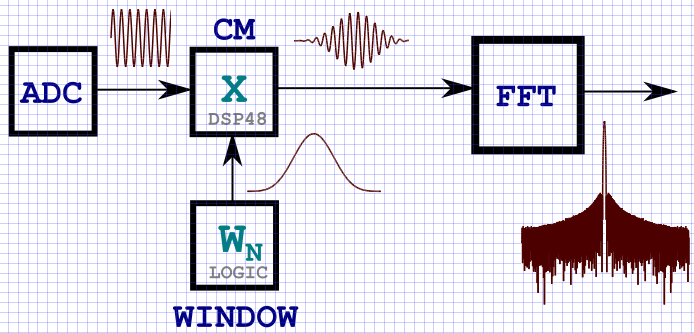
はじめに
「デジタル信号処理」コースから、時間的に無限の正弦波の場合、そのスペクトルは信号周波数でのデルタ関数であることを知っています。 実際には、実時間制限高調波信号のスペクトルは関数〜sin(x)/ xと同等であり、メインローブの幅は信号解析間隔Tの持続時間に依存します。 時間制限は、信号に長方形のエンベロープを掛けることにすぎません。 DSPコースから、時間領域での信号の乗算は周波数領域でのスペクトルの畳み込みであることがわかっているため(逆も同様)、したがって、高調波信号の制限された矩形エンベロープのスペクトルは〜sinc(x)に相当します。 これは、無限の時間間隔で信号を積分することができないという事実も原因であり、有限の合計で表される離散形式のフーリエ変換は、サンプル数によって制限されます。 原則として、最新のFPGAデジタル処理デバイスのFFTの長さは、 8〜数百万ポイントのNFFT値を取ります。 つまり、入力信号のスペクトルは、多くの場合、 NFFTに等しい間隔Tで計算されます。 信号を間隔Tに制限することにより、 Tサンプルの長さの長方形の「ウィンドウ」を設定します。 したがって、結果のスペクトルは、乗算された高調波信号と矩形エンベロープのスペクトルです。 DSPの問題では、さまざまな形状のウィンドウが長い間発明されており、時間領域で信号に重ね合わせると、スペクトル特性を改善できます。 多数のさまざまなウィンドウは、主にウィンドウオーバーレイの主な機能の1つによるものです。 この機能は、サイドローブのレベルと中央ローブの幅の関係で表されます。 よく知られているパターン:サイドローブの抑制が強いほど、メインローブが広くなり、逆もまた同様です。
ウィンドウ関数のアプリケーションの1つ:サイドローブのレベルを抑制することによる、強い信号の背景に対する弱い信号の検出。 DSPタスクのメインウィンドウ関数は、三角形、正弦波、ランチョス、ハン、ハミング、ブラックマン、ハリス、ブラックマンハリスウィンドウ、フラットトップウィンドウ、ナタール、ガウス、カイザーウィンドウなどです。 それらのほとんどは、特定の重みを持つ高調波信号を加算することにより、有限級数で表現されます。 複雑な形状のウィンドウは、指数(ガウスウィンドウ)または修正ベッセル関数(カイザーウィンドウ)を使用して計算されるため、この記事では考慮しません。 ウィンドウ関数の詳細については、従来の記事の最後で説明する文献を参照してください。
次の図は、Matlab CADツールを使用して構築された典型的なウィンドウ関数とそのスペクトル特性を示しています。

実装
記事の冒頭で、KDPVを挿入しました。KDPVは、入力データにウィンドウ関数を乗算する構造図を一般的な用語で示しています。 明らかに、FPGAにウィンドウ関数のストレージを実装する最も簡単な方法は、メモリに書き込み(ブロックRAMBまたは分散分散 -それほど重要ではありません)、その後、信号の入力サンプルが到着したときにデータを周期的に取得することです。 原則として、最新のFPGAでは、内部メモリの量により、比較的小さなサイズのウィンドウ関数を格納できます。その後、ウィンドウ関数に入力信号が乗算されます。 小さいとは、64Kサンプルまでのウィンドウ関数を意味します。
しかし、ウィンドウ関数が長すぎる場合はどうでしょうか? たとえば、1Mの読み取り値。 32ビットビットグリッドで表示されるこのようなウィンドウ関数には、RAMB36KタイプFPGAのザイリンクスクリスタルのNRAMB = 1024 * 1024 * 32/32768 = 1024ブロックメモリセルが必要であると簡単に計算できます。 また、16Mのサンプルの場合は? 16,000個のメモリセル! 単一の最新FPGAにはそれほど多くのメモリがありません。 多くのFPGAでは、これは多すぎます。また、FPGAリソース(そしてもちろん、顧客のお金)を無駄に使用している場合もあります。
この点で、リモートデバイスからブロックメモリに係数を書き込むことなく、ウィンドウ関数サンプルをFPGAに直接オンザフライで生成する方法を考え出す必要があります。 幸いなことに、基本的なものは長い間発明されてきました。 CORDIC ( デジタルデジタル方式)などのアルゴリズムを使用して、式が高調波信号(ブラックマンハリス、ハン、ハミング、ナタールなど)で表される多くのウィンドウ関数を設計することができます。
CORDIC
CORDICは、座標系の回転を計算するための単純で便利な反復法です。これにより、プリミティブの加算およびシフト操作を実行して複雑な関数を計算できます。 CORDICアルゴリズムを使用して、高調波信号sin(x)、cos(x)の値を計算し、位相-atan(x)およびatan2(x、y)、双曲線三角関数を見つけ、ベクトルを回転させ、数の根を抽出するなどができます。
最初は、完成したCORDICカーネルを使用して作業量を減らしたかったのですが、ザイリンクスカーネルには長い間嫌いがありました。 githubのリポジトリを調べた後、私は提示されたすべてのカーネルが多くの理由に適していないことに気付きました(不十分に文書化されていて読めず、普遍的ではなく、特定のタスクまたは要素ベースで
ウィンドウ関数
この記事のフレームワークでは、高調波信号(ハン、ハミング、さまざまな次数のブラックマン・ハリスなど)で表現されるウィンドウ関数のみを実現します。 これには何が必要ですか? 一般的に、ウィンドウを構築するための式は一連の有限長のように見えます。

係数a kの特定のセットと系列のメンバーは、ウィンドウの名前を決定します。 最も人気があり、頻繁に使用されるのは、異なる順序(3〜11)のBlackman-Harrisウィンドウです。 以下は、Blackman-Harrisウィンドウの係数の表です。

原則として、Blackman-Harrisウィンドウセットはスペクトル分析の多くの問題に適用可能であり、GaussやKaiserなどの複雑なウィンドウを使用する必要はありません。 Nattalまたはフラットトップウィンドウは、重量が異なるさまざまなウィンドウですが、Blackman-Harrisと同じ基本原理です。 シリーズのメンバーが多いほど、サイドローブのレベルの抑制が強くなることが知られています(ウィンドウ関数のビット深度の合理的な選択に従います)。 タスクに基づいて、開発者は使用するウィンドウの種類を選択するだけです。
FPGA実装-従来のアプローチ
ウィンドウ関数のすべてのカーネルは、FPGAでデジタル回路を記述するための古典的なアプローチを使用して設計されており、VHDL言語で記述されています。 以下は、作成されたコンポーネントのリストです。
- bh_win_7term -Blackman-Harris 7オーダー、サイドスキャフォールドを最大に抑制するウィンドウ。
- bh_win_5term -Blackman-Harris 5オーダー。フラットトップのウィンドウが含まれます。
- bh_win_4term -Blackman-Harris 4注文。NattalおよびBlackman-Nattalウィンドウが含まれます。
- bh_win_3term -Blackman-Harris 3注文、
- hamming_win-ハミングウィンドウとハンウィンドウ。
Blackman-Harrisウィンドウコンポーネントのソースコードは3桁です。
entity bh_win_3term is generic ( TD : time:=0.5ns; --! Time delay PHI_WIDTH : integer:=10; --! Signal period = 2^PHI_WIDTH DAT_WIDTH : integer:=16; --! Output data width XSERIES : string:="ULTRA" --! for 6/7 series: "7SERIES"; for ULTRASCALE: "ULTRA"; ); port ( RESET : in std_logic; --! Global reset CLK : in std_logic; --! System clock AA0 : in std_logic_vector(DAT_WIDTH-1 downto 0); -- A0 AA1 : in std_logic_vector(DAT_WIDTH-1 downto 0); -- A1 AA2 : in std_logic_vector(DAT_WIDTH-1 downto 0); -- A2 ENABLE : in std_logic; --! Clock enable DT_WIN : out std_logic_vector(DAT_WIDTH-1 downto 0); --! Output DT_VLD : out std_logic --! Output data valid ); end bh_win_3term;
場合によっては、プロジェクトにDSP48E1およびDSP48E2ノードを埋め込むためにUNISIMライブラリを使用しました。これにより、最終的にこれらのブロック内のパイプライン処理により計算速度を上げることができますが、実際に示されているように、 P =のようなものをより速く簡単に書くことができますA * B + Cおよびコードで次のディレクティブを指定します。
attribute USE_DSP of <signal_name>: signal is "YES";
これはうまく機能し、シンセサイザーに数学関数が実装される要素のタイプを厳密に設定します。
Vivado hls
さらに、 Vivado HLSツールを使用してすべてのコアを実装しました。 Vivado HLSの主な利点をリストします:高レベル言語CまたはC ++での高速設計( Time-to-Market )、クロック周波数の概念の欠如による開発ノードの迅速なモデリング、ソリューションの柔軟な構成(リソースとパフォーマンスの観点から)プロジェクト内のプラグマとディレクティブ、および高レベル言語の開発者向けの低エントリしきい値。 主な欠点は、従来のアプローチと比較した場合のFPGAリソースの最適でないコストです。 また、従来の古いRTLメソッド(VHDL、Verilog、SV)で提供される速度を達成することはできません。 さて、最大の欠点はタンバリンと踊ることですが、これはザイリンクスのすべてのCADの特徴です。 (注:Vivado HLSは、 任意精度の利点を使用して曲がって動作するため、Vivado HLSデバッガーと実際のC ++モデルでは、しばしば異なる結果が得られました。)
次の画像は、Vivado HLSで合成されたCORDICカーネルのログを示しています。 これは非常に有益であり、使用されるリソースの量、カーネルユーザーインターフェイス、ループとそのプロパティ、計算の遅延、出力値の計算間隔(シリアルおよびパラレル回路を設計する際に重要)の多くの有用な情報を表示します。

さまざまなコンポーネント(関数)のデータを計算する方法も確認できます。 フェーズ0でフェーズデータが読み取られ、ステージ7および8でCORDICノードの結果が表示されていることがわかります。

Vivado HLSの結果:Cコードから作成された合成RTLカーネル。 ログは、時間分析で、カーネルがすべての制限を正常に通過したことを示しています。

Vivado HLSのもう1つの大きな利点は、Cコードを検証して結果を検証するために使用されるモデルに基づいて、合成されたRTLコードをチェックすることです。 これは原始的なテストかもしれませんが、CとHDLのアルゴリズムの動作を比較するのに非常にクールで便利だと思います。 以下は、Vivado HLSで取得したウィンドウ関数のカーネル関数モデルのシミュレーションを示すVivadoのスクリーンショットです。

したがって、すべてのウィンドウ関数について、VHDLまたはC ++の設計方法に関係なく、同様の結果が得られました。 ただし、最初のケースでは、動作の頻度が高くなり、使用されるリソースの数が少なくなります。2番目のケースでは、最大設計速度が達成されます。 どちらのアプローチにも生命に対する権利があります。
具体的には、さまざまな方法を使用して開発に費やす時間を計算しました。 Vivado HLSでC ++プロジェクトをVHDLよりも12倍高速に実装しました。
アプローチの比較
CORDICコアのHDLとC ++のソースコードを比較します。 前述のように、アルゴリズムは加算、減算、シフトの演算に基づいています。 VHDLでは、次のようになります:3つのデータベクトルがあります-1つは角度の回転を担当し、他の2つはXおよびY軸に沿ったベクトルの長さを決定します。これはsinおよびcosと同等です(wikiの図を参照)。
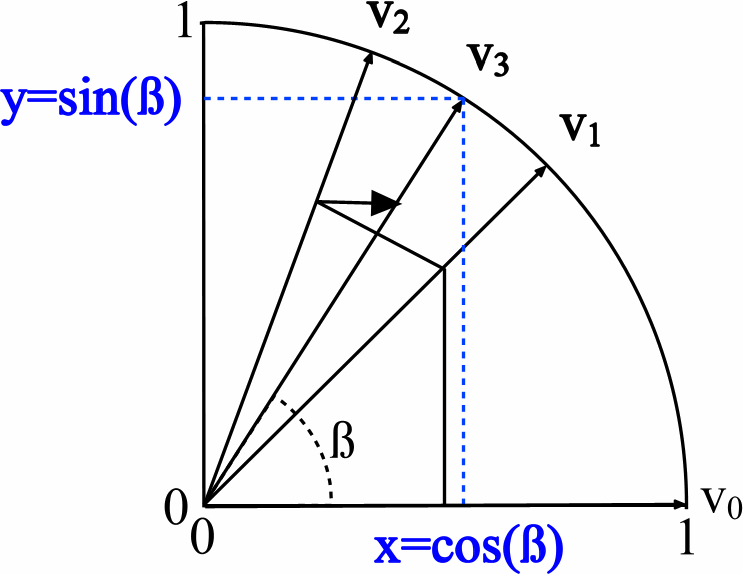
Z値を繰り返し計算することにより、X値とY値が並行して計算されますHDLで出力値を巡回検索するプロセス:
constant ROM_LUT : rom_array := ( x"400000000000", x"25C80A3B3BE6", x"13F670B6BDC7", x"0A2223A83BBB", x"05161A861CB1", x"028BAFC2B209", x"0145EC3CB850", x"00A2F8AA23A9", x"00517CA68DA2", x"0028BE5D7661", x"00145F300123", x"000A2F982950", x"000517CC19C0", x"00028BE60D83", x"000145F306D6", x"0000A2F9836D", x"0000517CC1B7", x"000028BE60DC", x"0000145F306E", x"00000A2F9837", x"00000517CC1B", x"0000028BE60E", x"00000145F307", x"000000A2F983", x"000000517CC2", x"00000028BE61", x"000000145F30", x"0000000A2F98", x"0000000517CC", x"000000028BE6", x"0000000145F3", x"00000000A2FA", x"00000000517D", x"0000000028BE", x"00000000145F", x"000000000A30", x"000000000518", x"00000000028C", x"000000000146", x"0000000000A3", x"000000000051", x"000000000029", x"000000000014", x"00000000000A", x"000000000005", x"000000000003", x"000000000001", x"000000000000" ); pr_crd: process(clk, reset) begin if (reset = '1') then ---- Reset sine / cosine / angle vector ---- sigX <= (others => (others => '0')); sigY <= (others => (others => '0')); sigZ <= (others => (others => '0')); elsif rising_edge(clk) then sigX(0) <= init_x; sigY(0) <= init_y; sigZ(0) <= init_z; ---- calculate sine & cosine ---- lpXY: for ii in 0 to DATA_WIDTH-2 loop if (sigZ(ii)(sigZ(ii)'left) = '1') then sigX(ii+1) <= sigX(ii) + sigY(ii)(DATA_WIDTH+PRECISION-1 downto ii); sigY(ii+1) <= sigY(ii) - sigX(ii)(DATA_WIDTH+PRECISION-1 downto ii); else sigX(ii+1) <= sigX(ii) - sigY(ii)(DATA_WIDTH+PRECISION-1 downto ii); sigY(ii+1) <= sigY(ii) + sigX(ii)(DATA_WIDTH+PRECISION-1 downto ii); end if; end loop; ---- calculate phase ---- lpZ: for ii in 0 to DATA_WIDTH-2 loop if (sigZ(ii)(sigZ(ii)'left) = '1') then sigZ(ii+1) <= sigZ(ii) + ROM_TABLE(ii); else sigZ(ii+1) <= sigZ(ii) - ROM_TABLE(ii); end if; end loop; end if; end process;
C ++、Vivado HLSでは、コードはほとんど同じように見えますが、レコードは何倍も短くなります。
// Unrolled loop // int k; stg: for (k = 0; k < NWIDTH; k++) { #pragma HLS UNROLL if (z[k] < 0) { x[k+1] = x[k] + (y[k] >> k); y[k+1] = y[k] - (x[k] >> k); z[k+1] = z[k] + lut_angle[k]; } else { x[k+1] = x[k] - (y[k] >> k); y[k+1] = y[k] + (x[k] >> k); z[k+1] = z[k] - lut_angle[k]; } }
どうやら、シフトと追加の同じサイクルが使用されます。 ただし、デフォルトでは、C ++言語向けに、Vivado HLSのすべてのループは「折りたたみ」され、順次実行されます。 HLS UNROLLまたはHLS PIPELINEプラグマの導入により、シリアル計算がパラレル計算に変換されます。 これにより、FPGAリソースが増加しますが、各クロックサイクルで新しい値を計算してコアに送信できます。
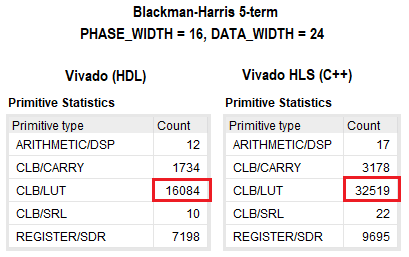
VHDLおよびC ++でのプロジェクトの合成結果を下図に示します。 論理的に見ると、違いは2倍であり、従来のアプローチを支持しています。 その他のFPGAリソースの場合、差異はわずかです。 C ++でのプロジェクトの最適化には深く入りませんでしたが、さまざまなディレクティブを設定したり、コードを部分的に変更したりすることで、使用するリソースの数を減らすことができます。 どちらの場合も、タイミングは〜350 MHzの特定のコア周波数で収束しました。
実装機能
計算は固定小数点形式で実行されるため、ウィンドウ関数にはFPGAでDSPシステムを設計する際に考慮しなければならない多くの機能があります。 たとえば、ウィンドウ関数データのビット深度が大きいほど、ウィンドウオーバーレイの精度が向上します。 一方、ウィンドウ関数のビット深度が不十分な場合、結果の波形に歪みが生じ、スペクトル特性の品質に影響します。 たとえば、2 ^ 20 = 1Mサンプルの期間の信号を乗算する場合、ウィンドウ関数には少なくとも20ビットが必要です。
おわりに
この記事では、外部メモリまたはFPGAブロックメモリを使用せずにウィンドウ関数を設計する1つの方法を示します。 FPGA(および場合によってはDSPブロック)の論理リソースのみを使用する方法が示されています。 CORDICアルゴリズムを使用すると、任意のビット深度(理由内)、任意の長さ、次数のウィンドウ関数を取得できるため、ウィンドウのほぼすべてのスペクトル特性のセットを取得できます。
作品の1つでは、約375 MHzの周波数で1Mサンプルに対して5桁と7桁のブラックマン・ハリス窓関数の安定して動作するカーネルを取得し、約400 MHzの周波数でCORDICに基づいてFFTの回転係数のジェネレーターを作成することができました。 使用済みFPGAクリスタル:Kintex Ultrascale +(xcku11p-ffva1156-2-e)。
githubプロジェクトへのリンクはこちら 。 プロジェクトには、Matlabの数学モデル、VHDLのウィンドウ関数とCORDICのソースコード、Vivado HLSのC ++のリストされたウィンドウ関数のモデルが含まれています。
有用な記事
- DSPLibウィンドウ関数
- 一部のDSPlibウィンドウ関数
- 拡張ウィンドウフィルタリングWiki
- CORDICに関するWiki記事
- Vivado HLSユーザーガイド
- Habrのスペクトル分析に関する記事
DSPに関する非常に人気のある本、 Ayficher E.、Jervis B.のデジタル信号処理もお勧めします。 実用的なアプローチ
ご清聴ありがとうございました!