
Pythonでの完全な機械学習のウォークスルー:パート3
多くの人々は、機械学習モデルがブラックボックスであることを好まない:私たちはそれらにデータを入れ、説明なしで答えを得る-しばしば非常に正確な答え この記事では、作成したモデルがどのように予測を行い、それが解決している問題について何を伝えることができるかを理解しようとします。 そして、機械学習プロジェクトの最も重要な部分についての議論で締めくくります。これまでに行ったことを文書化し、結果を提示します。
最初の部分では、データのクレンジング、探索的分析、設計、および機能の選択について検討しました。 第2部では 、欠落データの充填、機械学習モデルの実装と比較、相互検証を使用したランダム検索を使用したハイパーパラメトリックチューニング、および最終的に結果のモデルの評価について検討しました。
すべてのプロジェクトコードはGitHubにあります。 そして、この記事に関連する3番目のJupyter Notebookはここにあります 。 プロジェクトに使用できます!
そのため、機械学習、より正確には教師付き回帰を使用して、問題の解決に取り組んでいます。 ニューヨークの建物のエネルギーデータに基づいて、エネルギースタースコアを予測するモデルを作成しました。 テストデータに基づいて、9.1ポイント以内(1〜100の範囲)で予測できる「 勾配ブースティングベースの回帰 」モデルを取得しました。
モデルの解釈
勾配ブースティング回帰は、モデルの解釈可能性スケールのほぼ中央にあります。モデル自体は複雑ですが、数百のかなり単純な決定木で構成されています 。 モデルの仕組みを理解するには、次の3つの方法があります。
- 症状の重要性を評価してください。
- 決定木のいずれかを視覚化します。
- LIMEメソッド-ローカルで解釈可能なモデルに依存しない説明、ローカルで解釈されるモデルに依存しない説明を適用します。
最初の2つの方法はツリーアンサンブルの特徴であり、3番目の方法はその名前から理解できるように、あらゆる機械学習モデルに適用できます。 LIMEは比較的新しいアプローチであり、 機械学習の操作を説明しようとする大きな前進です。
症状の重要性
標識の重要性により、予測の目的で各標識の関係を確認できます。 この方法の技術的な詳細は複雑です(平均減少不純物が測定されるか、形質が含まれることにより誤差が減少します )が、相対値を使用して、より適切な形質を理解できます。 Scikit-Learnでは、ツリーベースの「生徒」アンサンブルから属性の重要性を抽出できます。
以下のコードでは、
model
はトレーニングされたモデルであり、
model.feature_importances_
を使用して、属性の重要性を判断できます。 次に、それらをPandasデータフレームに送信し、10個の最も重要な機能を表示します。
import pandas as pd # model is the trained model importances = model.feature_importances_ # train_features is the dataframe of training features feature_list = list(train_features.columns) # Extract the feature importances into a dataframe feature_results = pd.DataFrame({'feature': feature_list,'importance': importances}) # Show the top 10 most important feature_results = feature_results.sort_values('importance',ascending = False).reset_index(drop=True) feature_results.head(10)
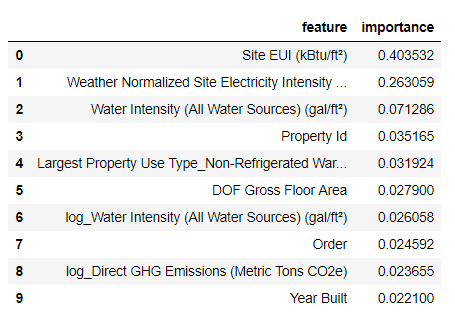
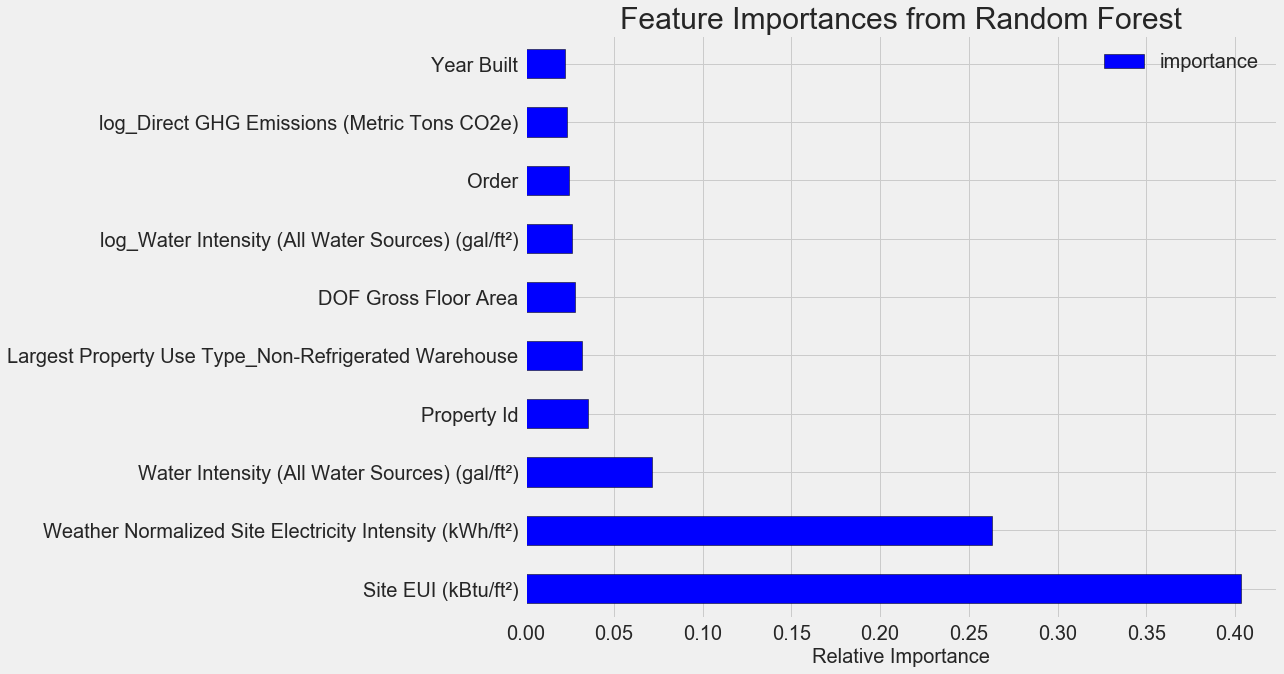
最も重要な機能は、
Site EUI
( エネルギー消費強度 )および
Weather Normalized Site Electricity Intensity
であり、全体の重要度の66%以上を占めています。 すでに3番目の属性で重要性が大幅に低下しています。これは 、64個すべての属性を使用して高い予測精度を達成する必要がないことを示唆しています( Jupyterノートブックでは、この理論は10個の最も重要な属性のみを使用してテストされており、モデルはあまり正確ではありませんでした)。
これらの結果に基づいて、最初の質問の1つに最終的に答えることができます。エネルギースタースコアの最も重要な指標は、サイトEUIと天気正規化サイト電力強度です。 標識の重要性のジャングルに深く入り込むことはありませんが、それらによってモデルによる予測メカニズムを理解し始めることができると言ってみましょう。
単一の決定木の可視化
勾配ブースティングに基づいて回帰モデル全体を理解することは困難であり、個々の決定木については言えません。
Scikit-Learn- export_graphviz
を使用して、ツリーを視覚化できます。 最初にアンサンブルからツリーを抽出し、それをドットファイルとして保存します。
from sklearn import tree # Extract a single tree (number 105) single_tree = model.estimators_[105][0] # Save the tree to a dot file tree.export_graphviz(single_tree, out_file = 'images/tree.dot', feature_names = feature_list)
Graphvizビジュアライザーを使用して、コマンドラインに入力してドットファイルをpngに変換します。
dot -Tpng images/tree.dot -o images/tree.png
完全な決定木を得ました:

ちょっと面倒! このツリーの深さはわずか6層ですが、すべての遷移を追跡するのは困難です。
export_graphviz
関数
export_graphviz
を変更して、ツリーの深さを2つのレイヤーに制限しましょう。
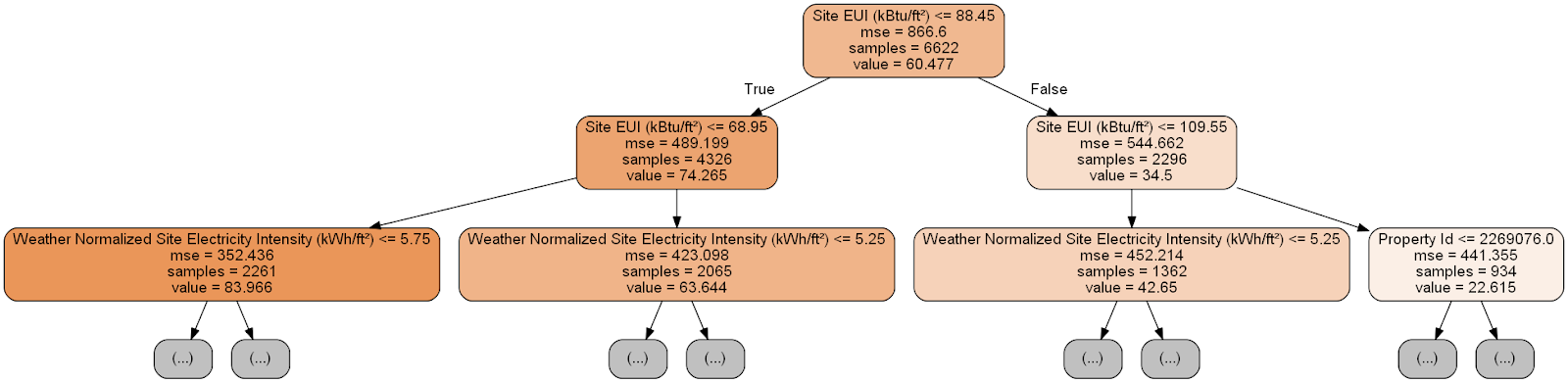
ツリーの各ノード(四角形)には4つの行が含まれています。
- 特定の次元の兆候の1つの値に関する質問:このノードを終了する方法によって異なります。
-
Mse
は、ノードのエラーの尺度です。 -
Samples
-ノード内のデータサンプル(測定)の数。 -
Value
-ノード内のすべてのデータサンプルの目標評価。
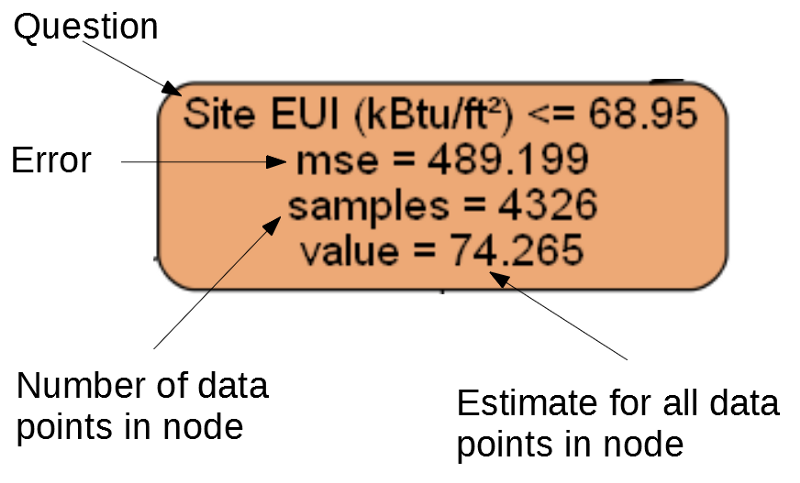
別のノード。
(葉には2から4のみが含まれます。これは、最終グレードを表し、子ノードがないためです)。
デシジョンツリー内の特定の測定値の予測は、最上位ノード(ルート)から開始され、ツリーの下に向かって下降します。 各ノードで、質問「はい」または「いいえ」に答える必要があります。 たとえば、前の図は「建物のサイトEUIは68.95以下ですか?」と尋ねています。そうであれば、アルゴリズムは右の子ノードに進み、そうでない場合は左に進みます。
この手順は、アルゴリズムが最後のレイヤーの葉ノードに到達するまで、ツリーの各レイヤーで繰り返されます(これらのノードは、ツリーが縮小された図には示されていません)。 ワークシートのディメンションの予測は
value
です。 複数の測定値がシートに到達した場合、それぞれが同じ予測を受け取ります。 ツリーの深さが増すと、トレーニングデータのエラーが減少します。葉が多くなり、サンプルがより慎重に分割されるためです。 ただし、ツリーが深すぎると、トレーニングデータの再トレーニングにつながり、テストデータを一般化できません。
2番目の記事では、各ツリーを制御するモデルハイパーパラメーターの数、たとえば、ツリーの最大深さと各シートに必要なサンプルの最小数を設定します。 これらの2つのパラメーターは、過剰学習と過少学習のバランスに強く影響し、決定ツリーを視覚化することで、これらの設定がどのように機能するかを理解できます。
モデル内のすべての木を調べることはできませんが、それらの1つを分析すると、各「学生」がどのように予測するかを理解するのに役立ちます。 このフローチャートベースの方法は、人が決定を下す方法に非常に似ています。 デシジョンツリーのアンサンブルは 、多数の個々のツリーの予測を結合します。これにより、変動の少ない、より正確なモデルを作成できます。 このようなアンサンブルは非常に正確で説明が簡単です。
ローカル解釈可能モデル依存説明(LIME)
モデルがどのように「考えている」かを把握するための最後のツール。 LIMEでは、機械学習モデルに対して単一の予測がどのように生成されるかを説明できます。 これを行うには、ローカルで、測定の次に、線形回帰などの単純なモデルに基づいて単純化されたモデルが作成されます(詳細については、この作業で説明します : https : //arxiv.org/pdf/1602.04938.pdf )。
LIMEメソッドを使用して、モデルの完全に誤った予測を研究し、それが間違っている理由を理解します。
まず、この誤った予測を見つけます。 これを行うには、モデルをトレーニングし、予測を生成し、最大の誤差を持つ値を選択します。
from sklearn.ensemble import GradientBoostingRegressor # Create the model with the best hyperparamters model = GradientBoostingRegressor(loss='lad', max_depth=5, max_features=None, min_samples_leaf=6, min_samples_split=6, n_estimators=800, random_state=42) # Fit and test on the features model.fit(X, y) model_pred = model.predict(X_test) # Find the residuals residuals = abs(model_pred - y_test) # Extract the most wrong prediction wrong = X_test[np.argmax(residuals), :] print('Prediction: %0.4f' % np.argmax(residuals)) print('Actual Value: %0.4f' % y_test[np.argmax(residuals)])
予測:12.8615
実際の値:100.0000
次に、説明者を作成し、それにトレーニングデータ、モード情報、トレーニングデータのラベル、および属性の名前を付けます。 これで、観測データと予測関数を説明者に伝え、予測エラーの理由を説明するように依頼することができます。
import lime # Create a lime explainer object explainer = lime.lime_tabular.LimeTabularExplainer(training_data = X, mode = 'regression', training_labels = y, feature_names = feature_list) # Explanation for wrong prediction exp = explainer.explain_instance(data_row = wrong, predict_fn = model.predict) # Plot the prediction explaination exp.as_pyplot_figure();
予測説明チャート:
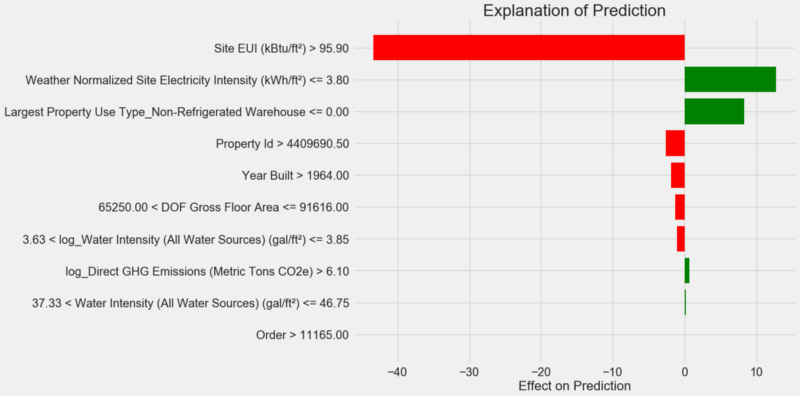
図の解釈方法:Y軸に沿った各レコードは変数の1つの値を示し、赤と緑のバーは予測に対するこの値の影響を反映しています。 たとえば、上のレコードによると、
Site EUI
の影響は95.90を超えており、その結果、予測から約40ポイントが差し引かれています。 2番目のレコードによると、
Weather Normalized Site Electricity Intensity
影響は3.80未満であるため、予測に約10ポイントが追加されます。 最終的な予測は、リストされた各値の切片と効果の合計です。
別の方法で見て、
.show_in_notebook()
メソッドを呼び出しましょう:
# Show the explanation in the Jupyter Notebook exp.show_in_notebook()

モデルによる意思決定プロセスは左側に示されています。各変数の予測への影響が視覚的に表示されます。 右側の表は、特定の測定の変数の実際の値を示しています。
この場合、モデルは約12ポイントを予測しましたが、実際には100でした。最初は、なぜこれが起こったのか疑問に思うかもしれませんが、説明を分析すると、これは極端な大胆な仮定ではなく、特定の値に基づいた計算結果であることがわかります
Site EUI
は比較的高く、EUIの影響を強く受けているため、低いエネルギースタースコアが期待できます。 しかし、この場合、実際には建物が最高のエナジースタースコア-100を獲得したため、このロジックは誤りであることが判明しました。
モデルのエラーは気分を害する可能性がありますが、そのような説明はモデルが間違っていた理由を理解するのに役立ちます。 さらに、説明のおかげで、高いサイトEUI値にもかかわらず、建物が最高のスコアを獲得した理由を掘り下げることができます。 モデルエラーの分析を開始しなければ、おそらく私たちの注意をそらすような新しいタスクを学習するでしょう。 このようなツールは理想的ではありませんが、モデルの理解を大幅に促進し、 より良い決定を下すことができます。
作業の文書化と結果の提示
多くのプロジェクトは、ドキュメントとレポートにほとんど注意を払いません。 あなたは世界で最高の分析を行うことができますが、結果を適切に提示しなければ、それらは重要ではありません!
データ分析プロジェクトを文書化することで、他の人がプロジェクトを再現または収集できるように、データとコードのすべてのバージョンをパックします。 コードは書かれているよりも頻繁に読み取られることを忘れないでください。したがって、私たちの作業は、他の人たち、そして数か月以内に戻った場合、私たちにとって明らかであるはずです。 したがって、コードに有用なコメントを挿入し、決定を説明してください。 Jupyter Notebookは文書化に最適なツールです。最初にソリューションを説明し、次にコードを表示できます。
また、Jupyter Notebookは、他の専門家と対話するための優れたプラットフォームです。 ノートブックの拡張機能を使用すると、最終レポートからコードを隠すことができます。信じることがどれほど困難であっても、誰もがドキュメント内の多くのコードを見たくないからです。
絞りたくないが、すべての詳細を表示したい場合があります。 ただし、プロジェクトを提示するときは聴衆を理解し、 それに応じてレポートを準備することが重要です。 プロジェクトの本質の概要の例を次に示します。
- ニューヨークの建物のエネルギー消費に関するデータを使用して、9.1ポイントの誤差でエネルギースターポイントの数を予測するモデルを構築できます。
- サイトEUIと天気正規化電力強度は、予測に影響する主な要因です。
Jupyter Notebookに詳細な説明と結論を書きましたが、PDFの代わりに.texファイルをLatexに変換し、それをtexStudioで編集し、 結果のバージョンをPDF に変換しました。 実際、JupyterからPDFへのデフォルトのエクスポート結果はかなりまともですが、わずか数分の編集で大幅に改善できます。 さらに、ラテックスは、所有するのに役立つ強力なドキュメント作成システムです。
最終的に、私たちの仕事の価値は、それが下す決定に基づいて決定されます。そして、「人によって商品を届ける」ことができることが非常に重要です。 正しく文書化することで、他の人が結果を再現し、フィードバックを提供できるようになります。これにより、経験を積んで、将来得られる結果に頼ることができます。
結論
一連の出版物では、機械学習教育プロジェクトを最初から最後まで取り上げています。 データをクリアすることから始めて、モデルを作成し、最後にそれを解釈する方法を学びました。 機械学習プロジェクトの一般的な構造を思い出してください。
- データのクリーニングとフォーマット。
- 探索的データ分析。
- 機能の設計と選択。
- いくつかの機械学習モデルのメトリックの比較。
- 最適なモデルのハイパーパラメトリックチューニング。
- テストデータセットでの最適なモデルの評価。
- モデルの結果の解釈。
- 結論と十分に文書化されたレポート。
一連のステップはプロジェクトによって異なる場合があり、機械学習は線形ではなく反復的であることが多いため、このガイドは今後役立ちます。 自信を持ってプロジェクトを実装できるようになることを願っていますが、覚えておいてください。 あなたが助けを必要とするなら、あなたは助言を与えられる多くの非常に役に立つコミュニティがあります。
これらのソースはあなたを助けることができます:
- Scikit-Learnおよび Tensorflowによる ハンズオン機械学習 ( この本のJupyterノートブックは無料でダウンロードできます)!
- 統計学習の紹介
- Kaggle:データサイエンスと機械学習のホーム
- Datacamp :データ分析プログラミングの実践のための良いガイド。
- Coursera :多くのトピックに関する無料および有料コース。
- Udacity :プログラミングとデータ分析に関する有料コース。