

データがディレクトリC:\ workshop \ habrahabrにEXCEL形式で保存されているとします。 スプレッドシートをインポートし、そこからスライスを作成し、SAS関数を使用して新しい計算列を作成し、このデータセットを2つに分割します。
スプレッドシートをインポートしてフィルターを設定する

Excelファイルは上記のディレクトリに保存され、次のようになります。
ファイルスニペット:

PROC IMPORTプロシージャを適用して、スプレッドシートをSASデータセットに変換します。
options validvarname=v7; proc import datafile="C:\workshop\habrahabr\company.xlsx" dbms=xlsx out=company replace; getnames=yes; run;
validvarname = V7オプションは、SASの観点から正しいフィールド名を設定します。すべての無効な文字をアンダースコアに置き換えます。 変数の命名規則はレッスン1にあります。
外部ファイルの読み取り時にフィルターをすぐに設定します。たとえば、完了日を逃さない観測のみを選択します。 whereパラメーターの構文に注意してください。
options validvarname=v7; proc import datafile="C:\workshop\habrahabr\company.xlsx" dbms=xlsx out=company (where=(End_Date not is missing)) replace; getnames=yes; run;
PROC IMPORTステップ演算子を詳細に検討してください。
データファイル-外部ファイルのフルパスと名前を定義します
Dbms-インポートするデータ型を定義します。
Out -1レベルまたは2レベルのSAS名(ライブラリ名とデータセット名)でSAS出力データセットを識別します。
置換 -既存のSASデータセットを上書きします。
Getnames -PROC IMPORTが入力外部ファイルの最初の行のデータ値からSAS変数名を生成するかどうかを示します。
PROC IMPORTステップを実行して、ログを調べます。

結果のSASデータセットを印刷します。
proc print data=work.company noobs; run;
PROC PRINTプロシージャの出力は次のとおりです。
フラグメント:
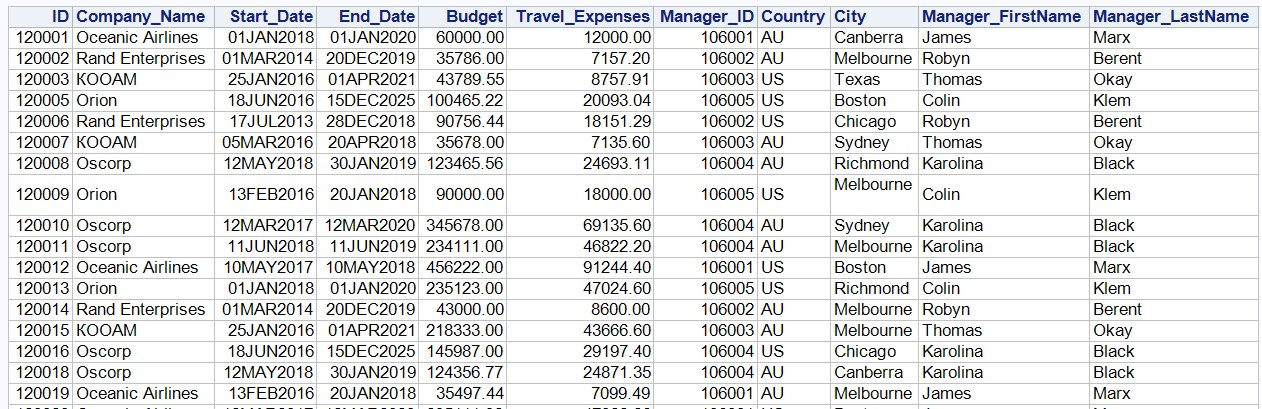
また、SAS UEでは、[結果]タブを使用して、インポートされたSASデータセットに慣れることができます。

SASデータセットの読み取り

SASデータセットの読み取りは、 SETステートメントを使用してDATAステップで実装されます。
SETステートメントの一般的な構文を検討してください。
SET<SAS-data-set(s) <(data-set-options(s) )> > <options>;
SETステートメントでデータセットを指定しない場合、最後に作成されたSASデータセットから観測値を読み取ります。
SETステートメントでは、複数のデータセットを指定できます;この場合、SASデータセットは1つ下に追加されます(SQLのUNIONと同様)。
また、DATAステップでは、2つのSETステートメントを使用できます。この場合、テーブルは共通の列で結合されます。 たとえば、 この記事の 2つのSETステートメントについて詳しく読むことができます。
SASデータセットのコピーを作成する最も簡単なコードは次のとおりです。
data company1; set company; run;
SASデータセット記述子の構成
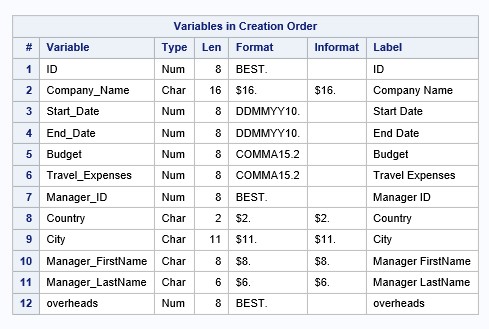
PROC CONTENTSプロシージャを使用してSASデータセット記述子を調べることができます( レッスン2を参照 )。 このチュートリアルでは、 PROC DATASETSプロシージャを使用して記述子コンポーネントを出力します。
proc datasets library=work nolist; contents data=company order=varnum; quit;
結果の断片:
Travel_ExpensesおよびBudget変数の定数形式を設定します。
data company; set company; format Travel_Expenses Budget dollar10.2; run;
SASデータセットの属性を確認します。
proc datasets library=work nolist; contents data=company order=varnum; quit;
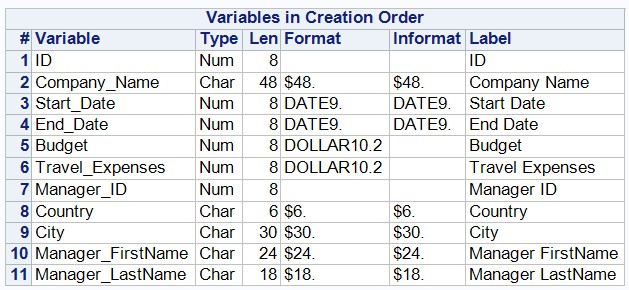
計算列の作成
すべてのSAS関数は、 SAS 9.4関数およびCALLルーチン:リファレンス、第5版で調べることができます。
さらに、特定のタスクを実行するための適切な機能がない場合は、 PROC FCMPプロシージャを使用して独自の機能を作成できます。
このレッスンでは、YRDIF、SUM、およびCATSの3つの機能について説明します。
年単位の日付の差を計算するには、YRDIF関数を使用します 。
SAS形式の日付は、1960年1月1日から始まる日数であることを思い出させてください( レッスン1を参照 )。 提示されたデータで、実行時間を計算する必要があります。
data company1; set work.company; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); format Travel_Expenses Budget dollar10.2 Lead_Time 3.1; run;
Lead_Time変数に3.1形式を使用しているため、レポートの計算値(!)は小数点以下1桁に丸められていることに注意してください。 フォーマット演算子は 、SASデータセットの値を変更しません !
結果の断片:
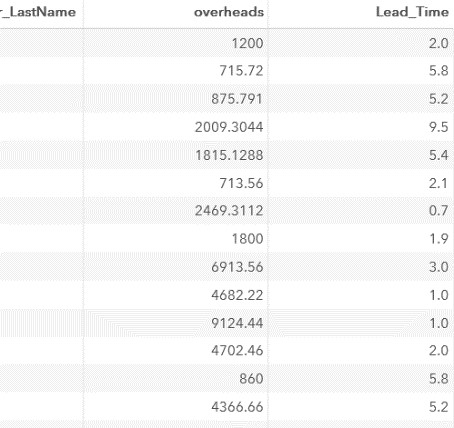
次に、旅費なしの作業コストを計算します。
data company1; set work.company; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; run;
結果の断片:
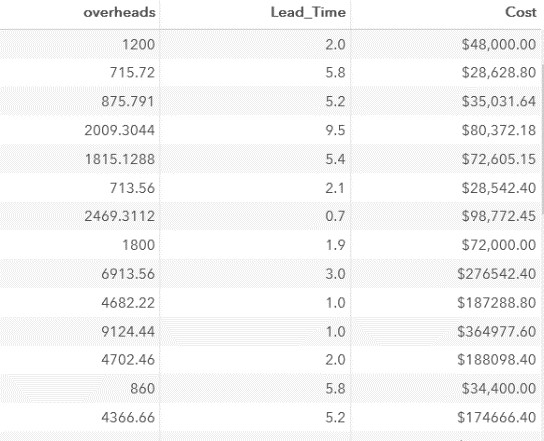
タスクの一部として、関数を使用せずに旅費を考慮せずに作業コストを計算しました。 テーブルに欠損値はありません。変数(BudgetまたはTravel_Expenses)のいずれかに欠損値がある場合、結果は「ミッション」でした。
例:
テストデータセットを作成します。
data test; input Budget Travel_Expenses; datalines; 12345 233 . 345 12543 . ;
変数Budget Travel_Expensesの差を計算します
data test; set test; value=Budget-Travel_Expenses; run;
このステップの結果:
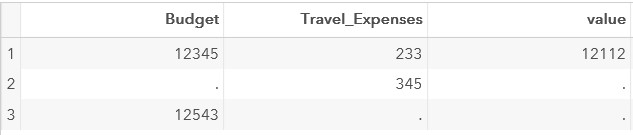
正しい結果を取得するには、 SUM関数を使用できます。
この関数は、 記述統計関数のカテゴリーに属します。 記述統計関数は欠損値を無視します。
SUMを介したコードの記述:
data test; set test; value=sum(Budget,-Travel_Expenses); run;
この場合、ステップの結果は次のとおりです。
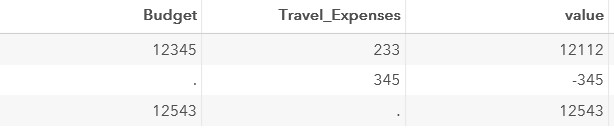
3番目の計算列は、マネージャーのメールアドレスです。 列Manager_FirstName、Manager_LastNameおよび値habr .comから「アセンブル」できます。
CATS関数を使用して、テキスト値を1行に結合できます。
data company1; set work.company; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com'); format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; run;
結果の断片:
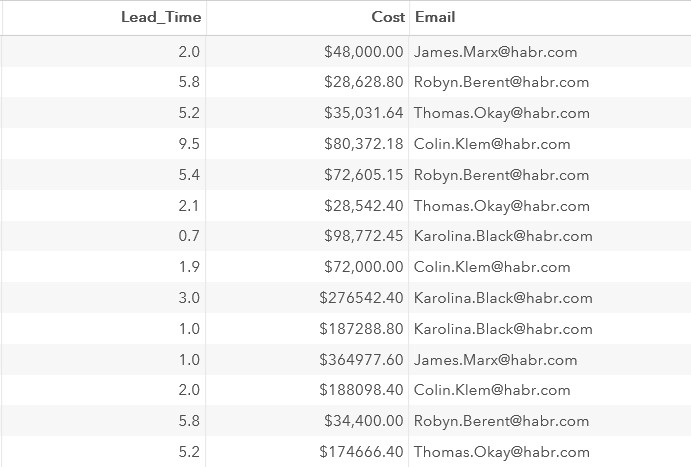
作成されたデータセットの記述子を調べてみましょう。
proc contents data=work.company1 varnum; run;
ハンドルフラグメント:

Email変数の長さに注意してください; 200バイトであり、これはCATS関数によって返されるデフォルトの長さです。 変数Manager_FirstNameおよびManager_LastNameの属性を調べると、Email変数は8 + 6 +文字列の長さ「@ habr.com」、つまり、さらに9バイト、合計23であることがわかります。これに注意する必要があるのはなぜですか。 欠落しているすべての文字はスペースを実現します。スペースはデータセットのサイズに影響し、大量のデータのパフォーマンスに影響します。
Email変数の長さを明示的に設定するには、LENGTH演算子を使用する必要があります。
data company1; set work.company; length Email $23; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com'); format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; run;
フラグメントを処理する
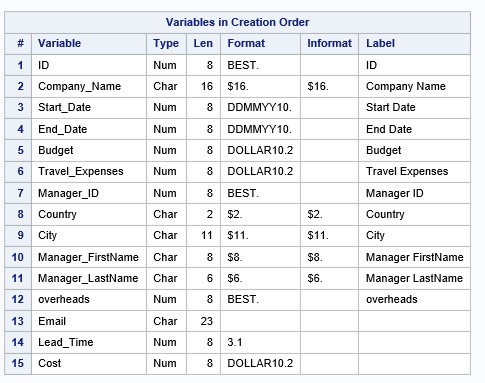
次の条件を考慮して、Lead_Time変数に基づいて詳細な列を作成します。
- Lead_Time変数の値が1未満の場合、[詳細]列の値は1年未満です。
- Lead_Time変数の値が境界を含めて1から2の範囲にある場合、[詳細]列の値は1〜2年です。
- Lead_Time変数の値が2を除く2〜3の範囲にある場合、[詳細]列の値は2〜3年です。
- Lead_Time変数の値が3を除く3〜4の範囲にある場合、[詳細]列の値は3〜4年です。
- Lead_Time変数の値が4を除く4〜5の範囲にある場合、[詳細]列の値は4〜5年です。
- その他の場合はすべて、[詳細]列の値は5年を超えています。
詳細な列はさまざまな方法で作成できます。たとえば、最も単純で最も明白なオプションは条件付き処理を使用することです。 次の演算子を使用して実装できます。
- IF-THEN-ELSE
- その他
- 選択時
大量のデータの場合、最後の2つのオプションを使用する方が効率的です。
data company1; set work.company; length Email $23; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com'); format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; if Lead_Time<1 then detail='less than a year'; else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years'; else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years'; else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years'; else if Lead_Time>4 and Lead_Time<=5 then detail='4-5 years'; else detail='above 5 years'; run;
Detail変数の値が「5年以上」に等しくない観測のみを選択する条件を追加します。 whereをフィルターとして使用すると、構文エラーが発生します。

where句は計算列には使用されません。 必要な変数を選択するには、選択的なIFステートメントが必要です。 作成されたデータセットへの観測の出力をキャンセルします。
data company1; set work.company; length Email $23; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com'); format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; if Lead_Time<1 then detail='less than a year'; else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years'; else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years'; else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years'; else if Lead_Time>4 and Lead_Time<=5 then detail='2-3 years'; else detail='above 5 years'; if detail ne 'above 5 years'; run;
また、選択的IFステートメントには算術演算子が必要です。 たとえば、次のように書くことはできません。
if detail contains 'above 5 years';
ログにエラーが表示されます:

SASデータセットを構成します。
Manager_FirstNameおよびManager_LastName変数は、新しいSASデータセットに存在してはなりません。 この要件はDROPパラメーターを使用して実装され、DROP演算子も使用できます。
data company1 (drop=Manager_FirstName Manager_LastName); set work.company; length Email $23; Lead_Time=yrdif(Start_Date, End_Date, 'actual'); Cost=Budget-Travel_Expenses; Email=cats(Manager_FirstName, '.',Manager_LastName, '@habr.com'); format Cost Travel_Expenses Budget dollar10.2 Lead_Time 3.1; if Lead_Time<1 then detail='less than a year'; else if Lead_Time=>1 and Lead_Time<=2 then detail='1-2 years'; else if Lead_Time>2 and Lead_Time<=3 then detail='2-3 years'; else if Lead_Time>3 and Lead_Time<=4 then detail='3-4 years'; else if Lead_Time>4 and Lead_Time<=5 then detail='2-3 years'; else detail='above 5 years'; if detail ne 'above 5 years'; run;
作成されたSASデータセットを、指定された条件に従って2つに分割します
1つのDATAステップで、複数のSASデータセットを作成できます。 国ごとに個別のデータセットを作成します。
たとえば、Country列の値を確認するには、 PROC FREQプロシージャを使用できます。
proc freq data=company1; table Country /nocum nopercent; run;
この手順では、data =パラメーターで指定されたSASデータセットでCountry変数の特定の値が何回発生するかを考慮します。
この手順の結果は次のようになります。

したがって、OUTPUT演算子と条件付き処理を使用して、1つのDATAステップで2つのデータセットを作成します。
data US AU; set work.company1; if Country='AU' then output AU; if Country='US' then output US; run;
コードを実行して、ログを参照してください。

SASデータセットの読み取りと構成について簡単に説明します。 次の記事では、MERGEおよびSETステートメントを使用してデータセットを結合する方法を紹介します。
PSとして、SAS BASEレッスンの構造を思い出させます。
すでに公開されている記事:
- SAS BASEでのプログラミングの基礎。 レッスン1。
- SAS BASEでのプログラミングの基礎。 レッスン2.データアクセス
- SAS BASEでのプログラミングの基礎。 レッスン3.テキストファイルの読み取り。
- 4番目のレッスンを学習しました。
次の記事では、SAS Baseでテーブルを結合する(マージ、セット)、条件付き処理、ループ、SAS関数、カスタムフォーマットの作成、SASマクロ、PROC SQLなどの問題を強調したいと思います。
 コメントでフィードバックをお待ちしております! 記事で他にどのようなトピックを見たいですか?
コメントでフィードバックをお待ちしております! 記事で他にどのようなトピックを見たいですか?