
視覚的な短編小説のアマチュア翻訳は、他のゲームの翻訳と比較すると、多くの機能を備えており、多くのテキストを操作する必要があります。 おそらく、すべてのビジュアルノベルの大部分は日本語でリリースされ、英語に翻訳されたものはわずか(公式またはアマチュア)であり、他の言語に翻訳されたものはさらに少なかったでしょう。
そのため、翻訳を扱う際には、日本語エンジンに対処する必要がありますが、その多くはローカライザーにあまり馴染みがありません。 このため、翻訳スキル、言語の知識、多くの熱意と自由な時間の存在は、ゲームの翻訳バージョンがまもなく日の目を見ることを意味するものではないことにすぐに気付きます。
非常に大まかに言って、ゲームを翻訳するプロセス(視覚的な短編小説だけでなく)は、
- ゲームリソースの展開(パブリックドメインにない場合)
- 必要な部品の翻訳
- 逆引き梱包
ただし、日本の視覚的な短編小説の場合、これは通常次のようになります。
- ゲームリソースの展開
- ゲームのテキスト部分の翻訳(ゲームスクリプト)
- ゲームのグラフィック部分の翻訳
- 逆引き梱包
- 翻訳されたコンテンツで動作するようにエンジンを変更
私たちの経験が誰かに役立つことを願っています。
2013年(おそらくそれ以前)に、ビジュアル小説「美少女万華鏡-ノロワレシ伝説の少女-(美少女万華鏡-呪われし伝伝の少女-)」を日本語から翻訳することにしました。 私はすでにゲームの翻訳の経験がありましたが、 キリキリのような比較的単純で有名なエンジンで短編を翻訳するだけでした。
ここで、私たちの翻訳者チームは、実際のテキスト自体に到達する前であっても、この短編小説のエンジンを開かなければなりませんでした。
.exeファイルの説明から始めましょう。ここには、QLIEとIMOSURUMEという言葉が記載されています。 ファイル自体には、行FastMM Borland Edition 2004、2005 Pierre le Richeが含まれています。これは、エンジンがDelphiで記述されている可能性が高いことを意味します。


簡単なグーグル検索で、QlieがWarmth Entertainmentがリリースしたビジュアルノベルエンジンの名前であることが明らかになりました。 どうやらIMOSURUMEはスクリプトエンジンの内部名であり、Qlieは商用名です。 このエンジンでリリースされたゲームとWarmth Entertainmentの公式Webサイトをリストするサイトqlie.netがあります。
しかし、パブリックドメインのどこにも、エンジンを操作するための公式ツールも、ドキュメントもありません。
したがって、非公式のユーティリティに依存して、自分でゲームを処理する必要があります。 まず、翻訳が必要なゲームのすべての部分を見つける必要があります。
ゲームアーカイブは、\ GameDataサブフォルダーのdata0.pack、data1.packおよびdata7.packファイルにあります。 スクリーンセーバーは\ GameData \ Movieフォルダーにありますが、そのままにしておくことができます。
16進エディターは、.packゲームアーカイブの認識可能なヘッダーがないことを示しますが、ファイルの最後に目次とラベルFilePackVer3.0に似た部分があります

幸いなことに、この形式には既にアンパッカーがあり、1つでもありません。 asmodeanのコンソールexfp3_v3を使用しました。
開梱は見た目ほど簡単ではありません。 エンジンはいくつかのアーカイブ形式(FilePackVer1.0、FilePackVer1.0、FilePackVer3.0)をサポートしているため、この場合はFilePackVer3.0が使用されます。適切な解凍には、アーカイブを暗号化する特別なキーファイルkey.fkeyも必要です。 \ Dllサブフォルダーにあります
さらに、exfp3_v3は、展開するゲームのアーカイブを明確にする必要があります。
そのため、アンパッカーが提案するリストからゲーム番号を指定する必要があります(美少女万華鏡シリーズのゲームは15番下にあります)、またはアンパッカーの3番目のパラメーターとしてゲーム実行可能ファイルを指定します。

すでにゲームファイルを解凍した後、論理的な考えが浮上しました:将来、どのようにゲームをすぐに翻訳してパックするか? 結局、アンパッカーは逆の操作をサポートしていません。
リクエストに応じて、w8m(ありがとうございます)は、ゲームアーカイブをプログラムarc_conv.exeにパックする機能を追加しました。 変更されたすべてのファイルを新しいアーカイブ(data8.packなど)にパックし、GameDataフォルダーに配置するだけで十分です。自動的にゲームに引き込まれます。
展開されたリソースに戻ります。 data0.packアーカイブのゲームスクリプトファイルは、サブフォルダー\シナリオ\ ks_01 \にあります。
拡張子が.sのすべてのスクリプトファイルは、最も便利なShift Jisエンコーディングとはかけ離れてエンコードされ、エンジンはUnicodeエンコーディングをサポートしていません。 翻訳の行は、ほぼ次のようになります。
【キリエ】 %1_kiri1478% 「へえ……分かっているじゃない」 私が献上したロシアンティーを見て、キリエは嬉しそうに目を細める。 ^cface,,赤目微笑01 【キリエ】 %1_kiri1479% 「日本人は、ジャムを紅茶に入れて飲むのが、ロシアンティーだと勘違いしている人が多いのだけれど……」
日本語の各フレーズの前には、日本語の括弧で囲まれた主人公の名前が付いていることがあります。 (【】)、このフレーズを発音します(ゲームでは、ウィンドウの上部にテキストで表示されます)。 または、これらが著者の言葉である場合、名前は追加されません。

しかし、まだサービスチームがあります。
スクリプト内のエンジンコマンドは、TeXマークアップ言語を連想させますが、 KirikiriまたはRenPyコマンドに比べてはるかに直感的で不便です。
それらのいくつかを次に示します。
@@@
はトリプルドッグです。 多くの場合、スクリプトファイルはこのコマンドで始まります。 サードパーティのファイルから明らかに定義をロードしています。
例:
@@@Library\Avg\header.s
@@
はダブルドッグです。 スクリプトファイルのラベル。 後で切り替えることができます。
%1_kiri1478%
-音声ファイルを再生します。 これらのコマンドは、ヒーローの名前と画面に表示されるテキストの間に挿入されます。 「1_kiri1478」-この場合、data1.packファイルの\ voice \フォルダーのファイル名チームが通常の割合(%)ではなく、日本の割合(%)を使用するのは興味深いことです。
^savedate, ^saveroute, ^savescene,
-ゲームのセーブシステムで使用される可能性が最も高い3つのチームで、セーブゲームでプレイヤーがセーブされた場所と時間に関する情報を入力する必要があります。
例:
^savedate,"現在" ^saveroute,"美少女万華鏡-1-" ^savescene,"呪われし伝説の少女 オープニング"
つまり、日付:現在、支店:美少女万華鏡-1-、シーン:ノロワレシ伝説の少女オープニング。 このデータは保存スロットに表示されるはずでしたが、明らかに開発者はそれを放棄することに決めました。 その結果、
^saveroute
スクリプトのすべての部分で
^saveroute
です。
^savedate
「現在の瞬間」から「夢」への変更を
^savescene
でゲーム内の日数(または夜)を変更します。
^facewindow,
-テキストが画面に表示されているテキストボックスの状態。 (表示-1かどうか-0)
^sload,
-対応するチャンネルの\ sound \フォルダからゲーム内のサウンドを再生します。
sload,Env1,◆セミ01アブラゼミ
Env1でセミを再生する
チームには2つのオプションパラメータがあり、1つ目はサウンドのループを担当し、2つ目は謎のままですが、ゲームではほとんど使用されません。
^sload,SE1,■クチュ音01,1
チャンネルSE1でループバックサウンドを再生します。
^eeffect
特定の秒数の間、画面に特殊効果を表示します。 どうやら、それはいくつかの効果の順次出力をサポートしています。
^eeffect,WhiteFlash
白い閃光の効果。
^ffade
画面を変更したときのトランジション効果。
たくさんの追加パラメーターがありますが、実際に役立つのはほんのわずかです:トランジション効果の名前、必要に応じて追加の画像、トランジション完了時間。
^ffade,Overlap,,1000
1秒で1つの画像を別の画像に分解します。
^iload
画面に背景画像をロードします。 イメージには、将来参照するためのIDを割り当てることができます。
^iload,BG1,0_black.png
出力ファイル0_black.pngをID BG1の背景として
^we
と
^wd
ウィンドウ内の画像のオンとオフを
^wd
ます。
^facewindow,1
および
^facewindow,0
ダイアログボックスでヒーロー画像のオンとオフを
^facewindow,0
ます。
^mload
特定のチャンネルで音楽を再生します。
^mload,BGM1,nbgm13
チャンネルBGM1でトラックnbgm13を再生する
最も重要なチームの一部:
\jmp
指定された名前のラベルにジャンプします。
^select
プレイヤーがオプションのいずれかを選択する必要がある選択ウィンドウを画面に表示します。
例:
^select, , \jmp,"@@route01a"+ResultBtnInt[0] @@route01a0
ここでは、質問への回答後に遷移が実行され、回答番号(0または1)がResultBtnInt [0]から返されます。 その結果、
\jmp
ストーリーをラベル@@ route01a + response numberに移動します。 つまり、@@ route01a0または@@ route01a1
不快な機能は、これらのコマンドの通常のコンマが区切り文字として機能し、回答オプション自体で使用できないことです。 日本人はそのような問題はありません、彼らは日本語のコンマ(、)を使用します。 この場合、カンマを「(U + 201A SINGLE LOW-9 QUOTATION MARK)」に置き換えることができます。
例:
^select, ‚ , ‚
残りのチームは、最初の近似ではそれほど重要ではありません。
もちろん、スクリプトを翻訳する前に、キリル文字と日本語の文字を結合するために、より便利なもの、たとえばUTF-8に変換する必要があります。
エンジンを変更すると(この次の部分について)、ゲームはロシア語のテキストと日本語の両方を認識します。 ただし、現時点では、互換性のために、Shift Jisで日本語文字をエンコードし、cp1251エンコードでキリル文字をエンコードする必要があります。
キリル文字を考慮してトランスコードするためのPythonのプログラムをすばやくスケッチしました。
UTF8からcp1251およびShiftJIS
# -*- coding: utf-8 -*- # UTF8 to cp1251 and ShiftJIS recoder # by Chtobi and Nazon, 2016 import codecs import argparse from os import path JAPANESE_CODEPAGE = 'shift_jis' UTF_CODEPAGE = 'utf-8' RUS_CODEPAGE = 'cp1251' def nonrus_handler(e): if e.object[e.start:e.end] == '~': # UTF-8: 0xEFBD9E -> SHIFT-JIS: 0x8160 japstr_byte = b'\x81\x60' elif e.object[e.start:e.end] == '-': # UTF-8: 0xEFBC8D -> SHIFT-JIS: 0x817C japstr_byte = b'\x81\x7c' else: japstr_byte = (e.object[e.start:e.end]).encode(JAPANESE_CODEPAGE) return japstr_byte, e.end if __name__ == '__main__': arg_parser = argparse.ArgumentParser(prog="Recode to cp1251 and ShiftJIS", description="Program to encode UTF8 text file to " "cp1251 for all cyrillic symbols and ShiftJIS for others. " "Output file will be inputfilename.s", usage="recode_to_cp1251_shiftjis.py file_name") arg_parser.add_argument('file_name', nargs=1, type=argparse.FileType(mode='r', bufsize=-1), help="Input text file name. Only files coded in UTF8 are allowed.\n") codecs.register_error('nonrus_handler', nonrus_handler) input_name = arg_parser.parse_args().file_name[0].name output_name = path.splitext(input_name)[0] + ".s" with open(input_name, 'rt', encoding=UTF_CODEPAGE) as input_file: with open(output_name, 'wb') as output_file: for line in input_file: for char1 in line: bytes_out = bytes(line, UTF_CODEPAGE) output_file.write(char1.encode(RUS_CODEPAGE, "nonrus_handler")) print("Done.")
しかし、いくつかの問題がありました。 プログラムは、「チルダ」記号〜(U + FF5E FULLWIDTH TILDE)を再コーディングしようとすると、エラー「UnicodeEncodeError: 'Shift Jis' codec ca n't encoding character '\ uff5e' in position 0:illegal multibyte sequence」を生成しました
最初はPythonに対して罪を犯しましたが、最終的にはかなり珍しいニュアンスを見つけました。 特定の実装に応じて、ユニコードと非ユニコードの日本語エンコーディングの相関方法には不確実性があります。
その結果、Windowsはコード0x8160のShift Jis文字をユニコード〜(U + FF5E FULLWIDTH TILDE)に関連付け、他のトランスコーダー(たとえばiconvユーティリティ)は、公式のUnicode比率表に従って、同じ文字を〜(U + 301C WAVE DASH)と関連付けます-ftp://ftp.unicode.org/Public/MAPPINGS/OBSOLETE/EASTASIA/JIS/SHIFT JIS.TXT
文字間の対応を決定するために、マイクロソフトは明らかに、Shift Jisの拡張バージョンであるcp932エンコーディングのスキームを使用することを決定しました。
同じ状況は、Windowsでは-(U + FF0D FULLWIDTH HYPHEN-MINUS)、またはiconvでは-(U + 2212 MINUS SIGN)としてUTF8に変換される文字コード0x817Cでも発生します。
すべてのスクリプトファイルは最初にNotepad ++を使用してShift JisからUTF8に変換されたため(Windowsで採用された対応表を使用)、Pythonプログラムを介してUTF8からShift Jisに変換すると、悪名高い変換エラーが発生しました。
そのため、〜と-の別々の条件の発生を考慮する必要がありました。
その他の小さな欠陥がありました。たとえば、省略記号(U + 2026水平楕円)は、Shift Jisの日本人ではなく、cp1251のキリル語の省略記号に置き換えられました。
テキストを翻訳した後、ゲームグラフィックスの作業に進むことができます。
ゲームのグラフィックファイルは同じパックアーカイブ内にありますが、展開後も引き続き一生懸命作業する必要があります。 たとえば、ほぼすべてのpng画像は、sample + DPNG000 + x32y0.pngタイプのファイルの形式で解凍されます。つまり、png画像は88 cmの厚さの水平ストリップに切り分けられ、各ストリップは個別のファイルに書き込まれます。 ファイル名には、ストリップのシリアル番号(DPNG000 ... 009)とx、y座標が表示されます。

なぜこれが必要なのか、まだ疑問に思っています。 ゲームからリソースをリッピングするのが難しい場合、これは明らかに最善の方法ではありません。
カットされたpngファイルを接着するために、一度にImageMagickを使用するasmodeusのPearlに小さなスクリプトmerge_dpngが作成されました。 残念ながら、彼には問題がありました。 まず、私は使用しなかったPearlが必要でした。インストールした後でも、スクリプトが正しく機能していないことがわかりました。
このため、Pythonで同様のプログラムを作成しました。
Qlieエンジンのdpngファイルのマージ
# -*- coding: utf-8 -*- # Qlie engine dpng files merger # by Chtobi and Nazon, 2016 # Requires ImageMagick magick.exe on the path. import os import glob import re import argparse import subprocess IMGMAGIC = os.path.dirname(os.path.abspath(__file__)) + '\\' + 'magick.exe' IMGMAGIC_PARAMS1 = ['-background', 'rgba(0,0,0,0)'] IMGMAGIC_PARAMS2 = ['-mosaic'] INPUT_FILES_MASK = '*+DPNG[0-9][0-9][0-9]+*.png' SPLIT_MASK = '+DPNG' x_y_ajusts_re = re.compile('(.+)\+DPNG[0-9][0-9][0-9]\+x(\d+)y(\d+)\.') if __name__ == '__main__': arg_parser = argparse.ArgumentParser(prog="DPNG Merger\n" "Program to merge sliced png files from QLIE engine. " "All files with mask *+DPNG[0-9][0-9][0-9]+*.png" "into the input directory will be merged and copied to the" "output directory.\n", usage="connect_png.py input_dir [output_dir]\n") arg_parser.add_argument("input_dir_param", nargs=1, help="Full path to the input directory.\n") arg_parser.add_argument("output_dir_param", nargs='?', default=os.path.dirname(os.path.abspath(__file__)), help="Full path to the output directory. " "It would be a script parent directory if not specified.\n") input_dir = arg_parser.parse_args().input_dir_param[0] output_dir = arg_parser.parse_args().output_dir_param[0] os.chdir(input_dir) all_append_files = glob.glob(INPUT_FILES_MASK) # Select only files with DPNG prep_bunches = [] for file_in_dir in all_append_files: # Check all files and put all splices that should be connected in separate list for num, bunch in enumerate(prep_bunches): name_first_part = bunch[0].partition(SPLIT_MASK)[0] # Part of the filename before +DPNG should be unique if name_first_part == file_in_dir.partition(SPLIT_MASK)[0]: prep_bunches[num].append(file_in_dir) break else: prep_bunches.append([file_in_dir]) os.chdir(os.path.dirname(os.path.abspath(__file__))) # Go to the script parent dir for prepared_bunch in prep_bunches: sorted_bunch = sorted(prepared_bunch) # Prepare -page params for imgmagic png_pages_params = [["(", "-page", "+{0}+{1}".format(*[(x_y_ajusts_re.match(part_file).group(2)), x_y_ajusts_re.match(part_file).group(3)]), input_dir+part_file, ")"] for part_file in sorted_bunch] connect_png_list = \ [imgmagick_page for imgmagick_pages in png_pages_params for imgmagick_page in imgmagick_pages] output_file = output_dir + sorted_bunch[0].partition(SPLIT_MASK)[0] + ".png" subprocess.check_output([IMGMAGIC] + IMGMAGIC_PARAMS1 + connect_png_list + IMGMAGIC_PARAMS2 + [output_file])
ゲームに表示される一連の写真がすべて揃ったように見えますか? すべてではありません-すべてのアーカイブから接続されたすべての写真を見ると、ゲーム内にあるにもかかわらず、一部が欠落していることがわかります。 実際、エンジンには別の種類のファイルがあり、拡張子は.bです。 画像と音声が内部に記録されたアニメーションです。
リソースを内部に保存するのは非常に簡単ですが、残念ながら、この場合の既製の.bファイルのアンパッカーは、うまく機能していませんでした。 いくつかのファイルが解凍されたままであるか、日本語名によるエラーがありましたが、日本語ロケールから起動したくありませんでした。
もう1つのスクリプトが役に立ちました。 それ以来、 Kaitai Structのようなものに慣れていませんでした。ほとんどゼロから行動しなければなりませんでした。
.bファイル形式はシンプルであることが判明し、さらに、このゲームからのみリソースをアンパックできるようにするために、アンパッカーが必要でした。 Qlieエンジン上の他のゲームでは、追加の種類のリソースが.bファイル内に現れましたが、それらについては詳しく説明しません。
そのため、16進エディターで.bファイルを開き、先頭を確認します。 評価する前に、すべての数値のバイト順がリトルエンディアンになることに注意してください。
- Abmp12ファイルヘッダー
- 10バイト0x00
- オーバーヘッド情報を含む最初のセクションabdata12のタイトル。
- 8バイト0x00
- セクションサイズabdata12、4バイト整数。 安全にスキップできます。
- Abimage10セクションヘッダー
- 7バイト0x00
- セクション内のファイルの数、1バイトの整数。 この場合、セクションには1つのファイルがあります。
- セクションヘッダーabgimgdat13
- 6バイト0x00
- セクション内のファイル名の長さ、2バイト整数。 この場合、長さは4バイトです。
- シフトJISエンコードファイル名
- ファイルのチェックサムレコード長、2バイト整数。
- ファイル自体のチェックサム。
- 不明なバイトは常に0x03または0x02のようです
- おそらくアニメーションに関連する12個の不明なバイト
- セクション内のpngファイルのサイズは4バイトの整数です。
そして最後に、pngファイル自体。
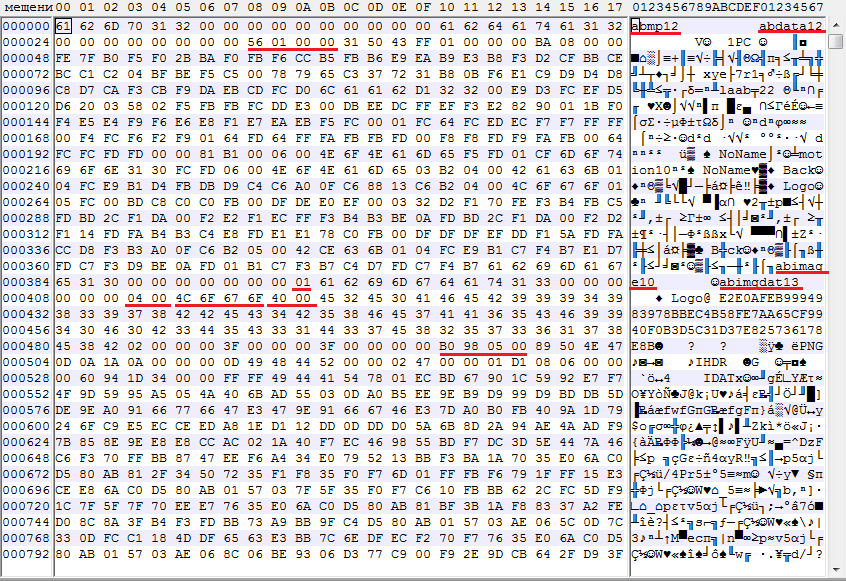
アブサウンドセクションの構造はアブイメージに似ています。
AnimatedBMPエクストラクター
# -*- coding: utf-8 -*- # Extract b # AnimatedBMP extractor for Bishoujo Mangekyou game files # by Chtobi and Nazon, 2016 import glob import os import struct import argparse from collections import namedtuple b_hdr = b'abmp12'+bytes(10) signa_len = 16 b_abdata = (b'abdata10'+bytes(8), b'abdata11'+bytes(8), b'abdata12'+bytes(8), b'abdata13'+bytes(8)) b_imgdat = (b'abimgdat10'+bytes(6), b'abimgdat11'+bytes(6), b'abimgdat14'+bytes(6)) b_img = (b'abimage10'+bytes(7), b'abimage11'+bytes(7), b'abimage12'+bytes(7), b'abimage13'+bytes(7), b'abimage14'+bytes(7)) b_sound = (b'absound10'+bytes(7), b'absound11'+bytes(7), b'absound12'+bytes(7)) # not sure about structure of sound11 and sound12 b_snd = (b'absnddat11'+bytes(7), b'absnddat10'+bytes(7), b'absnddat12'+bytes(7)) Abimgdat13_pattern = namedtuple('Abimgdat13', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'unknown2_len', 'data_size_len']) Abimgdat13 = Abimgdat13_pattern(signa=b'abimgdat13'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=1, unknown2_len=12, data_size_len=4) Abimgdat14_pattern = namedtuple('Abimgdat14', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) Abimgdat14 = Abimgdat14_pattern(signa=b'abimgdat14'+bytes(6), name_size_len=2, hash_size_len=2, unknown1_len=77, data_size_len=4) Abimgdat_pattern = namedtuple('Abimgdat', ['name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) # probably, abimgdat10,abimgdat11 and others Other_imgdat = Abimgdat_pattern(name_size_len=2, hash_size_len=2, unknown1_len=1, data_size_len=4) Absnddat11_pattern = namedtuple('Absnddat11', ['signa', 'name_size_len', 'hash_size_len', 'unknown1_len', 'data_size_len']) Absnddat11 = Absnddat11_pattern(signa=b'absnddat11'+bytes(7), name_size_len=2, hash_size_len=2, unknown1_len=1, data_size_len=4) def create_parser(): arg_parser = argparse.ArgumentParser(prog='AnimatedBMP extractor\n', usage='extract_b input_file_name output_dir\n', description='AnimatedBMP extractor for QLIE engine *.b files.\n') arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n") arg_parser.add_argument('output_dir', nargs=1, help="Output directory.\n") return arg_parser def check_type(file_buf): if file_buf.startswith(b'\x89' + b'PNG'): return '.png' elif file_buf.startswith(b'BM'): return '.bmp' elif file_buf.startswith(b'JFIF', 6): return '.jpg' elif file_buf.startswith(b'IMOAVI'): return '.imoavi' elif file_buf.startswith(b'OggS'): return '.ogg' elif file_buf.startswith(b'RIFF'): return '.wav' else: return '' def bytes_shiftjis_to_utf8(shiftjis_bytes): shiftjis_str = shiftjis_bytes.decode('shift_jis', 'strict') utf_str = shiftjis_str.encode('utf-8', 'strict').decode('utf-8', 'strict') return utf_str def check_signa(f_buffer): if f_buffer.endswith(b_abdata): return 'abdata' elif f_buffer.endswith(b_img): return 'abimgdat' elif f_buffer.endswith(b_sound): return 'absound' def prepare_filename(out_file_name, out_dir, postfix=''): ready_name = out_dir + os.path.basename(out_file_name) + postfix return ready_name def create_file(file_name_hndl, out_buffer): if len(out_buffer) != 0: with open(file_name_hndl, 'wb') as ext_file: ext_file.write(out_buffer) else: print("Zero file. Skipped.") def check_file_header(file_handle, bytes_num): file_handle.seek(0) readed_bytes = file_handle.read(bytes_num) if readed_bytes == b_hdr: print("File is valid abmp") return True else: print("Can't read header. Probably, wrong file...") return False if __name__ == '__main__': parser = create_parser() arguments = parser.parse_args() all_b_files = glob.glob(arguments.input_file_name[0]) output_dir = arguments.output_dir[0] for b_file in all_b_files: file_buffer = bytearray(b'') with open(b_file, 'rb') as bfile_h: check_file_header(bfile_h, len(b_hdr)) read_byte = bfile_h.read(1) file_buffer.extend(read_byte) while read_byte: read_byte = bfile_h.read(1) file_buffer.extend(read_byte) # Finding content sections signature check_result = check_signa(file_buffer) if check_result: if check_result == 'abdata': file_buffer = bytearray(b'') read_length = bfile_h.read(4) size = struct.unpack('<L', read_length)[0] file_buffer.extend(bfile_h.read(size)) # Adding _abdata to separate from other parts outfile_name = prepare_filename(b_file, output_dir, '_abdata') create_file(outfile_name, file_buffer) elif check_result == 'abimgdat': images_number = struct.unpack('B', bfile_h.read(1))[0] # Number of pictures in section for i1 in range(images_number): file_buffer = bytearray(b'') file_name = '' imgsec_hdr = bfile_h.read(signa_len) if imgsec_hdr == Abimgdat13.signa: file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat13.name_size_len))[0] # Decode filename to utf8 file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) # CRC size hash_size = struct.unpack('<H', bfile_h.read(Abimgdat13.hash_size_len))[0] # Picture CRC (don't need it) pic_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Abimgdat13.unknown1_len) unknown2 = bfile_h.read(Abimgdat13.unknown2_len) pic_size = struct.unpack('<L', bfile_h.read(Abimgdat13.data_size_len))[0] print("pic_size:", pic_size) file_buffer.extend(bfile_h.read(pic_size)) elif imgsec_hdr == Abimgdat14.signa: file_name_size = struct.unpack('<H', bfile_h.read(Abimgdat14.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Abimgdat14.hash_size_len))[0] pic_hash = bfile_h.read(hash_size) bfile_h.seek(Abimgdat14.unknown1_len, os.SEEK_CUR) pic_size = struct.unpack('<L', bfile_h.read(Abimgdat14.data_size_len))[0] file_buffer.extend(bfile_h.read(pic_size)) else: # probably abimgdat10, abimgdat11... file_name_size = struct.unpack('<H', bfile_h.read(Other_imgdat.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Other_imgdat.hash_size_len))[0] pic_hash = bfile_h.read(hash_size) bfile_h.seek(Other_imgdat.unknown1_len, os.SEEK_CUR) pic_size = struct.unpack('<L', bfile_h.read(Other_imgdat.data_size_len))[0] file_buffer.extend(bfile_h.read(pic_size)) for i, letter in enumerate(file_name): # Replace any unusable symbols from filename with _ if letter == '<' or letter == '>' or letter == '*' or letter == '/': file_name = file_name.replace(letter, "_") # Checking file signature and adding proper extension outfile_name = prepare_filename(b_file, output_dir, '_' + file_name + check_type(file_buffer)) create_file(outfile_name, file_buffer) file_buffer = bytearray(b'') elif check_result == 'absound': sound_files_number = struct.unpack('B', bfile_h.read(1))[0] for i2 in range(sound_files_number): file_buffer = bytearray(b'') file_name = '' sndsec_hdr = bfile_h.read(signa_len) if sndsec_hdr == Absnddat11.signa: file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0] snd_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Absnddat11.unknown1_len) snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0] file_buffer.extend(bfile_h.read(snd_size)) else: file_name_size = struct.unpack('<H', bfile_h.read(Absnddat11.name_size_len))[0] file_name = bytes_shiftjis_to_utf8(bfile_h.read(file_name_size)) hash_size = struct.unpack('<H', bfile_h.read(Absnddat11.hash_size_len))[0] snd_hash = bfile_h.read(hash_size) unknown1 = bfile_h.read(Absnddat11.unknown1_len) snd_size = struct.unpack('<L', bfile_h.read(Absnddat11.data_size_len))[0] file_buffer.extend(bfile_h.read(snd_size)) for i, letter in enumerate(file_name): if letter == '<' or letter == '>' or letter == '*' or letter == '/': file_name[i] = '_' outfile_name = prepare_filename(b_file, output_dir, '_' + file_name + check_type(file_buffer)) print("create absound") create_file(outfile_name, file_buffer) file_buffer = bytearray(b'')
スクリプトは、見つかったpng、jpg、bmp、ogg、wavファイルを自動的に解凍します。 しかし、これに加えて、未知のimoaviファイルも内部にあります。
要するに、ゲームでは、すべてのアニメーションはogv形式の本格的なビデオとして、または.bファイルに記録されるエンジンアニメーション画像として、またはimoavi形式のjpgファイルのアニメーションシーケンスとして作成されます。
この場合、私たちはjpg画像にも興味があったので、それらにも対処しなければなりませんでした。
imoaviには、SOUNDとMOVIEの2つのセクションがあります。 ヘッダーの後の47バイトのMOVIEセクションには、4バイトのjpgファイルサイズがあります。 ファイルは、19バイトのシーケンスで区切られた元の形式で次々に書き込まれ、次のファイルのサイズが記録されます。
ゲーム内の有声のimoaviは出会わなかったため、SOUNDセクションは常に空です。
ゲームのすべてのリソースを引き出し始めたので、同時にimoaviからjpgを引き出すための小さなスクリプトが作成されました。
イモアビ抽出器
# -*- coding: utf-8 -*- # Extract imoavi # Imoavi extractor for Bishoujo Mangekyou game files # by Chtobi and Nazon, 2016 import glob import os import struct import argparse imoavi_hdr = b'IMOAVI' hdr_len = len(imoavi_hdr) def create_file(file_name, out_buffer, wr_mode='wb'): if len(out_buffer) != 0: with open(file_name, wr_mode) as ext_file: ext_file.write(out_buffer) else: print("Zero file. Skipped.") def prepare_filename(file_name, out_dir, postfix=''): ready_name = out_dir + os.path.basename(file_name) + postfix return ready_name def create_parser(): arg_parser = argparse.ArgumentParser(prog='Imoavi extractor\n', usage='extract_imoavi input_file_name output_dir\n', description='Imoavi extractor for QLIE engine *.imoavi files.\n') arg_parser.add_argument('input_file_name', nargs='+', help="Input file with full path(wildcards are supported).\n") arg_parser.add_argument('output_dir', nargs='+', help="Output directory.\n") return arg_parser if __name__ == '__main__': parser = create_parser() arguments = parser.parse_args() all_imoavi = glob.glob(arguments.input_file_name[0]) output_dir = arguments.output_dir[0] for imoavi_f in all_imoavi: file_buffer = bytearray(b'') with open(imoavi_f, 'rb') as imoavi_h: # Read imoavi file header imoavi_h.read(hdr_len) imoavi_h.seek(2, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(3, os.SEEK_CUR) # 0x00 imoavi_h.seek(5, os.SEEK_CUR) # SOUND imoavi_h.seek(3, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(11, os.SEEK_CUR) imoavi_h.seek(5, os.SEEK_CUR) # Movie imoavi_h.seek(3, os.SEEK_CUR) # 00 ?? imoavi_h.seek(1, os.SEEK_CUR) # 0x64 imoavi_h.seek(3, os.SEEK_CUR) # 0x00 ?? imoavi_h.seek(4, os.SEEK_CUR) # ?? imoavi_h.seek(1, os.SEEK_CUR) # Number of jpg files in section imoavi_h.seek(4, os.SEEK_CUR) # 0x00 imoavi_h.seek(1, os.SEEK_CUR) # 0x05 ??? imoavi_h.seek(2, os.SEEK_CUR) # 0x00 ?? imoavi_h.seek(4, os.SEEK_CUR) # 720 ?? imoavi_h.seek(4, os.SEEK_CUR) # Full size without header? to_next_size = struct.unpack('<L', imoavi_h.read(4))[0] # Bytes till next header imoavi_h.seek(16, os.SEEK_CUR) # 0x00 jpg_size = struct.unpack('<L', imoavi_h.read(4))[0] imoavi_h.seek(4, os.SEEK_CUR) # 0x00 file_num = 0 file_buffer.extend(imoavi_h.read(jpg_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg') create_file(outfile_name, file_buffer) while to_next_size != 0: file_buffer = bytearray(b'') to_next_size = struct.unpack('<L', imoavi_h.read(4))[0] if to_next_size == 24: # 0x1C header for index part file_buffer.extend(imoavi_h.read(to_next_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + '.index') create_file(outfile_name, file_buffer, 'ab') # concatenate with index file else: imoavi_h.seek(2, os.SEEK_CUR) # unknown imoavi_h.seek(2, os.SEEK_CUR) # Unknown, almost always FF FF or FF FE file_num = struct.unpack('B', imoavi_h.read(1))[0] # File number imoavi_h.seek(11, os.SEEK_CUR) # 0x00 jpg_size = struct.unpack('<L', imoavi_h.read(4))[0] imoavi_h.seek(4, os.SEEK_CUR) # 0x00 file_buffer.extend(imoavi_h.read(jpg_size)) outfile_name = prepare_filename(imoavi_f, output_dir, '_' + (str(file_num)).zfill(3) + '.jpg') create_file(outfile_name, file_buffer)
解凍後、メニューのスプラッシュ画面からのアニメーションがimoavi形式のファイル1_タイトル画面ムービー.bに保存されていることを確認できます。
それはすべてゲームリソースにあります。
残念ながら、翻訳プロセスでは克服できないいくつかの不快なニュアンスが明らかになりました。すでに書いたように、このゲームはUnicodeエンコードをサポートしていません。したがって、翻訳されたテキストはすべて、間違った文字間隔で表示されます。システムエンコーディングを日本語に変更せずにファイルをバックパックし、ゲームを開始すると、さらにいくつかの問題が発生しました。
ある時点で、私たち(または、チームの翻訳の技術的な部分を担当した人)は考えました:おそらく、古いエンジンをいじるのではなく、クロスプラットフォームを取得しながら、Renpyエンジンにストーリーを移植するべきでしょうか?
おそらく私たちは急いでいたのでしょうが、ある時点で、私たちが始めたものをやめるのは残念であり、翻訳を終える以外に何も残されていませんでした。
移植中に何に遭遇しましたか?
第二部でこれについて。
参照:
Bitbucketスクリプト
日本語Qlieエンジンについて
Shift Jis エンコードテーブルShift Jis
からUTF-8への変換問題について詳しく読む
asmodean exfp3_v3ユーティリティ